







 CommonsenseQA是一个针对常识知识的问答数据集,旨在推动机器理解常识。通过从CONCEPTNET提取信息并进行众包,创建了包含12247个问题的数据集。最佳基线模型BERT-large的准确率为56%,远低于人类的89%。该数据集挑战了现有NLU模型,为增强机器的常识理解提供了新路径。
CommonsenseQA是一个针对常识知识的问答数据集,旨在推动机器理解常识。通过从CONCEPTNET提取信息并进行众包,创建了包含12247个问题的数据集。最佳基线模型BERT-large的准确率为56%,远低于人类的89%。该数据集挑战了现有NLU模型,为增强机器的常识理解提供了新路径。
COMMONSENSEQA: A Question Answering Challenge Targeting Commonsense Knowledge
COMMONSENSEQA: A Question Answering Challenge Targeting Commonsense Knowledge (Alon Talmor, Jonathan Herzig, Nicholas Lourie, Jonathan Berant)
论文:https://arxiv.org/pdf/1811.00937.pdf
数据集:www.tau-nlp.org/commonsenseqa
Baseline model:github.com/jonathanherzig/commonsenseqa
(一)论文概述
数据集提出的动机:当人们回答问题时,往往会利用自身了解的知识结合特定的背景。但目前的机器阅读理解集中在回答一些文章内容相关的问题,不需要一般知识背景。于是,为了研究基于先验知识的问答,作者提出了COMMONSENSEQA,一个用于常识性问答的新数据集。
为了获取超出关联之外的常识,作者从CONCEPTNET (Speer et al., 2017)中提取了与单个源概念具有相同语义关系的多个目标概念。群体工作者被要求写单项选择题,其中包含源概念,并依次区分每个目标概念。这鼓励工作人员创建具有复杂语义的问题,这些问题通常需要先验知识。数据生成过程概括如下图,之后会在第三部分对这一过程进行详细介绍。
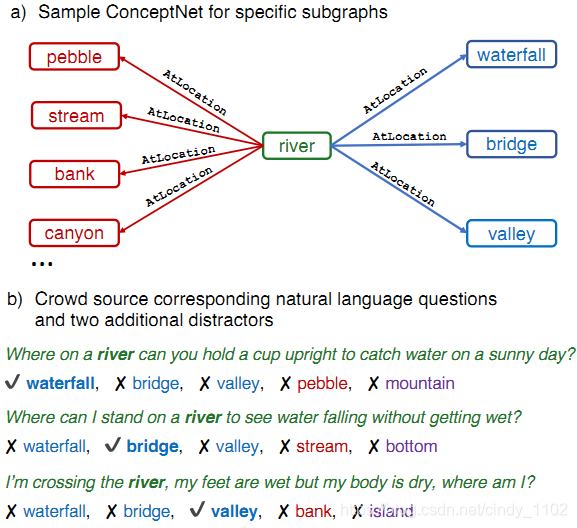
通过这个过程,共创建了12247个问题,并用大量的baseline model说明了这一任务的难度。最好的baseline是基于BERT-large的模型 (Devlin et al., 2018),获得56%的准确率,远低于人类89%的表现。
该论文的贡献如下:
- 提出一个新的以常识为中心的QA数据集,包含12247个示例。
- 提出一种从概念网生成大规模常识性问题的新方法。
- 在COMMONSENSEQA上对最先进的NLU模型进行的实证评估,结果表明人类的表现远远超过当前的模型。
(二)相关研究
机器常识是关于开放世界的知识和推理能力,被认为是自然语言理解的关键组成部分。尽管有过很多相关研究,但是探究机器的常识理解能力依旧较为困难。
相关研究:
- 寻找能用自然语言解释环境的程序(McCarthy, 1959)
- 利用世界模型加深对语言的理解(Winograd, 1972)
- 常识性表征和推理程序(麦卡锡和海斯,1969;Kowalski和Sergot, 1986)
- 大规模常识知识库(Lenat, 1995;Speer等,2017)
- 要求正确解决指代消解实例对, Winograd Schema Challenge (Levesque, 2011)
- COPA(Choice of Plausible Alternatives)500个开发500个测试问题。问两个选项中哪一个最能反映与前提相关的因果关系 (Roemmele et al., 2011)
- JHU Ordinal Commonsense Inference要求一个1-5的标签,表示一种情况可能导致另一种情况(Zhang et al., 2017)
- Story Cloze Test(也称为ROC Stories)将故事真实结尾与难以置信的假结尾进行对比(Mostafazadeh et al., 2016)
- SWAG 选择对初始事件之后发生的事情的正确描述(Zellers et al., 2018b)。
- 预先训练的LM在目标任务上微调,在Story Cloze Test和SWAG上实现了非常高的性能(Radford等,2018;Devlin等,2018)
(三)数据集生成
该数据集生成的一个重点是开发一种生成问题的方法,这些问题可以在没有上下文的情况下由人类轻松回答,且需要常识。生成选择题的过程概括如下:
- 从CONCEPTNET中提取子图,每个子图有一个源概念和三个目标概念。
- 要求众包工作者为每个子图编写三个问题(每个目标概念一个),为每个问题添加两个额外的干扰因素,并验证问题的质量。
- 通过查询搜索引擎和检索web片段为每个问题添加上下文。
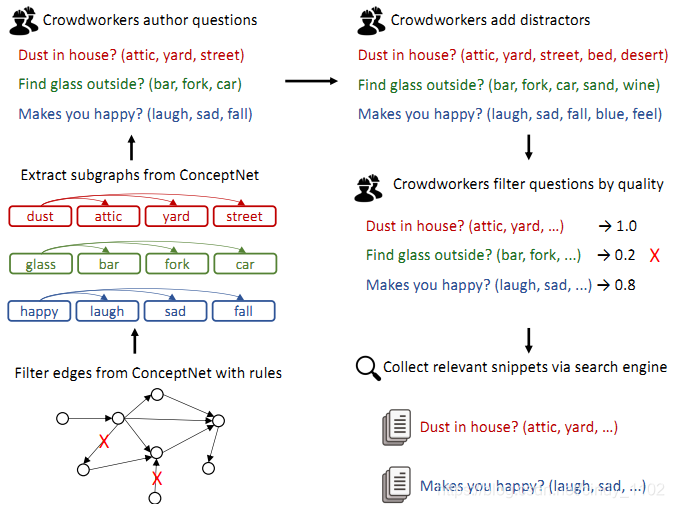
更具体地说,各个步骤的实现如下:
(1)CONCEPTNET提取过程
CONCEPTNET是一个图形知识库 G ⊆ C × R × C G\subseteq C\times R\times C G⊆C×R×C,其中节点C表示自然语言概念,边R表示常识关系。三元组 ( c 1 , r , c 2 ) (c_1,r,c_2) (c1,r,c2
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 4024
4024

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









