







原文出自这里,
https://zhuanlan.zhihu.com/p/644773759
本文实际是谷歌在 KDD MLG Workshop 2020 上发表的工作,扩充后发到了 JMLR’23 期刊上,所以本文相对“过时”了。
Abstract
图神经网络(GNNs)在节点分类和链路预测等许多图分析任务上取得了最先进的结果。然而,图上重要的无监督问题(例如图聚类)已被证明更难以抵抗 GNN 的进步。图聚类与 GNN 中的节点池化具有相同的总体目标——这是否意味着 GNN 池化方法在图聚类方面做得很好? 令人惊讶的是,答案是否定的——在简单基线(例如使用 k 均值聚类学习到的表示)效果良好的情况下,当前的 GNN 池化方法通常无法恢复簇结构。我们通过仔细设计一组实验来进一步研究图结构和属性数据中的不同信噪比场景。为了解决这些方法在聚类中表现不佳的问题,我们引入了深度模块化网络(Deep Modularity Networks, DMoN),这是一种受聚类质量模块化度量启发的无监督池化方法,并展示了它如何解决现实世界图的具有挑战性的聚类结构的恢复问题。同样,在现实世界的数据上,我们表明 DMoN 生成了与 ground truth 标签密切相关的高质量簇,实现了最先进的结果,在不同指标上比其他池化方法提高了 40% 以上。
1 Introduction
GNNs 利用数据的结构作为计算图,允许信息跨边传播。许多现实世界系统被表示为图时,表现出局部不均匀的边分布, forming clusters (also called communities or modules)—groups of nodes with high in-group edge density, and relatively low out-group density. 簇可以对应于图中的有趣现象,例如社交图中的教育或就业。GNNs 可以受益于簇中可能产生的高阶结构信息,例如通过池化或可训练的边注意力。
大多数利用高阶结构的现有工作并没有直接解决图中的节点划分或簇分配问题。此外,大多数工作仅在半监督或监督框架内探索这些机制,忽略了这样一个事实:_无监督_图聚类本身通常是一个非常有用的最终目标——数据探索、可视化、基因组特征发现、异常检测等等。此外,许多现有的无监督结构感知方法具有不良特性,例如依赖于多步骤优化过程,而该过程不允许端到端可微目标。
在这项工作中,我们采用 ab initio 方法来解决 GNN 领域中的聚类问题,弥合了传统图聚类目标和深度神经网络之间的差距。我们首先在图池化和完全无监督聚类之间建立联系,因为图池化在文献中通常作为有监督 GNN 架构的正则化器进行研究。贡献:
- DMoN 是一个 GNNs 的无监督聚类模块,允许以端到端可微的方式优化聚类分配。
- 对合成图性能的实证研究,说明了现有工作的问题以及这项工作如何改进这些制度中的模型性能。
- 对现实世界数据的彻底实验评估表明,许多池化方法不能很好地反映层次结构,并且无法利用图结构和节点属性,也无法利用联合信息。
2 Related Work
Graph pooling
图池化 旨在通过迭代粗化来解决图的层次性质。早期的架构[1] 采用固定的公理池化,在网络学习时没有对聚类进行优化。DiffPool[2] 建议在 GNNs 架构中包含一个_可学习_池化。为了帮助收敛,DiffPool 包含一个链接预测损失以帮助封装图的聚类结构和一个额外的熵损失来惩罚软分配。Top-k[3] 和 SAG[4] 使用学习到的权重来稀疏化图(为每个节点选择 top-k 边)。MinCutPool[5] 研究谱聚类的可微形式作为池化策略。章节 4.2 说明 MinCutPool 并没有优化其谱目标,它只是正交化其特征。
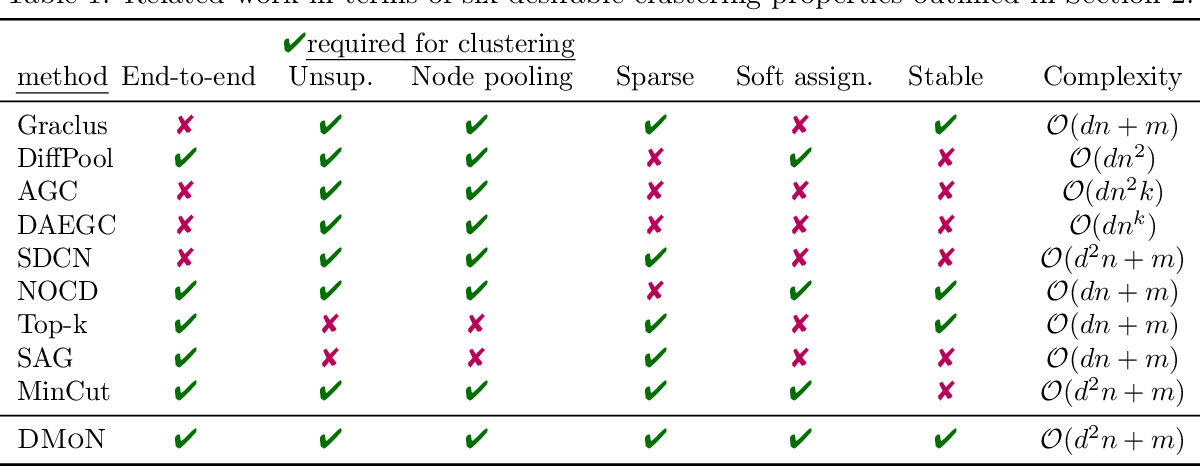
Table 1: Related work in terms of seven desirable clustering properties outlined in Section 2
表 1 中总结了主流图池化方法与其聚类能力相关的六个理想属性:
