








比赛简介
本次比赛的目的是评估 3-12 年级学生撰写的摘要的质量。您将构建一个模型,用于评估学生对源文本的主要思想和细节的表达程度,以及摘要中使用的语言的清晰度、准确性和流畅性。你将有权访问一组真实的学生摘要来训练你的模型。
您的工作将帮助教师评估学生作业的质量,并帮助学习平台为学生提供即时反馈。
摘要写作是所有年龄段学习者的一项重要技能。总结可以增强阅读理解能力,特别是在第二语言学习者和有学习障碍的学生中。摘要写作还可以促进批判性思维,这是提高写作能力的最有效方法之一。然而,学生很少有足够的机会练习这项技能,因为对摘要进行评估和提供反馈对教师来说可能是一个耗时的过程。大型语言模型(LLM)等创新技术可以帮助改变这种状况,因为教师可以使用这些解决方案来快速评估摘要。
学生写作的自动评估取得了进步,包括议论文或叙事写作的自动评分。然而,这些现有的技术并不能很好地转化为摘要写作。评估摘要引入了额外的复杂性,其中模型必须同时考虑学生的写作和单个较长的源文本。尽管目前有一些用于摘要评估的技术,但这些模型通常侧重于评估自动生成的摘要而不是真正的学生写作,因为历史上缺乏这些类型的数据集。
竞赛主办方CommonLit是一家非营利性教育技术组织。CommonLit 致力于确保所有学生,尤其是 Title I 学校的学生,在毕业时具备在大学及以后取得成功所需的阅读、写作、沟通和解决问题的技能。学习机构实验室、范德比尔特大学和佐治亚州立大学与 CommonLit 一起完成这一使命。
由于您帮助开发汇总评分算法,教师和学生都将获得促进这一基本技能的宝贵工具。学生将有更多机会练习总结,同时提高他们的阅读理解、批判性思维和写作能力。
评估方法
提交使用 MCRMSE 评分,均值按列均方根误差:

