







许多计算机系统记录现实世界中各种对象的信息,这些信息通常表现为计算机系统中的记录、属性、对象等其他各种各样的形式。最典型的方式是把某项信息记录成某个对象的一个属性,例如,一个人体重70公斤记录成“人(Person)”类的体重(Weight)属性,值为70。本章将讲述这种方式的不足,并提出一些更合理的解决方法。
本章的模式来自与医疗领域有关的项目,所以采用了许多这一领域的例子。
本章中的模式图均由笔者以通用的UML格式重画。
1.1 数量(Quantity)
当用上面提到的方法记录数据时,最常见的不足之处就是单纯的数字不足以代表它的意义,是70公斤,70磅,或者别的什么?我们需要确切的单位。可不可以创建属性和个单位之间的关联?可以,但那样系统中将会出现错综复杂的关联,从而增加了系统的复杂度。
如果改用一个Quantity类来表达,这样的意义将会更简单。如下图所示,Quantity类包括一个amount属性,记录数值,一个units属性,记录单位,并支持一般的运算操作。

1.2 转换比率(Conversion Ratio)
这个模式主要是解决不同的单位间转换的问题,通过需要转换的不同单位,以及它们之间的比率,就可以实现各种固定比率的单位转换,这在系统中也是相当有用的。
但它也有不足的地方,如果转换比率不固定,可能需要额外的计算函数。对于一般情况来说这个模式已经足够了。
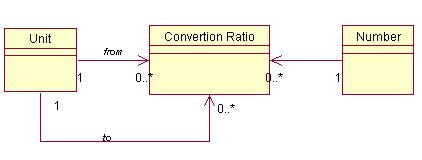
1.3 复合单位(Compound Unit)
单位可以是复合的也可以是不可再分解的(基本单位),如何来表达复合单位?请看下面两个模型:
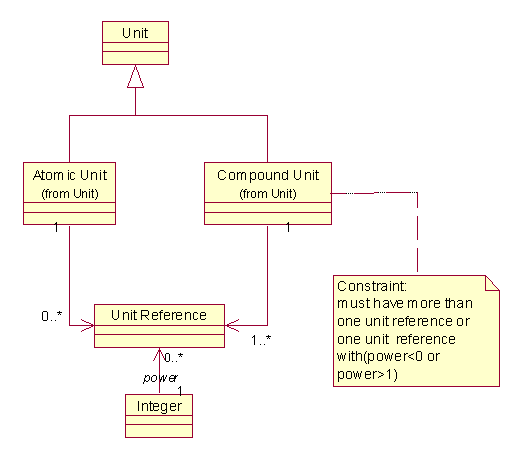
在这个模型中,复合单位(Compound Unit)通过单位引用(Unit Reference)来记录基本单位(Atomic Unit)和它们的幂(power)。这是一个较直接的模型。
下面这种模型由于使用了bags,从而显得更紧凑:

这两种模型差别不大,只是一个采用了bag,而另一个用了Unit Reference,至于在什么时候采用这样的模型,要不要引入复合单位,则完全取决于客户和应用的需要。
1.4 测量模式(Mesurement)
当一个复杂的系统中包括成千上万的测量活动,需要记录那些测量数据时,光靠数量模型是不够的。如果还是把测量数据当作属性来处理,系统中可能充斥着杂乱无章的属性,从而导致一些非常复杂的界面(Interface)。这里的解决方案是把各个测量项目(例如医院需要的身高、体重、血压、血糖浓度等)当作对象,并把对象的类型引申成“现象类型(Phenomenon Type)”,这个时候,问题的复杂度就转移到各种各样的Phenomenon Type,以及各个测量(Mesurement)实例。
如下图模型所示,测量(Mesurement)实例已经包括了类型(Phenomenon Type),测量对象(Person),结果(Quantity)。依照我们上一章提到的知识层和操作层分离的思想,可以把现象类型(Phenomenon Type)划分到知识(knowledge)层,因为这些对象表示了千千万万要进行的测量项目,这部分信息是相对不变的。
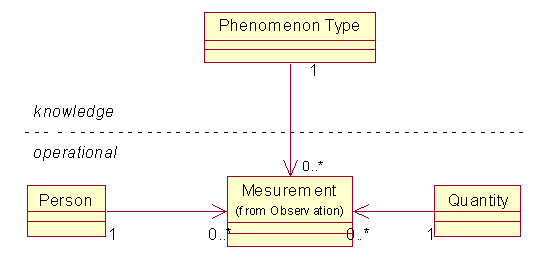
也可以将单位信息跟类型(Phenomenon Type)关联,而测量实例中只保存单纯的数值,但是为了对类型(Phenomenon Type)进行多单位的支持,我们还是倾向于采用上图的模型。
1.5 观察模式(Observation)
由于进行测量时除了要记录许多测量项目具体的数值,例如身高,体重,血糖浓度等之外,还有一种测量项目只需记录条目类别,例如血型,常见的有A,B,O,AB四种,又例如体形又可以记录为肥胖,正常,偏瘦等类别,所以我们有必要在上述的模型补充种类(Category),从而正式形成观察(Observation)模式:
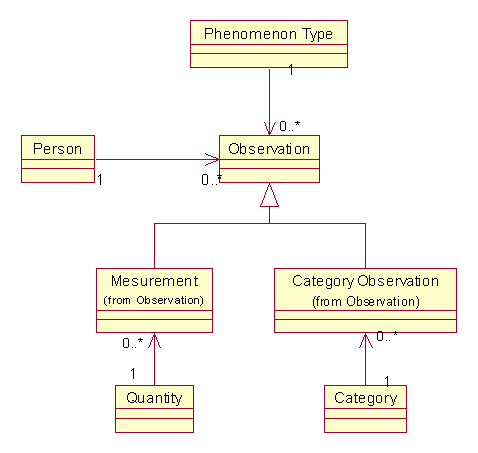
在这里,种类(Category)最好和现象类型保持较为简单的关系,可以减少歧义,降低复杂性。在下面的图中,Category被改名为Phenomenon,并被移动到知识层,由Phenomenon来定义某些Phenomenon Type的一组可能的取值。
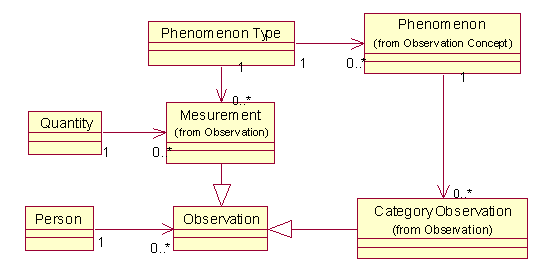
对于观察(Observation),还要提到的是,在实际的诊断过程中,医生需要根据某些现象来推断某些测量活动,而这些测量活动又为其他的测量记录提供证据,所以可能还存在以下的关系:
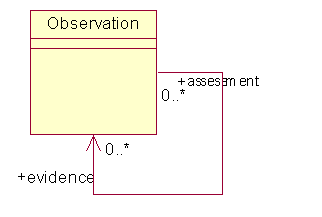
1.6 对Observation的完善
在以上的图中,还遗漏了一种可能的情况,那就是对于有的记录项目,结果可能就是简单的“有/存在(Presence)”或“没有/不存在(Absense)”,例如针对各种疾病而言,某个人或许有糖尿病,或许没有。这就是Category Observation出现两个子类Absence和Presence的原因。
在这里,为Phenomenon增加了一个父类Observation Concept,这是为了在处理例如疾病的时候它们可以不必跟Phenomenon Type相关联。
还有,可以看到,在Observation Concept上加入了一个名为SuperType的自关联,是因为各类疾病可能互相存在关系,其中的一种关系是上下级的关系,例如糖尿病和A类糖尿病,B类糖尿病;如果存在A类糖尿病,那么一定存在它的上级;如果A不存在,并不能表示上级存在与否。

