







写在最前面的
实践的顺序,
应该是先将基础的 数据结构题目类型给实现。
然后再开始尝试 实现对应类型的算法题目,如回溯算法, 贪心算法, 动态规划, 图论;
-
基础的数据结构, 推荐卡尔的:
代码随想录:https://programmercarl.com/; -
算法部分,卡尔的内容结合: https://labuladong.online/algo/home/; 两者在原理解释上结合来看;
-
计算机基础知识,
操作系统、计算机网络、数据结构与算法、数据库、计算机组成原理, 基本
踏实的学习应该是在大学本科, 后续可以自学, 参考 阿秀的笔记
https://interviewguide.cn/notes/01-guide/web-guide-reading.html;
1. ACM 编程模式
在面试过程中,写代码时,
会出现ACM 的编程风格,即需要自己处理输入,输出,这里推荐参考:
-
牛客网的示例练习
-
卡尔网的 https://kamacoder.com/;
2. ACM
2.1 多行输入
输入描述:
输入包括两个正整数a,b(1 <= a, b <= 1000),输入数据包括多组。
输出描述:
输出a+b的结果
示例1
输入例子:
1 5
10 20
输出例子:
6
30
import sys
# 循环执行每行输入, 每行读入后,依次执行如下操作
for line in sys.stdin:
cur_input = line.split() #
out = int(cur_input[0]) + int(cur_input[1]) # 将列表中每个元素转换成整型;
print(out)
-
首先我们从终端输入的每一行数据 被读入之后被视为字符类型,
-
每一行中,我们通过空格键来分隔各个数据, 在一行输入结束后,按下 enter 键, 读入之后被表示为换行符 \n ;
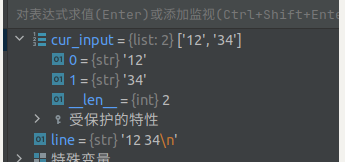
3. line.split 会对当前行中的数据处理, 通过split函数将他们分隔多个数据存储到列表中, 且此时列表中的每个元素仍是 str 类型; 在split()的过程中,如果不指定特殊字符, 则默认通过使用空格符 来分隔;
for line in sys.stdin:
从标准输入读取:for 循环 for line in sys.stdin: 从标准输入中逐行读取输入,直到到达文件结尾 (EOF)。当输入源(例如来自终端的文件或用户输入)关闭时,可能会发生这种情况。在典型的使用场景中(例如在管道中使用脚本或从文件重定向脚本时),这允许脚本无限期地处理输入或直到输入流关闭。
line.split()
处理每一行输入:在循环内,每次处理每一行输入。 line.split() 方法将字符串 line 拆分为列表 cur_input ,其中每个元素都是一个子字符串(最初在输入中用空格分隔)。例如,如果输入行是“123 456”,则 cur_input 将是 ['123', '456'] 。
int(cur_input[0]) + int(cur_input[1]) :此表达式将 cur_input 的第一个和第二个元素转换为整数并对它们求和。结果不会打印或存储在变量 out 之外,这意味着将使用每个新输入行重新计算结果,并且先前的结果将被覆盖。
注意,其中默认使用的分隔符有如下:
Space (' ') 空格 ( ' ' ):表示单词或字符之间的常规空格字符。
Tab ('\t'): 制表符 ( '\t' ):表示制表符,通常用于文本对齐。
Newline ('\n'):换行符 ( '\n' ):在 Unix/Linux 系统中表示一行的结束。它将光标移动到下一行。
Carriage Return ('\r'): 回车符 ( '\r' ):在较旧的 Mac 系统中单独使用,在 Windows 系统中与换行符 ( '\r\n' ) 结合使用,表示行的结束。它将光标返回到行的开头。
Form Feed ('\f'):换页 ( '\f' ):不太常用,该字符在打印机中推进进纸或在文本文档的某些上下文中更改到新“页面”。
当不带任何参数的情况下调用 split() 时,它会将任何上述这些空白字符的序列视为单个分隔符,并且还会在拆分之前自动删除字符串中的任何前导和尾随空白。此行为对于解析输入(其中元素之间的间距量可能不同或使用不同的行结束约定)特别有用。
2.2 输入多行, 需要指定行号
输入描述:
输入第一行包括一个数据组数t(1 <= t <= 100)
接下来每行包括两个正整数a,b(1 <= a, b <= 1000)
输出描述:
输出a+b的结果
示例1
输入例子:
2
1 5
10 20
输出例子:
6
30
此循环还从标准输入中逐一读取每一行,但它使用 enumerate() 函数跟踪每行的索引(行号):