- End-to-end training 端到端训练允许捕获图结构和节点特征。AGC、DAEGC 和 SDCN 都使用 k-means 来初始化模型,禁止端到端学习。
- Unsupervised 无监督训练是聚类模型的理想设置。监督*图聚类的工作超出了我们的范围。
- Node aggregation 节点聚合对于我们从聚类角度解释图池化至关重要。Top-k 和 SAG 池化都只会稀疏化图,不会减少节点集。
- Sparse 由于现实世界中的图的大小和稀疏性各不相同,因此方法不能受到 O(n2)\mathcal{O}(n^2) 链接预测目标的限制,例如 DiffPool 或计算 At\mathbf{A} ^t,如 top-k 池化方法或 AGC 和 DAEGC。NOCD 的梯度是节点数量的二次方;然而,解决了二次采样问题以获得理想的次二次可扩展性。
- Soft assignments 软分配允许对集群的交互进行更灵活的推理。
- Stable 该方法在图结构方面应该是稳定的。当图变得更加稀疏时,DiffPool、AGC、DAEGC 和 SDCN 的性能会发生显着变化,而 MinCutPool 无法在幂律图上收敛。
我们还分析了这些方法的计算复杂性。一般来说,非稀疏方法,例如 DiffPool、AGC 和 DAEGC 无法扩展到大型图,因为它们的复杂度至少是二次的。某些方法(例如 NOCD、top-k 池化和 SAG)会在其目标/优化中对二次项进行二次采样,以获得所需的可扩展性。章节 4.1 中分析了 DMoN 的复杂性。这项工作保持了一流的可扩展性,而无需牺牲子采样的任何信息。
3 Preliminaries
介绍问题表述,回顾常见的图聚类目标以及如何使它们可微分。
图 G=(V,E)G=(V,E),节点 V=(v1,…,vn),|V|=nV=(v_1,\ldots,v_n), |V|=n,边 E⊆V×V,|E|=mE\subseteq V\times V, |E| = m,A\mathbf{A} 表示 GG 的 n×nn\times n 邻接矩阵。viv_i 的“度”是它的连接数 di:=∑j=1nAijd_i:=\sum_{j=1}^n \mathbf{A}_{ij}。图划分函数 F:V↦{1,…,k}\mathcal{F} : V\mapsto \{1, \ldots, k\} 将节点集 VV 分割为 kk 个分区 Vi={vj:F(vj)=i}V_i=\{v_j: \mathcal{F}(v_j)=i\} 。与标准图聚类不同,还提供了节点属性 X∈Rn×s\mathbf{X} \in \mathbb{R}^{n\times s}。
3.1 Graph Clustering Quality Functions
经典的聚类目标是离散的,不适合基于梯度的优化,DMoN 和一些先前的工作依赖于谱近似。
Modularity. 模块度结合了 null model 来量化聚类与随机图下预期观察到的偏差。在给定度数的完全随机图中,度数为 dud_u 和 dvd_v 的节点 uu 和 vv 以概率 dudv/2md_ud_v/2m 连接。模块化衡量簇内边与预期边之间的差异:
(1)Q=12m∑ij[Aij−didj2m]δ(ci,cj),\mathcal{Q} = \frac{1}{2m}\sum_{ij}\left[\mathbf{A}_{ij}-\frac{d_id_j}{2m}\right]\delta(c_i, c_j), \tag{1}
其中,如果 ii 和 jj 在同一簇中,则 δ(ci,cj)=1\delta(c_i, c_j)=1,否则为 0。注意Q∈(−1/2;1]\mathcal{Q} \in (-1/2; 1](簇与边密度没有相关性时为0),但不一定在 1 处最大化,只在具有相同度分布的图间有可比性。此外,即使对于 Erdős–Rényi 随机图,最优模块度也是正的,这意味着正模块度并不意味着强的聚类结构。虽然模块度存在问题,但它仍然是科学文献中最常用和非常有用的图聚类度量之一。
3.2 Spectral Modularity Maximization
