







Kaggle树叶分类Leaves Classify总结
前言
作为初学者,在Kaggle上获得了最高95.6%的识别准确率的一个及格成绩,本文作为总结和分享
Kaggle Classify Leaves竞赛地址

工具准备
pytorch可视化
使用Visdom进行数据可视化的操作
安装visdom
pip install visdom
或者到visdom的github下载后到根目录安装
https://github.com/fossasia/visdom
cd visdom
pip install -e .
在terminal输入以下命令启动visdom
visdom
或
python -m visdom.server
启动visdom后,如果出现
Downloading scripts, this may take a little while
请不要按照visdom服务启动时提示Downloading scripts, this may take a little while解决办法所说下载script替换,这样会导致server在浏览器打开后图像不会实时更新的问题
直接上梯子等一会就行
由于我是python3.8,所以会出现NotImplementedError
参照关于Python3.8运行Visdom.server抛出NotImplementedError异常的解决方法即可
成功启动后显示
Checking for scripts.
It's Alive!
INFO:root:Application Started
You can navigate to http://localhost:8097
在浏览器中输入http://localhost:8097即可打开

visdom例程
import torch
from torchvision.models import AlexNet
from torch.optim.lr_scheduler import CosineAnnealingLR
from visdom import Visdom
import time
visdom = Visdom()
# 创建一个初始点位为(0, 0),window句柄为test,标题为test的图像窗口
visdom.line(Y=[0], X=[0], win='test', opts=dict(title='test', legend=['test1', 'test2']))
numEpochs = 75
model = AlexNet(num_classes=2)
optimizer = torch.optim.Adam(model.parameters(), lr=0.1)
scheduler1 = CosineAnnealingLR(optimizer,T_max=numEpochs)
for epoch in range(numEpochs):
optimizer.zero_grad()
optimizer.step()
scheduler1.step()
updatedLearningRate1 = scheduler1.get_last_lr()[0]
