






今天练习爬虫,所以决定把对象定在百度新闻上,首先打开百度新闻的页面刷了刷发现内容更新的时候网址没有变,很明显在监听器下可以看到XHR请求的内容,所以爬的时候要用这个网址来作为URL
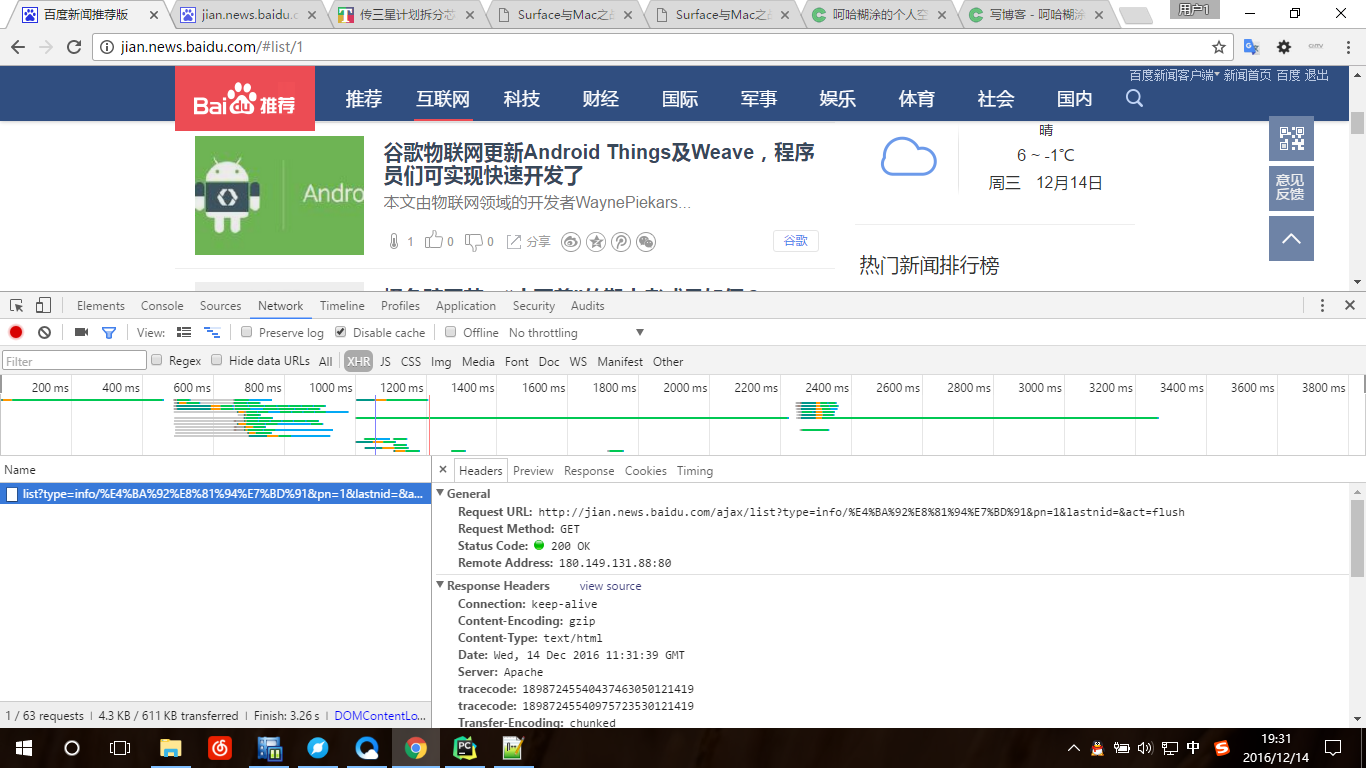
http://jian.news.baidu.com/ajax/list?type=info/%E4%BA%92%E8%81%94%E7%BD%91&pn=1&lastnid=&act=flush
分析下这个网址可以看到页数标志是pn=1,info/XXX是当前的分类。这样就好办直接上代码
from bs4 import BeautifulSoup
import requests
import time
# headers 建议登录后加上这样效果更好,如果不想用可以删掉
headers = {
'User-Agent': 'xxxxx',
'Cookie': 'xxxxxxx'
}
# URL也可以写成http://jian.news.baidu.com/ajax/list?type=info/互联网&pn=
# 推荐选项比较特殊 http://jian.news.baidu.com/ajax/list?type=chosen/%E6%8E%A8%E8%8D%90&pn=1
url = 'http://jian.news.baidu.com/ajax/list?type=info/%E4%BA%92%E8%81%94%E7%BD%91&pn='
def get_pages_url(start, end):
# 此处做一个迭代获得对应页的URL
for num in range(start, end):
get_data(url + str(num))
time.sleep(2) # 做个延时防止被封IP
def get_data(url):
# 使用get的方式请求内容
html = requests.get(url, headers=headers)
# 使用BeautifulSoup解析获得的内容
soup = BeautifulSoup(html.text, 'html.parser')
# 由于获得的数据是json格式的数据,所以用json()的方法将json数据转化为dict
data = html.json()
if data.get('errno') == 0: # 如果返回的数据正常就执行下面的操作
da = data['data']['list'] # 由于数据嵌套了多层,所以只能一层一层找
for d in da:
title = d.get('title')
url = d.get('url')
img = d.get('imageurls')
time = d.get('ts')
news = dict(time=time, title=title, url=url, img=img)
print(news)
if __name__ == '__main__':
get_pages_url(0, 11)get_pages_url(0,11)可以任意换比如你想获取1到100页的内容把11换成101就好了