1.7 协议(Protocol)
在上图中,Protocol是一个重要的知识层概念,表示进行观察时采用的方式。例如我们量体温的时候体温计可以放在腋下或含在口中,某些时候,很有必要记录这些不同的方式。而且,可以根据不同的观察方法判断结果的精确度和灵敏性。
把这部分信息单独放在Protocol中,简明而易于处理。
1.8 双时间记录(Dual Time Record)
Observation经常有一个有限的有效时间,在下面的图中,Observation跟两个时间(TimeRecord)有关,一个表示记录时间,另一个是发生时间,Time Record可以同时表示时间点和时间段,这可以由它的子类体现。
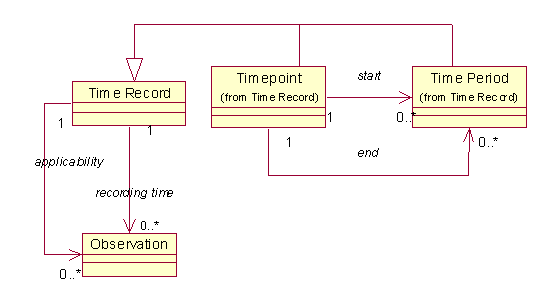
1.9 被拒绝的观察
在进行观察时,总有一些对象是被拒绝的,可能是错误的,不合适的,过期的,那么,这部分的Observation成为Rejected Observation,并作为Observation的子类。每一个Rejected Observation都与一个Observation有关,而这个Observation正是确定原来的Observation成为一个Rejected Observation。
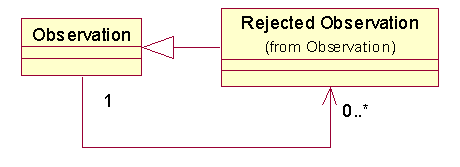
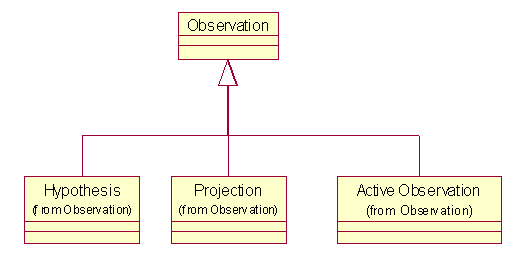
1.10 主动的观察、假设(Hypothesis)和Projection(估计)
在医疗系统中,一个医生经常需要根据已有的观察来判断,做些推测和估计,这些也许并不是实际的测量,因此在这里为Observation引入可能性,由它产生主动的观察、假设(Hypothesis)和Projection(估计)三个子类。Hypothesis需要进行更多的观察来确定,如果Projection是真的,则需要更多的主动观察来支持它。
观察结果的确定程度会引起大家的注意,但是这个方面可能由医生来决定比较好。
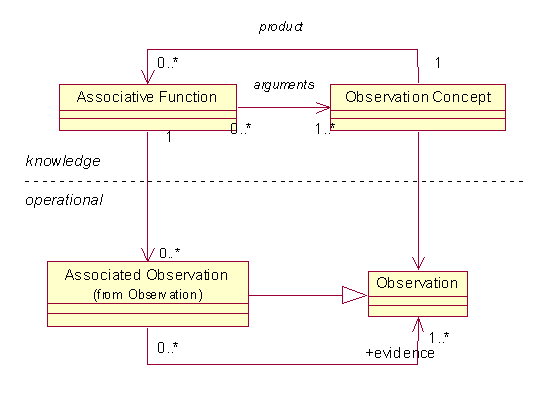
1.11 观察关联
在一个诊断里往往有一连串相关的观察,在以下的模型里,观察(Observation)可以与观察(Observation)相关联,在知识层Observation Concept也要与Observation Concept相关联,这样的关联通过在知识层定义Associative Function,通过Observation Concept作为参数和关联的结果,制订观察相关联的规则,从而对给定观察,可以找到与其有关的关联。
知识层与操作层并非完全形成镜向映射,可以看到,Associative Function并不是Observation Concept的子类。一个Observation Concept可能有几个Associative Function来得到它作为结果,但一个特定的Observation只有一个Observation集合作为证据。
1.12 观察过程
有必要再来看看进行观察的过程,一个简要的过程是,从进行观察(可能是某些测量)开始,然后从知识层以及上一节的模型得到与之相关的观察,并把这些观察列入建议在下一步进行的观察中,这是一个循环的过程。
更复杂一点的规则和描述是,从一个观察开始,找到Observation Concept,查找该Observation Concept作为参数的Associative Function,对于每个Associative Function进行验证,得到相应的Observation Concept作为product,将product作为答案进行下续的观察,也是可以循环的。可以观看序列图如下:

一个更加详细的观察过程还包括把观察区分为主动的观察、假设(Hypothesis)和Projection(估计),并对其中的Projection(估计)和一部分活动的观察进行分析,得到后续的观察,对其中一部分活动的观察根据互相矛盾的观察结果来判定它们是否可被拒绝(Rejected Observations)。
1.13 小结
从常见的数量(Quantity)模型开始,到最后整个观察过程的介绍,这一章的内容包括医疗系统中可以适用的通用模型,其实这些模型并非用于特定的某个领域,如果发现它们跟你的项目情况有相似之处,就可以考虑使用或做一些改动;而下一章,则会介绍观察模式在企业分析中也同样适用。
原文地址: http://news.csdn.net/n/20050510/21139.html















 377
377

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