import sys
for i, line in enumerate(sys.stdin):
if i == 0:
n = int(line)
else:
a = line.split()
print(int(a[0]) + int(a[1]))
行为:与第一个循环类似,它迭代每一行直到 EOF,但 enumerate() 还提供了一个计数器 ( i ),默认从 0 开始,并随着每次迭代而递增。此 i 通常用作行号(从 0 开始,或者您可以通过向 enumerate() 提供开始参数来调整它)。
对于输入中行的位置相关的任务(例如,错误报告、必须被索引)。
2.3 输入多行,存在终止条件的
输入描述:
输入包括两个正整数a,b(1 <= a, b <= 10^9),输入数据有多组, 如果输入为0 0则结束输入
输出描述:
输出a+b的结果
示例1
输入例子:
1 5
10 20
0 0
输出例子:
6
30
提供的代码片段使用了多个Python函数的组合( while 、 list 、 map 、 int 、 input 、 split )来重复读取用户的输入,将输入拆分为多个部分,将这些部分转换为整数,并将它们存储在列表中。
while True:
try:
cur_list = list( map(int, input().split()) )
a, b = cur_list[0], cur_list[1]
if a == 0 and b == 0: break
print( a +b )
except:
break
以下是每个组件的详细说明以及它们如何协同工作.
while True:
目的:这是一个无限循环。它将无限期地继续执行其中的代码块,除非被break语句、错误或外部中断(如来自操作系统的终止信号)中断。
行为:它使循环无限运行,使脚本不断提示新输入并对其进行处理,直到明确停止。
input():
功能:该函数等待来自标准输入(通常是键盘)的用户输入。按下 Enter 键后, input() 将整行输入作为字符串读取。
.split()
功能:该方法将字符串拆分为一个列表,其中每个字符都是一个列表项。默认分隔符是任何空格,因此它根据空格、制表符等分隔输入。
map(int, input().split())
函数:map() 将函数应用于可迭代对象中的所有项目。这里, int 是应用的函数,因此 map(int, input().split()) 尝试将 input().split() 返回的列表中的每个项目从字符串转换为整数。
list(map(int, input().split()))
功能:由于 map() 返回一个map对象(它是一个迭代器),因此 list() 用于将这个迭代器转换为列表。为了在 Python 中轻松使用和访问整数作为列表结构,此步骤是必要的。
try, except 的组合
except: :这是一个捕获所有异常处理程序,这意味着它将拦截 try 块抛出的任何类型的异常。通常,最好指定异常类型(如 ValueError 、 IndexError 等),以避免捕获意外错误并掩盖错误。
break :如果 try 块中发生任何异常,则执行 except 块,打破循环并停止程序或退出循环。这可能是由于没有输入足够的数字(导致 IndexError )、输入非整数值(导致 ValueError )或其他不可预见的问题。
鲁棒性:通过防止程序因常见输入错误而崩溃,代码变得更加鲁棒。当遇到输入不足或非数字数据等问题时,它不会以错误消息终止,而是优雅地退出循环。
控制流:它们用于控制程序的流程,确保程序仅在正确的条件下继续运行,并在遇到可能导致运行时错误的问题时安全停止。
2.4 多行输入, 指定每行输入的个数,存在终止条件
输入数据包括多组。
每组数据一行,每行的第一个整数为整数的个数n(1 <= n <= 100), n为0的时候结束输入。
接下来n个正整数,即需要求和的每个正整数。
输出描述:
每组数据输出求和的结果
示例1
输入例子:
4 1 2 3 4
5 1 2 3 4 5
0
输出例子:
10
15
while True:
try:
cur_list = list( map(int, input().split()))
num0 = cur_list[0]
out = -cur_list[0]
if num0 == 0 : break
for i in range (len(cur_list)):
out += cur_list[i]
print(out)
except:
break
或者 采用切片的方式
import sys
for line in sys.stdin:
nums=list(map(int,line.split(' ')))
if nums[0]==0:break
print(sum(nums[1:]))
2.5 多行输入, 指定行号且指定每行输入个数
