







一、Cookies
使用场景:爬取数据需要登录时,保存cookies后可以跳过登录。
import json
import os
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.action_chains import ActionChains
#基础驱动环境配置
driver = webdriver.Chrome('./driverfile/chromedriver')
#登录bilibili
def loginBilili():
#打开网站
driver.get("https://www.bilibili.com")
#窗口最大化
driver.maximize_window()
#定位登录元素框
driver.find_element(By.CLASS_NAME,'header-login-entry').click()
time.sleep(3)
#输入账号密码
driver.find_element(By.XPATH,'/html/body/div[3]/div/div[2]/div[3]/div[2]/div[1]/input').send_keys("账号")
driver.find_element(By.XPATH,'/html/body/div[3]/div/div[2]/div[3]/div[2]/div[2]/div[1]/input').send_keys("密码")
time.sleep(3)
#点击登录
driver.find_element(By.CLASS_NAME,"login-btn").click()
#强人工智能(手动一下验证码)这里可以用opencv或者
#存储cookies
save_cookies(driver)
def save_cookies(driver):
#获取当前文件路径
project_path = os.path.dirname(os.getcwd())
file_path = project_path + "/selempro/cookies/"
if not os.path.exists(file_path):
os.mkdir(file_path)
cookies = driver.get_cookies()
with open(file_path + "bilibili.cookies","w") as c:
json.dump(cookies,c)
print(cookies)
def get_url_with_cookies():
project_path = os.path.dirname(os.getcwd())
file_path = project_path + "/selempro/cookies/"
print(file_path)
cookies_file = file_path + "bilibili.cookies"
#读取cookies
bili_cookies_file = open(cookies_file,'r')
bili_cookies_str = bili_cookies_file.readline()
#加载cookies信息,转成json格式
bili_cookies_dict = json.loads(bili_cookies_str)
print(bili_cookies_dict)
#清除掉旧的cookies
driver.get("https://www.bilibili.com")
driver.delete_all_cookies()
#将本地cookies加入到driver中
for cookies in bili_cookies_dict:
print(cookies)
driver.add_cookie(cookies)
driver.get("https://space.bilibili.com/437122003?spm_id_from=333.1007.0.0")
get_url_with_cookies()
# #调用登录方法
# loginBilili()
可以使用cookies进行b站自动签到啦~~~
二、JS
2.1、利用JS修改标签的属性,方便操作
关键代码:【这里需要看看js操作标签的语法】
js = "$('input[id=train_date]').removeAttr('class')"
driver.execute_script(js)
__author__ = "chen"
__date__ = "2022年06月21日15:02:30"
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
import time
def search_12306():
driver = webdriver.Chrome("./driverfile/chromedriver")
driver.get("https://www.12306.cn/index/")
from_element = driver.find_element(By.ID,"fromStationText")
time.sleep(1)
from_element.click()
time.sleep(1)
from_element.send_keys("广州")
driver.find_element(By.XPATH,"//*[@id='citem_2']").click()
time.sleep(1)
arrive_element = driver.find_element(By.ID,"toStationText")
time.sleep(1)
arrive_element.click()
arrive_element.send_keys("汉中")
driver.find_element(By.XPATH,"//*[@id='citem_0']").click()
time.sleep(2)
#点击空白处
driver.find_element(By.CLASS_NAME,"search-main-item").click()
#js修改标签属性
js = "$('input[id=train_date]').removeAttr('class')"
driver.execute_script(js)
date_element = driver.find_element(By.ID,"train_date")
time.sleep(2)
date_element.click()
time.sleep(1)
date_element.clear()
date_element.send_keys("2022-06-21")
driver.find_element(By.CLASS_NAME,"search-main-item").click()
time.sleep(1)
driver.find_element(By.ID,"search_one").click()
time.sleep(5)
driver.quit()
search_12306()
三、Xpath
直接查文档进行回顾
XPath 教程![]() https://www.w3school.com.cn/xpath/index.aspXPath 教程 | 菜鸟教程XPath 教程 XPath 是一门在 XML 文档中查找信息的语言。 XPath 是 XSLT 中的主要元素。 XQuery 和 XPointer 均构建于 XPath 表达式之上 现在开始学习 XPath ! XPath 参考手册 在菜鸟教程,我们提供完整的 XPath 2.0、XQuery 1.0 和 XSLT 2.0 的内置函数参考手册。 XPath 函数 内容列表 XPath 介绍 本章讲解 XPath 的概念..
https://www.w3school.com.cn/xpath/index.aspXPath 教程 | 菜鸟教程XPath 教程 XPath 是一门在 XML 文档中查找信息的语言。 XPath 是 XSLT 中的主要元素。 XQuery 和 XPointer 均构建于 XPath 表达式之上 现在开始学习 XPath ! XPath 参考手册 在菜鸟教程,我们提供完整的 XPath 2.0、XQuery 1.0 和 XSLT 2.0 的内置函数参考手册。 XPath 函数 内容列表 XPath 介绍 本章讲解 XPath 的概念..
