







笔者在之前的一篇博客《谈谈机器学习模型的可解释性》介绍了机器学习可解释性的基本概念,那么今天我们就来看看如何具体的利用这些可解释的工具来对一个真实的模型进行可解释性的分析。
本文所有代码参见https://github.com/gangtao/ml-Interpretability
构建模型
首先我们获得了FIFA 2018年俄罗斯世界杯比赛的所有数据,我们利用这些数据来构建机器学习的模型。
import numpy as np
import pandas as pd
import warnings
warnings.filterwarnings('ignore')
data = pd.read_csv('./FIFA 2018 Statistics.csv')
data.head()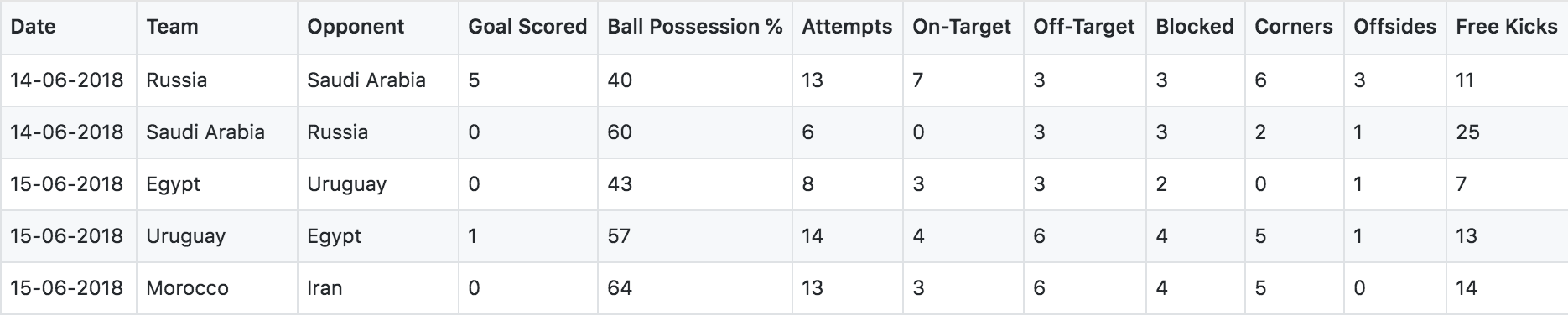
该数据集记录了俄罗斯世界杯每一场比赛的数据,包含日期,本队,对手,得分,控球,射门,射中,射偏等等统计数据,其中有一个字段‘Man of the Match’是本队是否获得了当场比赛的最佳球员。我们利用这些数据来构建一个预测模型,利用所有的数据来预测本队是否获得了赛后评比的当场最佳球员。
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.tree import DecisionTreeClassifier
y = (data['Man of the Match'])
feature_names = [i for i in data.columns if data[i].dtype in [np.int64]]
X = data[feature_names]
train_X, val_X, train_y, val_y = train_test_split(X, y, random_state=1)
my_model_1 = RandomForestClassifier(random_state=0).fit(train_X, train_y)