# 将图像加入visdom
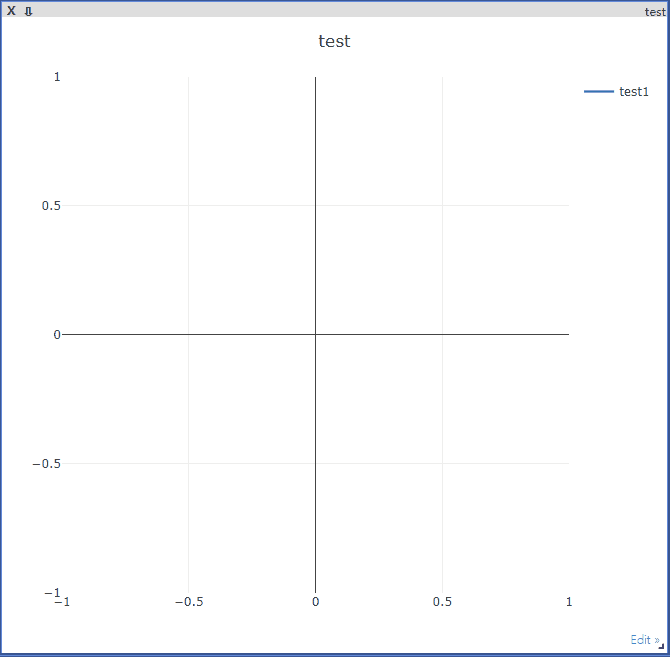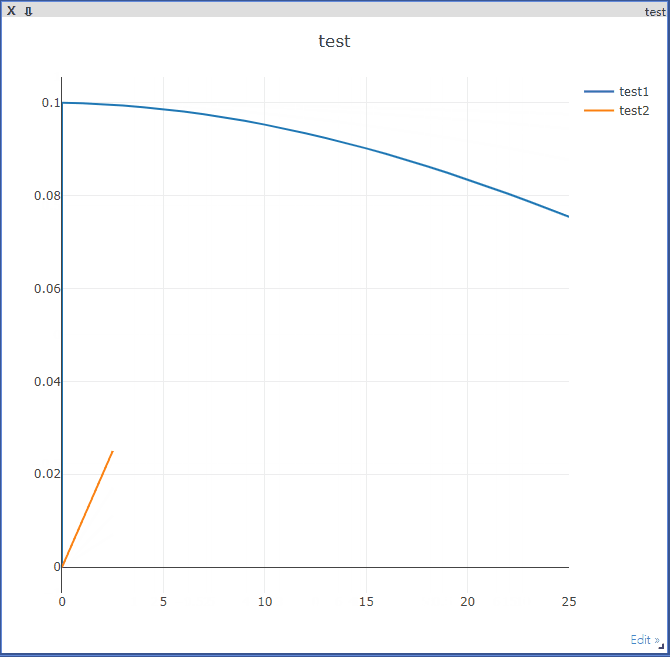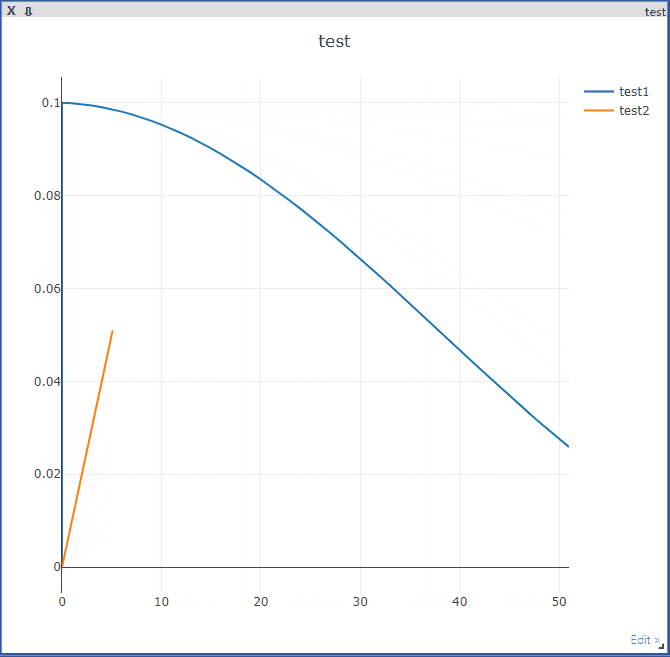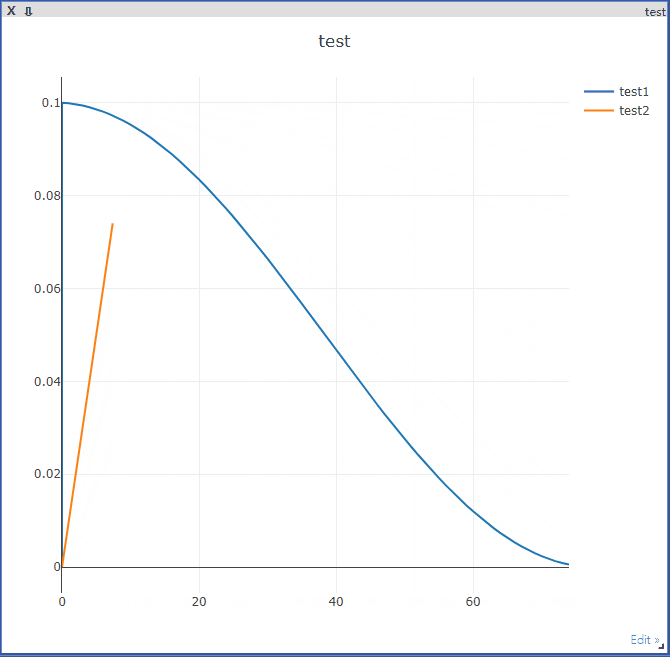
visdom.line(Y=[updatedLearningRate1], X=[epoch], win='test', update='append', name='test1') # name需要与legend对应
visdom.line(Y=[epoch*0.001], X=[epoch/10], win='test', update='append', name='test2')
time.sleep(0.1)
数据增强库
torchvision
具体请参照玩转pytorch中的torchvision.transforms
CutMix
pip install git+https://github.com/ildoonet/cutmix
程序预处理准备
创建树叶种类标签枚举体
import pandas as pd
# 树叶种类标签枚举体
leavesLabels = sorted(list(set(pd.read_csv('classify-leaves/train.csv')['label'])))
ELeavesLabels = dict(zip(leavesLabels, range(len(leavesLabels))))
# 类别数量
nClass = len(leavesLabels)
# 再转换回来,最后预测的时候使用
ELeavesLabelsInverse = {
}
for label, index in ELeavesLabels.items():
ELeavesLabelsInverse[index] = label
自定义Dataset
# 继承pytorch的dataset,创建自己的
class CLeavesData(Dataset):
def __init__(self, csv_path, file_path, mode='unknown', valid_ratio=0.2, transform=None):
"""
Args:
csv_path (string): csv 文件路径
file_path (string): 图像文件所在路径
mode (string): 训练模式还是测试模式
valid_ratio (float): 验证集比例
"""
self.file_path = file_path
self.mode = mode
self.transform = transform
# 读取 csv 文件
self.data_info = pd.read_csv(csv_path)
# 计算 数据长度和训练集长度
self.data_length = len(self.data_info.index) - 1
self.train_length = int(self.data_length * (1 - valid_ratio 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 929
929











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