输入描述:
输入数据有多组, 每行表示一组输入数据。
每行不定有n个整数,空格隔开。(1 <= n <= 100)。
输出描述:
每组数据输出求和的结果
示例1
输入例子:
1 2 3
4 5
0 0 0 0 0
输出例子:
6
9
0
import sys
# while True:
# cur_list = list( map(int, input().split() ) )
for i, line in enumerate(sys.stdin ):
if i == 0: continue
else:
cur_list = list( map(int, line.split()) )
out = sum( cur_list[1:] )
print(out)
1.6 指定求和起始位置
输入描述:
输入数据有多组, 每行表示一组输入数据。
每行的第一个整数为整数的个数n(1 <= n <= 100)。
接下来n个正整数, 即需要求和的每个正整数。
输出描述:
每组数据输出求和的结果
示例1
输入例子:
4 1 2 3 4
5 1 2 3 4 5
输出例子:
10
15
# import sys
# for line in sys.stdin:
# a = line.split()
# print(int(a[0]) + int(a[1]))
while True:
try:
cur_list = list( map(int, input().split()) )
out = sum( cur_list[1:])
print(out)
except:
break
1.7 多行输入, 每行个数不同
输入描述:
输入数据有多组, 每行表示一组输入数据。
每行不定有n个整数,空格隔开。(1 <= n <= 100)。
输出描述:
每组数据输出求和的结果
示例1
输入例子:
1 2 3
4 5
0 0 0 0 0
输出例子:
6
9
0
while True:
try:
cur_list = list( map(int, input().split()))
out = sum( cur_list[0:])
print(out)
except:
break
What are the usual inputs and outputs of GNN, and examples of using pyG are given.;
现在我的任务是在图级别进行分类任务,即对每张图进行一个四分类任务, 数据集是由多个图构成, 然而每个图中的节点个数是不一样的, 该如何处理, 且每个图的信息如下:
-
节点特征,每个节点特征维度是一样的,都是 80维度;
-
边缘特征,每个节点都是前一个节点的后续节点, 如节点2是在节点1之后, 节点3是在节点2之后,依次类推, 但是每张图的节点个数不一样,即节点的个数随着图会动态变化,;
-
图级别的特征, 是该图的位置信息, 所有的图公共包含七类位置, 可以使用one hot编码方式表示, 每张图属于这七中位置之一;
根据以上信息,结合PYG 给出合适的方法以及代码;
2. 字符串 输入
2.1 两行输入, 输入字符串排序
输入描述:
输入有两行,第一行n
第二行是n个字符串,字符串之间用空格隔开
输出描述:
输出一行排序后的字符串,空格隔开,无结尾空格
示例1
输入例子:
5
c d a bb e
输出例子:
a bb c d e
- 使用 .sort() 函数,调用.sort()函数后原始列表就是排好序的列表, 由于.sort()是直接在原列表上进行排序, 不需要对其进行赋值, 如果对其重新赋值会是None;

- .sorted() 函数与 .sort() 函数最大的区别是, .sorted()函数返回排好序的新列表,而不会在原始列表上直接进行排序,这保留了原始列表中元素的顺序,这对于需要原始列表顺序的场景非常有用。 而.sort()函数则是直接在原始列表上直接进行排序,丢失了原始列表中元素的顺序。
- 灵活性:
sorted()不仅适用于列表,也适用于任何可迭代,使其比.sort()更灵活,后者只能与列表一起使用。- 函数式方法:由于
sorted()返回一个新列表,因此它非常适合表达式,并且可以直接在函数和循环中使用,而不会影响原始数据结构。这在首选数据不可变性的函数式编程风格中特别有用。
.join() 函数的作用:
.join()中的方法是一种字符串方法,它采用字符串的可迭代(如列表、元组或字典),并将其元素连接起来,这些元素由用于调用该方法的字符串分隔。此方法对于将字符串列表转换为单个字符串特别有用,每个元素之间都有特定的分隔符。
separator_string.join(iterable)
separator_string :这是将放置在最终连接字符串中可迭代对象的每个元素之间的字符串。