N
t
N_{t}
Nt 是得分的 ground truth 目标列的数量,并且y和
y
^
\hat{y}
y^分别是实际值和预测值。
对于测试集中的每一个,必须预测两个分析度量中每个值(如“数据”页上所述)。该文件应包含标头student_id并具有以下格式:
student_id,content,wording
000000ffffff,0.0,0.0
111111eeeeee,0.0,0.0
222222cccccc,0.0,0.0
333333dddddd,0.0,0.0
...
数据描述
该数据集包括大约 24,000 个由 3-12 年级学生撰写的关于各种主题和体裁的段落摘要。这些摘要在内容和措辞方面都打分。比赛的目标是预测未见过的主题摘要的内容和措辞分数。
文件和字段信息
summaries_train.csv - 训练集中的摘要。
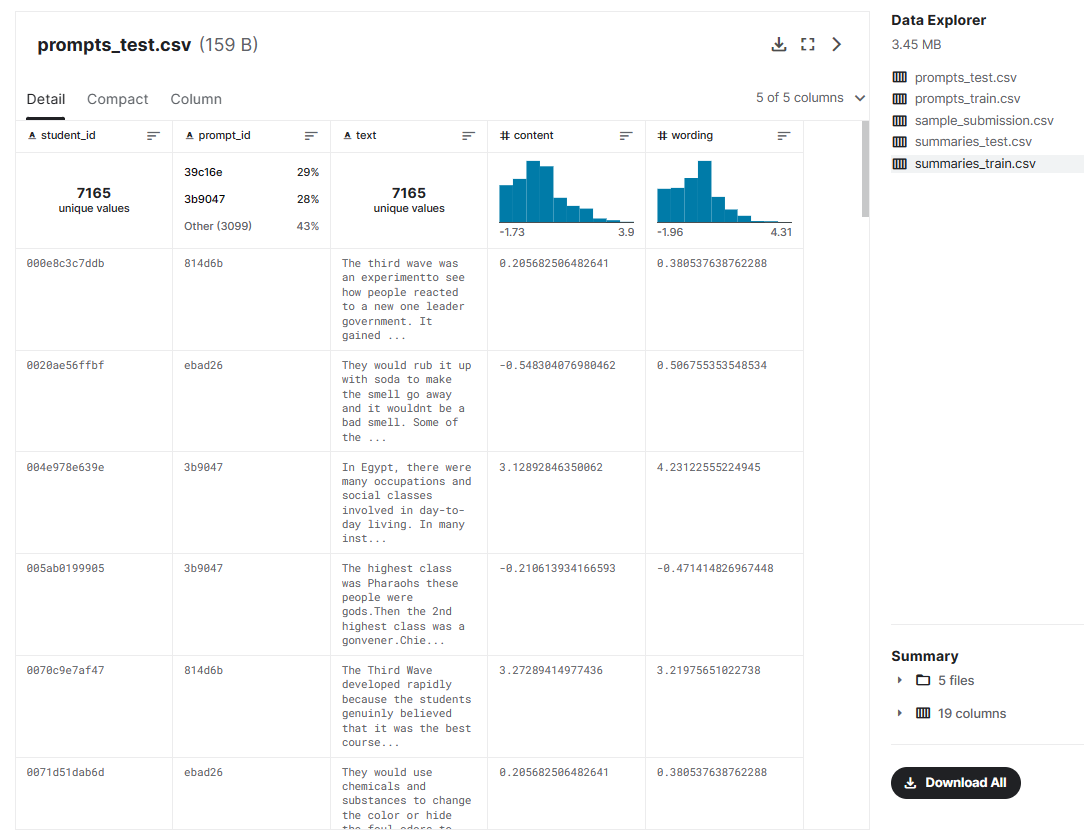
student_id- 学生的ID。prompt_id- 链接到提示文件的提示的 ID。text- 学生总结的全文。content- 摘要的内容分数。第一个目标。wording- 摘要的措辞分数。第二个目标。
summaries_test.csv - 测试集中的摘要。包含除content和wording之外的所有上述字段。
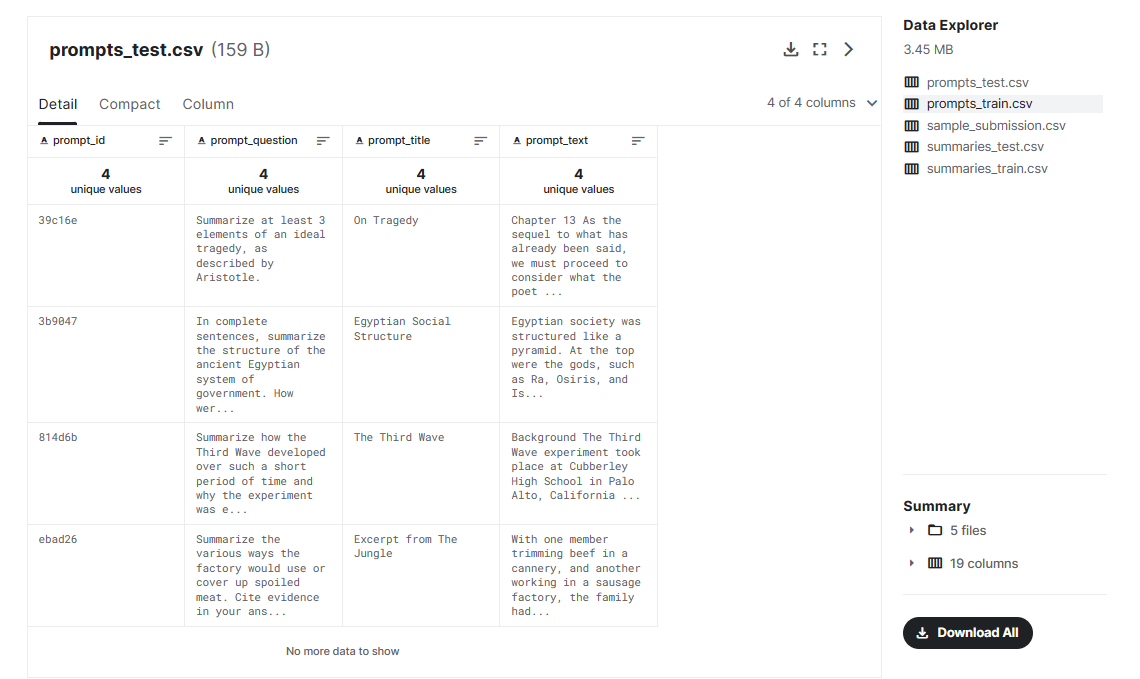
prompts_train.csv - 四个训练集提示。每个提示都包括给学生的完整总结作业。
prompt_id- 链接到摘要文件的提示的 ID。prompt_question- 要求学生回答的具体问题。prompt_title- 提示的简写标题。prompt_text- 完整的提示文本。
prompts_test.csv - 测试集提示。包含与上述相同的字段。此处的提示只是一个示例。完整的测试集具有大量提示。
sample_submission.csv - 格式正确的提交文件。
















 45万+
45万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