下面是获取数据样例
{'url': 'http://it.southcn.com/9/2016-12/14/content_161644812.htm', 'img': '', 'title': '网络黑灰产业经济需严打', 'time': '19:18'}
{'url': 'http://www.tmtpost.com/2545325.html', 'img': 'http://timg01.baidu-img.cn/timg?tc&size=c169_m119&sec=0&quality=90&di=32a87abd57b21ea7799e9aeab2b9bfd7&src=http%3A%2F%2Ft12.baidu.com%2Fit%2Fu%3D801614855%2C636984283%26fm%3D170%26s%3DEF42E401B3306A2F44F41CD9030050B4%26w%3D218%26h%3D146%26img.JPEG', 'title': 'iPhone6s关机问题发酵,韩国:要严查|12月14日坏消息榜 ', 'time': '19:18'}
{'url': 'http://www.leiphone.com/news/201612/bTY6FmG2EncrijnD.html', 'img': 'http://timg01.baidu-img.cn/timg?tc&size=c169_m119&sec=0&quality=90&di=2db26ccdf625e3cbad9ad2fa257bfbef&src=http%3A%2F%2Ft10.baidu.com%2Fit%2Fu%3D3207967248%2C357618926%26fm%3D170%26s%3D29828C5C4BC06D72428D235B020010F4%26w%3D218%26h%3D146%26img.JPEG', 'title': '谷歌物联网更新Android Things及Weave,程序员们可实现快速开发了 ', 'time': '19:18'}
{'url': 'http://xuxuhong.baijia.baidu.com/article/724189', 'img': 'http://timg01.baidu-img.cn/timg?tc&size=c169_m119&sec=0&quality=90&di=387e3225d560119ae2c098186769cbe9&src=http%3A%2F%2Ft10.baidu.com%2Fit%2Fu%3D3112654077%2C442414762%26fm%3D170%26s%3D09E8E812A8666E8A7E6FB34D0300C0E4%26w%3D218%26h%3D146%26img.JPEG', 'title': '橘色豌豆荚:“小而美”的期中考成果如何?', 'time': '19:18'}大家有兴趣可以测试下















 9208
9208

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