iterable: 这应该是一个可迭代的(如列表、元组),其中每个元素都是一个字符串。如果元素不是字符串,则必须先将它们转换为字符串,然后才能使用 .join() 。
-
如果可迭代对象包含任何非字符串元素,则会导致
TypeError.所有元素必须先转换为字符串,然后才能连接。 -
与在循环中使用字符串连接相比,该
.join()方法通常因其效率而受到青睐,因为它可以更有效地分配内存并且执行速度更快,尤其是在处理大型数据集时。总体而言,它是一种强大的方法,
.join()可以有效地将多个字符串组合为一个字符串,并控制最终输出中元素的分离方式。
.join() 函数为什么不再末尾添加分隔符
- 常见格式要求:在大多数情况下,在连接字符串时,例如创建逗号分隔列表、生成文件路径或 URL,典型的要求是仅在元素之间使用分隔符,而不是在末尾使用分隔符。Python
.join()的方法遵循了这个常见的用例,使其更加方便,并减少了对额外字符串操作的需求。 - Consistency and Predictability:
一致性和可预测性:通过确保分隔符只出现在元素之间,输出.join()是可预测和一致的。这意味着用户无需担心在最后处理额外的分隔符,这可能会导致数据处理或输出显示错误。 - Flexibility:
灵活性:如果您确实需要尾随分隔符,则可以在使用.join()后轻松手动添加一个。这为该方法提供了灵活性,既可以满足常见方案,也可以满足边缘情况,而不会使主要功能复杂化
words = ['apple', 'banana', 'cherry']
sentence = ', '.join(words) + ',' # Manually adding a trailing comma
print(sentence) # Output: apple, banana, cherry,
import sys
for i, line in enumerate(sys.stdin):
if i == 0: continue
cur_list = line.split()
# cur_list.sort()
# sort_str = ' '.join(cur_list)
sort_str = sorted(cur_list)
sort_str = ' '.join(sort_str)
print(sort_str)
2.2 多行输入, 每行输入中空格分开
输入描述:
多个测试用例,每个测试用例一行。
每行通过空格隔开,有n个字符,n<100
输出描述:
对于每组测试用例,输出一行排序过的字符串,每个字符串通过空格隔开
示例1
输入例子:
a c bb
f dddd
nowcoder
输出例子:
a bb c
dddd f
nowcoder
import sys
for i, line in enumerate(sys.stdin):
cur_list = line.split()
sort_list = sorted(cur_list)
sort_list = ' '.join(sort_list)
print(sort_list)
2.3 多行输入, 每行中逗号分开
多个测试用例,每个测试用例一行。
每行通过,隔开,有n个字符,n<100
输出描述:
对于每组用例输出一行排序后的字符串,用','隔开,无结尾空格
示例1
输入例子:
a,c,bb
f,dddd
nowcoder
输出例子:
a,bb,c
dddd,f
nowcoder
去除 换行符 line.strip(‘\n’)
import sys
for i, line in enumerate(sys.stdin):
cur_line = line.strip('\n')
cur_list = cur_line.split(',')
sort_list = sorted(cur_list)
sort_list = ','.join(sort_list)
print(sort_list)
list(): 的作用, 可以将一个字符串, 拆分成多个单个字母,
比如 str= ‘mycode’: 通过 list(str) 之后,会返回 [‘m’, ‘y’, ‘c’, ‘o’, ‘d’, ‘e’]
2.4 多行输入
输入描述:
输入有多组测试用例,每组空格隔开两个整数
输出描述:
对于每组数据输出一行两个整数的和
示例1
输入例子:
1 1
输出例子:
2
import sys
for i, line in enumerate(sys.stdin):
cur_line = line.split()
cur_list = list(map(int,cur_line))
out = cur_list[0] + cur_list[1]
print(out)














 6万+
6万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









