






支持向量机基于统计学习理论,强调结构风险最小化。其基本思想是:对于一个给定有限数量训练样本的学习任务,通过在原空间或经投影后的高维空间中构造最优分离超平面,将给定的两类训练样本分开,构造分离超平面的依据是两类样本对分离超平面的最小距离最大化。
1.它的思想可用下图说明,图中描述的是两类样本线性可分的情形,图中“圆”和“星”分别代表两类样本。
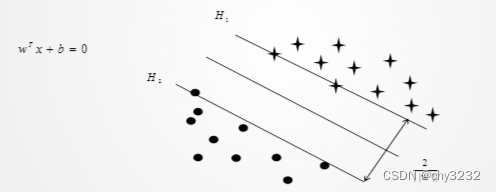
根据支持向量机原理,建立模型就是要找到最优分离超平面(最大间隔分离样本的超平面)分开两类样本。最优分离超平面可以记为:

这样位于最优分离超平面上方的点满足:

位于最优分离超平面下方的点满足:

通过调整权重,边缘的超平面可以记为:

即落在或者其上方的为正类,落在H,或者其下方的为负类,综合以上得到:

落H或者H2上的训练样本,称为支持向量。
2.如何寻找最优的超平面和支持向量,需要用到更高的数学理论知识及技巧,这里不再介绍。对于非线性可分的情形,可以通过非线性映射将原数据变换到更高维空间,在新的高维空间中实现线性可分。这种非线性映射可以通过核函数来实现,常用的核函数包括:

3. 支持向量机分类模型构建
(1)导入支持向量机模块svm。
import sklearn import svm(2)利用svm创建支持向量机类svm。
clf=svm.SVC(kernel='rbf')其中核函数可以选择线性核、多项式核、高斯核、sig核,分别用1inear,poly, rbf,sigmoid表示,默认情况下选择高斯核。
(3)调用svm中的fit()方法进行训练。
clf.fit(x,y)(4)调用svm中的score()方法,考查其训练效果。
rv=clf.score(x,y) #模型准确率(针对训练数据)(5)调用svm中的predict()方法,对测试样本进行预测,获得其预测结果。
R=clf.predict(x1)示例代码如下:
import pandas as pd
data=pd.read_excel('car.xlsx")
x=data.iloc[:1690;6].as_matrix()
y=data.iloc[:1690,6].as_matrix()
x1=data.iloc[1691;:6].as_matrix()
y1=data.iloc[1691,6].as_matrix()
from sklearn importsvm
cIf= svm.SVC(kernel='rbf')
clffit(x,y)
rv=clf.score(x,y);
R=clf.predict(x1)
Z=R-y1
Rs=len(Z[Z==0])/len(Z)
print('预测结果为:'R)
print('预测准确率为:',Rs)
输出结果如下:
预测结果为:[4 3 12 3 2 43 24 33 3 3 33 3 3 3312324 324312324324]
预测准确率为: 1.0
数据来源:http://archive.ics.uci.edu/ml/datasets/Car+Evaluation















 516
516











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