最大化模块化度是 NP-hard 的,Newman 有效地解决了 a spectral relaxation of the problem[7]。令 C∈{0,1}n×k\mathbf{C} \in \{0, 1\}^{n\times k} 为聚类分配矩阵,d\mathbf{d} 为度向量。模块度矩阵 B\mathbf{B} 定义为 B=A−dd⊤2m\mathbf{B}=\mathbf{A}-\frac{\mathbf{d}\mathbf{d}^\top}{2m},模块度 Q\mathcal{Q} 可以重新表述为:
(2)Q=12mTr(C⊤BC)\mathcal{Q} = \frac{1}{2m}\text{Tr}(\mathbf{C}^\top\mathbf{B}\mathbf{C}) \tag{2}
Relaxing C∈Rn×k\mathbf{C}\in\mathbb{R}^{n\times k},最大化 Q\mathcal{Q} 的最优 C\mathbf{C} 是模块度矩阵 B\mathbf{B} 的 top-k 特征向量。 虽然 B\mathbf{B} 是稠密的,但迭代特征值求解器可以利用 B\mathbf{B} 等于稀疏 A\mathbf{A} 和一阶矩阵 −dd⊤2m-\frac{\mathbf{d}\mathbf{d}^\top}{2m} 之和,意味着矩阵向量积 Bx\mathbf{B}\mathbf{x} 可以有效地计算为:
Bx=Ax−d⊤xd2m\mathbf{B}\mathbf{x} = \mathbf{A}\mathbf{x} - \frac{\mathbf{d}^\top\mathbf{x}\mathbf{d}}{2m}
并通过幂迭代或 Lanczos 算法等迭代方法进行高效优化。然后,可以通过谱二分[7]以及类似于 Kernighan-Lin 算法的迭代细化来获得簇。然而,这些公式完全在图结构上运行,并且使它们适应属性图是很重要的。
3.3 Graph Neural Networks
设 X0∈Rn×s\mathbf{X}0\in\mathbb{R}{n\times s} 为初始节点特征,A~=D−12AD−12\widetilde{\mathbf{A}} = \mathbf{D}^{-\frac{1}{2}}\mathbf{A}\mathbf{D} ^{-\frac{1}{2}} 为归一化邻接矩阵,第 tt 层 Xt+1\mathbf{X}^{t+1} 的输出为:
(3)Xt+1=SeLU(A~XtW+XWskip)\mathbf{X}^{t+1} = \mathrm{SeLU}(\widetilde{\mathbf{A}}\mathbf{X}^{t}\mathbf{W} + \mathbf{X}\mathbf{W}_{\mathrm{skip}}) \tag{3}
我们对经典的 GCN 架构进行了两处更改:1. 删除了自环边的创建,使用 Wskip∈Rs×s\mathbf{W}_{\mathrm{skip}}\in\mathbb{R}^{s\times s} 可训练的跳连;2. 用 SeLU 替换 ReLU 以更好收敛。
4 Method
本节介绍 DMoN,使用图神经网络进行属性图聚类。受模块度质量函数及其谱优化的启发,我们提出了一种完全可微的无监督聚类目标,该目标使用 null model 来优化软聚类分配,以控制图中的不均匀性。然后,我们讨论正则化聚类分配的挑战,并提出崩溃正则化,它可以有效防止平凡的解决方案并且不影响目标的优化。
4.1 DMoN: Deep Modularity Networks
DMoN 包括 (1) 对簇分配矩阵 C\mathbf{C} 进行编码的架构;(2) 用于优化分配的目标函数。
我们建议通过 softmax 函数的输出获得 C\mathbf{C},这使得(软)簇分配是可微分的。簇分配的输入可以是任何可微的消息传递函数,这里使用图卷积网络来获取每个节点的软簇,如下所示:
(4)C=softmax(GCN(A~,X)),\mathbf{C} = \mathrm{softmax}(\mathrm{GCN}(\widetilde{\mathbf{A}}, \mathbf{X})), \tag{4}
