






1.支持向量机原理解析
机器学习本质上就是一种对所研究问题真实模型的逼近,通常会假设一个近似模型,然后根据适当的原理将这个近似模型不断逼近真实模型.结构风险就是指近似模型与真实模型之间的差距.
我们可以用某些方法来逼近真实模型,最直观的想法就是使用分类器在样本数据上的分类结果与真实结果之间的差值来表示,这个差值统计上为经验风险Remp(W).
在过去的机器学习方法中,通常将经验风险最小化作为努力目标,但是由于过度拟合,而使得模型无推广能力.统计学因而引进了泛化误差界的概念.所谓泛化误差界是指真实风险应该由两部分内容刻画:一是经验风险,代表了分类器在给定样本上的误差;二是置信风险,代表了我们在多大程度上可以信任分类器在未知样本上分类的结果.统计学习的目标就是从经验风险最小化变为了寻求经验风险与置信风险之和最小化,即结构风险最小化(Structural Risk Minimization).支持向量机就是努力寻求最小化结构风险的算法.
我们可以把支持向量机理解为高级的线性回归或线性判别。 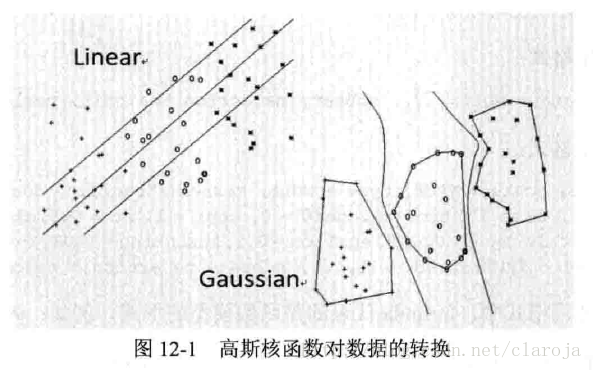
2.在R语言中的应用
支持向量机算法我们主要用到了R语言e1071包里面的svm(formula,data,type,kernel,degree,gamma,coef,nu)函数
type取值有C-classification/nu-classification/one-classification/eps-regression/nu-regression.前三种是针对字符型结果变量的分类方式,其中第三种是逻辑判别,即输出结果是是否属于该类别,后两种则是针对数量型结果变量的分类方式.
kernel有四个参数,线性核函数linear/多项式核函数ploynomial/径向基核函数(高斯函数)radial basis/神经网络核函数sigmoid.经研究发现,识别率最高/性能最好的是高斯函数,其次是多项式函数,而最差的是神经网络函数.高斯函数是局部函数,学习能力强,但泛化能力弱;多项式函数则是全局性函数。
3.以iris数据集为例进行支持向量机判别分析
1)应用模型并观察结果
fit_svm=svm(Species~.,data=iris)
fit_svm[1:length(fit_svm)] 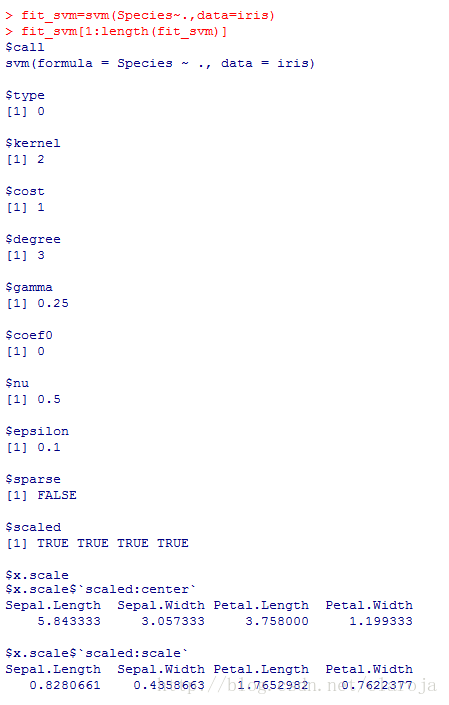
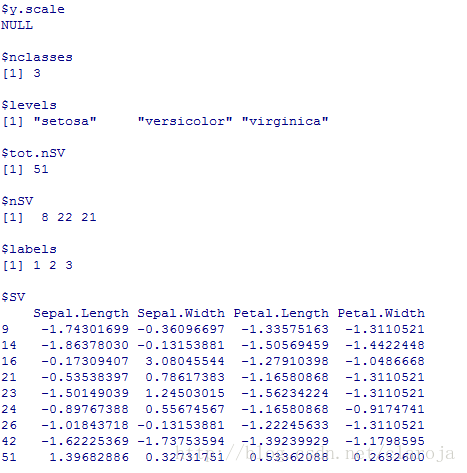

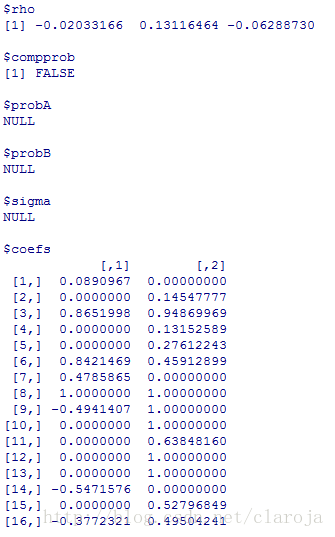



2)进行预测和模型评测 
转载于:https://my.oschina.net/u/3473376/blog/895285















 369
369

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