my_model_2 = DecisionTreeClassifier(random_state=0).fit(train_X, train_y)我们利用随机森林和决策树算法训练了两个分类模型,用于预测是否本队获得了最佳球员。
对于决策树模型,我们可以利用graphviz可视化该模型。
from sklearn import tree
import graphviz
tree_graph = tree.export_graphviz(my_model_2, out_file=None, feature_names=feature_names)
graphviz.Source(tree_graph)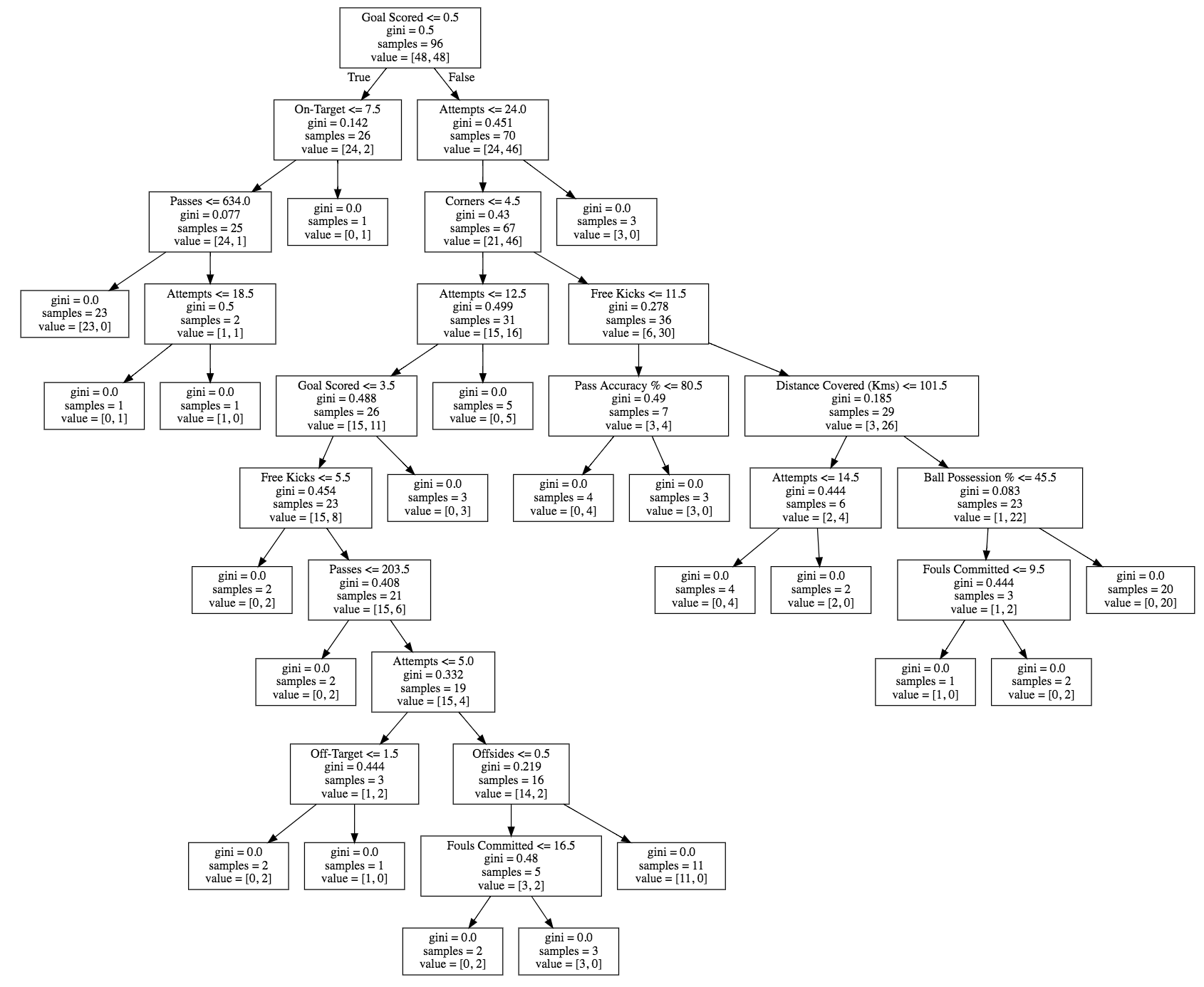
Permutation Importance
对于一个模型的解释,我们可以从特征开始,首先分析那些特征是最重要的,对越策的结果影响最大。在之前我们看到的决策树模型中,我们看到SKlearn计算了一个我们称之为基尼指数(gini)或者信息熵的值,用于反应特征的重要性。另外我们也可以从特征在树中的的层级来推断出特征的重要性,一般来说,出现在里根结点越近的层级,表示该特征越重要。在我们之前的决策树模型中,得分位于根结点,显然这个特征是影响是否获得当场最佳球员的重要特征。
对于利用基尼指数来计算特征重要性的方法不具有通用性,我们需要一个与模型无关的方法来计算。
Permutation Importance提供了一个和模型无关的计算特征重要性的方法。Permutation的中文含义是排列的意思,该算法基本思路如下:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 197
197











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