其中 GCN\mathrm{GCN} 是在归一化邻接矩阵 A~=D−12AD−12\widetilde{\mathbf{A}} = \mathbf{D}^{-\frac{1}{2}}\mathbf{A}\mathbf{D} ^{-\frac{1}{2}} 上运行的多层卷积网络 。
我们建议通过以下目标来优化此分配,该目标将公式 (2) 谱模块度最大化与新颖的正则化相结合,防止平凡解:
(5)L{DMoN}(C;A)=−12mTr(C⊤BC)⏟modularity+kn‖∑iCi⊤‖F−1⏟collapseregularization,\mathcal{L}\text{{DMoN}}(\mathbf{C}; \mathbf{A}) = \underbrace{-\frac{1}{2m}\text{Tr} ( \mathbf{C}^\top \mathbf{B} \mathbf{C})}{\mathrm{modularity}} + \underbrace{\frac{\sqrt{k}}{n}\left\lVert \sum_i\mathbf{C}^\top_i\right\rVert_F - 1}_{\mathrm{collapse~regularization}}, \tag{5}
其中 ‖⋅‖F\lVert\cdot\rVert_F 是 Frobenius 范数。我们将 Tr(C⊤BC)\text{Tr}(\mathbf{C}^\top\mathbf{B}\mathbf{C}) 的计算分解为稀疏矩阵-矩阵乘法和秩一归一化 Tr(C⊤AC−C⊤d⊤dC)\text{Tr}(\mathbf{C}\top\mathbf{A}\mathbf{C}-\mathbf{C}\top\mathbf{d}^\top\mathbf{d}\mathbf{C})。这使得计算 L{DMoN}\mathcal{L}_\text{{DMoN}} 的时间复杂度从 O(n2)\mathcal{O}(n^2) 降低到 O(d2n)\mathcal{O}(d^2n),允许 DMoN 有效地处理稀疏图。
4.2 Collapse regularization
如果不对对分配矩阵 C\mathbf{C} 进行额外的约束,最小割和模块度目标的谱聚类都会出现虚假的局部最小值:将所有节点分配给同一聚类会产生一个简单的局部最优解。MinCutPool 通过采用软正交正则化 ‖C⊤C−I‖F\left\lVert \mathbf{C}^\top\mathbf{C} - \mathbf{I}\right\rVert_F 形式的谱正交性约束来解决此问题。
而我们提出 collapse regularization,一个更宽松的约束,它可以防止琐碎的划分,同时不主导主要目标的优化。正则化器是(软)簇成员计数的 Frobenius 范数,标准化为范围 [0,k][0, \sqrt{k}]。当簇大小完全平衡时,它的值为 00;当所有节点都归为一个簇时,则它的值为 k\sqrt{k}。我们还通过在 softmax 之前将 dropout 应用于 GNN 表示来改进训练,防止梯度下降陷入高度非凸目标函数的局部最优。
5 Experiments
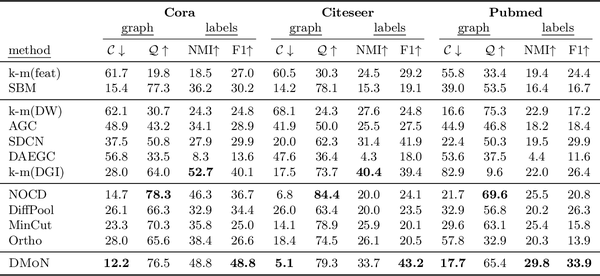
Table 4: Results on three datasets from Sen et al. (2008) in terms of graph conductance C, modularity Q, NMI with ground-truth labels, and pairwise F1 measure. We group the methods into three categories: baselines using only one aspect of data, neural representation learning, and neural graph pooling methods.
