







1.简介
FastText, 一种技术, 也是 An NLP library by Facebook.
2016 开源, 比较新.
它由两部分组成: word representation learning 与 text classification.
与 word2vec 关系
它的作者之一是 Thomas Mikolov , 他当年在Google带了一个团队倒腾出来了word2vec,很好的解决了传统词袋表示的缺点,极大地推动了NLP领域的发展。
后来这哥们跳槽去了Facebook,才有了现在的Fasttext。从“血缘”角度来看,Fasttext和word2vec可以说是一脉相承。
2.原理
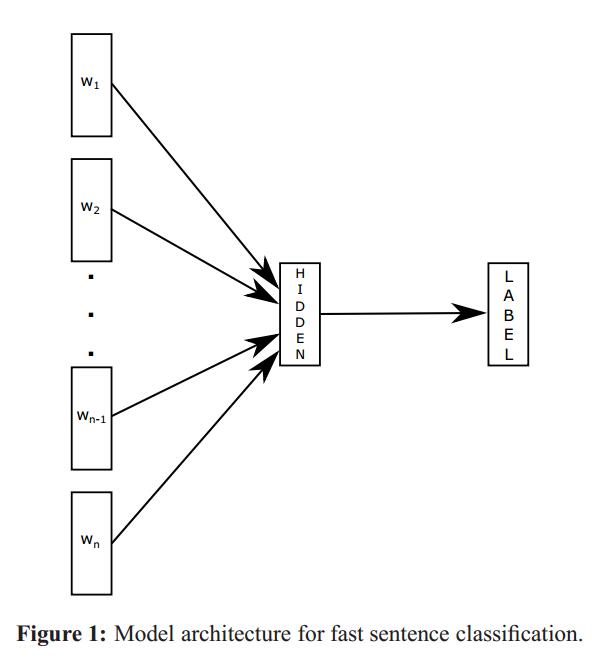
图2-1 分类架构
先来比较一下它和 Word2Vec 的CBOW模型有何异同:
- word2vec 要预测的是中间词, 而 FastText 预测的是类别的label.
- 输入是单词的序列, 输出是预先定义的类别的概率分布
N-gram features
词袋不能包含词序信息, 所以为了弥补这种不足, FastText 采用了 N-gram features, 作为附加特征来表达词语间的局部次序信息.
训练方法
随机梯度下降(SGD) 与 误差后向传播(BP).
SGD中用到了 linearly decaying learning rate.
当类别特别多时, 比如成百上千, 则 use a hierarchical softmax (Goodman, 2001) based on a Huffman coding tree, 同 word2vec 一样.
3.FastText library
GitHub: fastText
3.1 word representation learning
命令$ ./fasttext skipgram -input data.txt -output model , 输入为data.txt, 是utf-8编码的语料库.
学习完之后, 得到两个文件 model.bin 与 model.vec.
- model.bin
binary file, 内含参数与词典.
它可以用来预测新词, out-of-vocabulary words, 即 未登录词. - model.vec
text file, 词的向量表示, one per line.
3.2 text classification
- 训练
用于训练一个有监督的文本分类器.
命令$ ./fasttext supervised -input train.txt -output model, 输入为train.txt, 文本文件, 每行为一个sentence 及相应的 label.
输出为两个文件 model.bin 与 model.vec. - 预测
命令$ ./fasttext predict model.bin test.txt k, test.txt 中每行为一个句子, 输出 k most likely labels for each line. - 段落向量
If you want to compute vector representations of sentences or paragraphs, please use:
$ ./fasttext print-sentence-vectors model.bin < text.txt.
这里让我费解. 待看论文探究一下.
4.Q&A
Q: 能不能得到doc的vector?
A: 不能。 参见 fastText 的issue 。
参考
- 玩转Fasttext
- P. Bojanowski*, E. Grave*, A. Joulin, T. Mikolov, Enriching Word Vectors with Subword Information
- A. Joulin, E. Grave, P. Bojanowski, T. Mikolov, Bag of Tricks for Efficient Text Classification
- jupyter notebook : Comparison of FastText and Word2Vec
- fastText/issues/26















 6709
6709

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









