






1. 数据集准备与预处理
1.1 导入数据
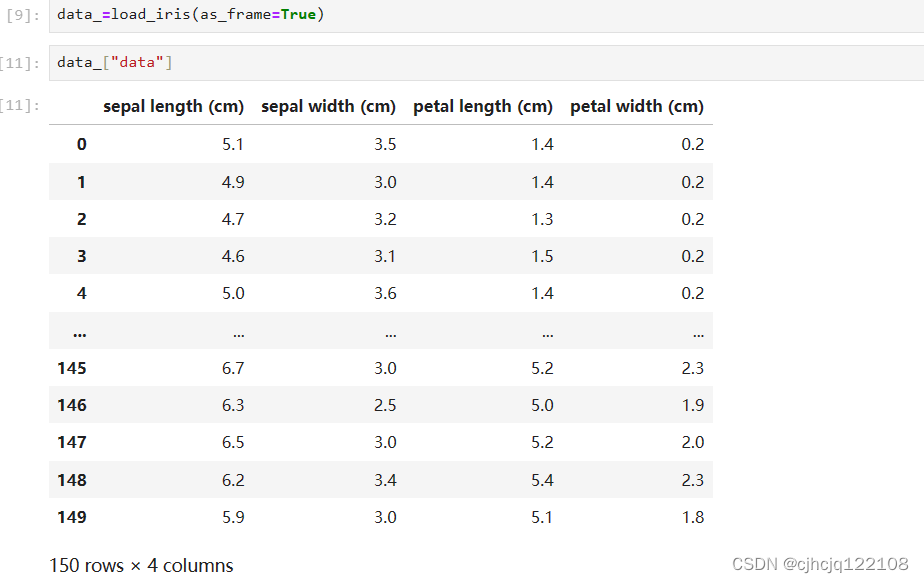
首先我们导入sklearn库中内置数据库,并将参数as_frame设置为True。这样jupyter中输出的格式好看点。返回值为字典,我们可以查看一下数据
1.2 查看缺失值情况
紧接着我们要查看数据是否存在缺失值的情况,可以使用pandas中的info函数

用同样的方法查看target,发现同样没有缺失值
1.3 查看数据分布情况
使用pd.value_counts查看数据分布情况,以决定是否需要调整数据权重,或者采用过采样,欠采样等方法进行处理

数据分布均匀,无需调整
1.4 构造额外特征
原始数据的特征只有4个,过少。我们可以构建额外的特征来增加特征数量。在经过初步训练和评估后,我们再对特征进行筛选。
我们决定构造sepal_size=sepal_lengthsepal_width,petal_size=petal_lengthpetal_width两个额外的特征。当然,也有许多其他的特征构造方法,例如:数据分层等等。但是由于这并不是完整的项目,所以只额外构造两个特征进行演示。

随后进行查看,已经成功插入
1.5 数据划分
随后我们对数据进行划分,可以采取pandas中的iloc方法

先查看类型,发现target是series类,所以不提供iloc方法。但是我们可以直接使用字符串切片操作。

2. 训练模型与验证集预测
调用sklearn中的决策树模型,使用fit函数进行训练,使用score函数进行验证集评估。发现正确率为83%。实际上,如果没有构造额外的特征的话,正确率仅有73%,之前尝试过。

同时,我们也可以通过feature_importances_查看特征重要度评估,惊喜的发现我们构建的petal_size特征居然起到了决定性的作用!(实际上,在原始的四个特征中petal的两个特征重要度最大)
3. 模型优化
如何才能使准确率更进一步呢?
3.1 使用集成算法
可以使用决策树的进阶版:随机森林(当然还有很多其他的算法,由于sklearn良好的封装习惯,基本上只要换一下名字就可以切换算法了)
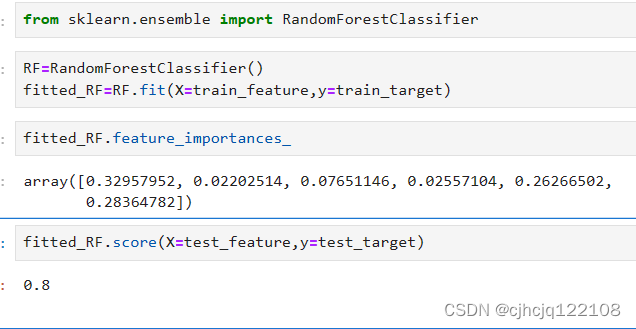
没想到的是,正确率反而下降了。。。不过可以看到集成算法可以对每一个特征都有所关照了。
这也许是好事,说明它考虑的更多。当然也可能是坏事:特征太杂,被污染了。
3.2 筛选特征
上面我们提出了一个猜测“特征太杂,被污染了”。这里我们来试试删除一些特征,看看结果会如何。
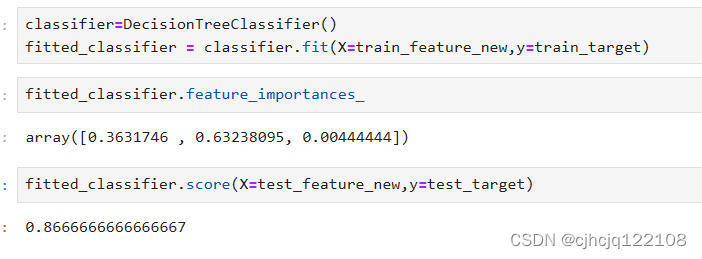
根据之前的重要度,我们决定删去所有与sepal有关的特征。

随后开始训练,结果如下

好了,但是和使用决策树效果差不多。。。
我们再拿决策树试试,发现效果更好了一点(合着随机森林比不过决策树是吧)
4. 模型可视化
4.1 调用tree.plot函数

效果如下:
















 583
583











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