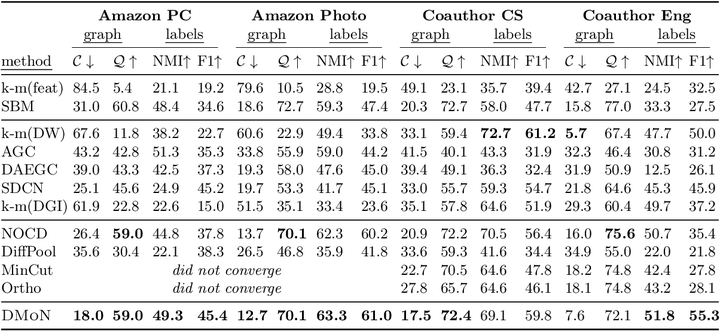
Table 5: Results on four datasets from Shchur et al. (2018) in terms of graph conductance C, modularity Q, NMI with ground-truth labels, and pairwise F1 measure. We group the methods into three categories: baselines using only one aspect of data, neural representation learning, and neural graph pooling methods.
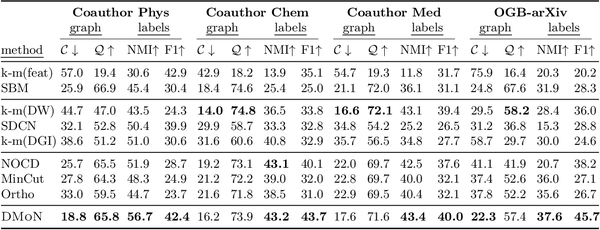
Table 6: Results on four large-scale datasets in terms of graph conductance C, modularity Q, NMI with ground-truth labels, and pairwise F1 measure. We group the methods into three categories: baselines using only one aspect of data, neural representation learning, and neural graph pooling methods.
References:
[1]: Michaël Defferrard, Xavier Bresson, and Pierre Vandergheynst. Convolutional neural networks on graphs with fast localized spectral filtering. In NIPS, 2016.
[2]: Zhitao Ying, Jiaxuan You, Christopher Morris, Xiang Ren, Will Hamilton, and Jure Leskovec. Hierarchical graph representation learning with differentiable pooling. In NeurIPS, 2018.
[3]: Hongyang Gao and Shuiwang Ji. Graph U-nets. In ICML, 2019.
[4]: Junhyun Lee, Inyeop Lee, and Jaewoo Kang. Self-attention graph pooling. In ICML, 2019.
[5]: Filippo Maria Bianchi, Daniele Grattarola, and Cesare Alippi. Spectral clustering with graph neural networks for graph pooling. In ICML, 2020.
[6]: Jure Leskovec, Kevin J Lang, Anirban Dasgupta, and Michael W Mahoney. Statistical properties of community structure in large social and information networks. In WWW, 2008.
[7]: Mark EJ Newman. Finding community structure in networks using the eigenvectors of matrices. Physical review E, 2006.
本文使用 Zhihu On VSCode 创作并发布















 508
508











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