谷歌插件:XPath Helper
开发者工具:console面板
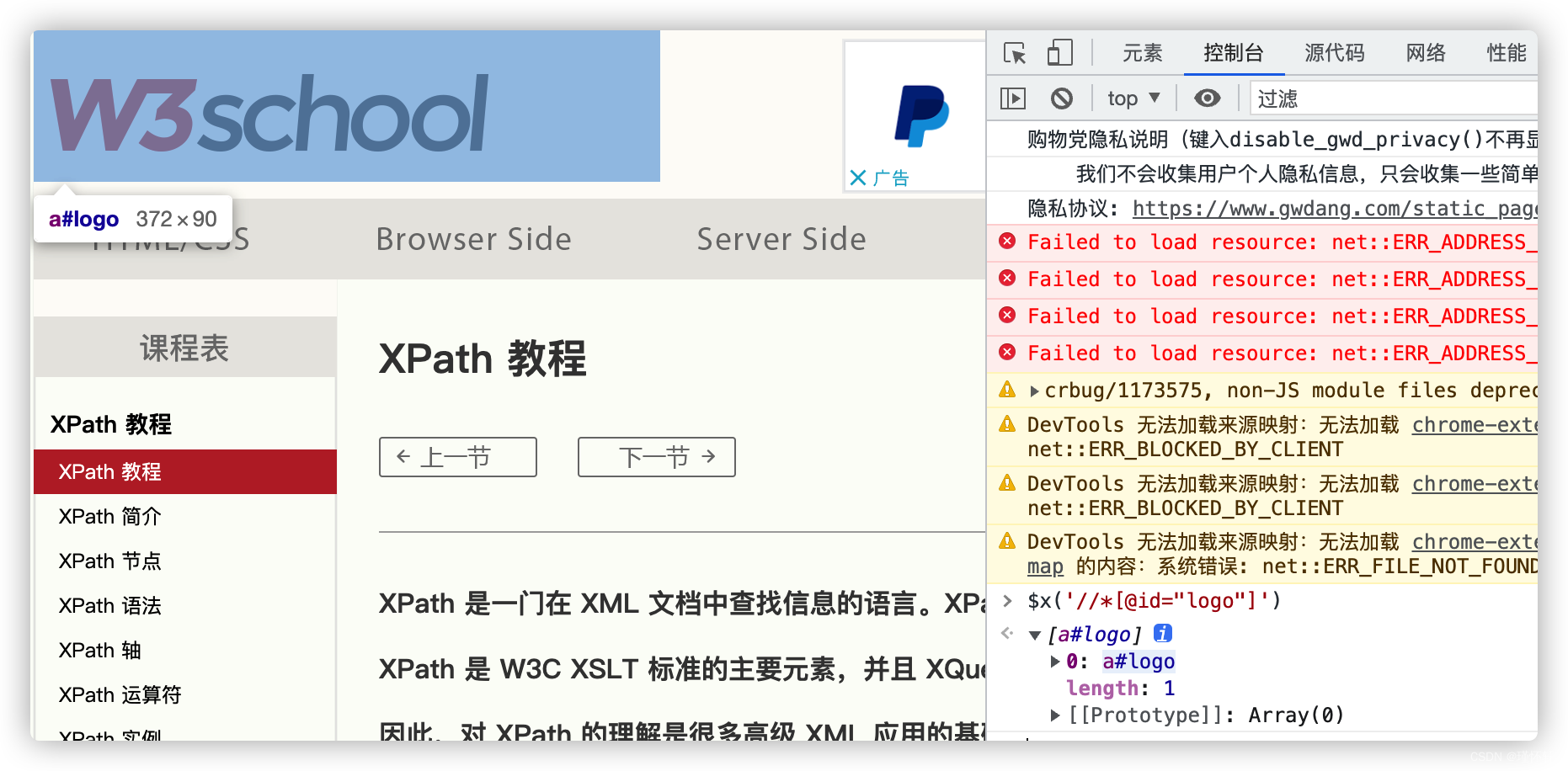
css Selector
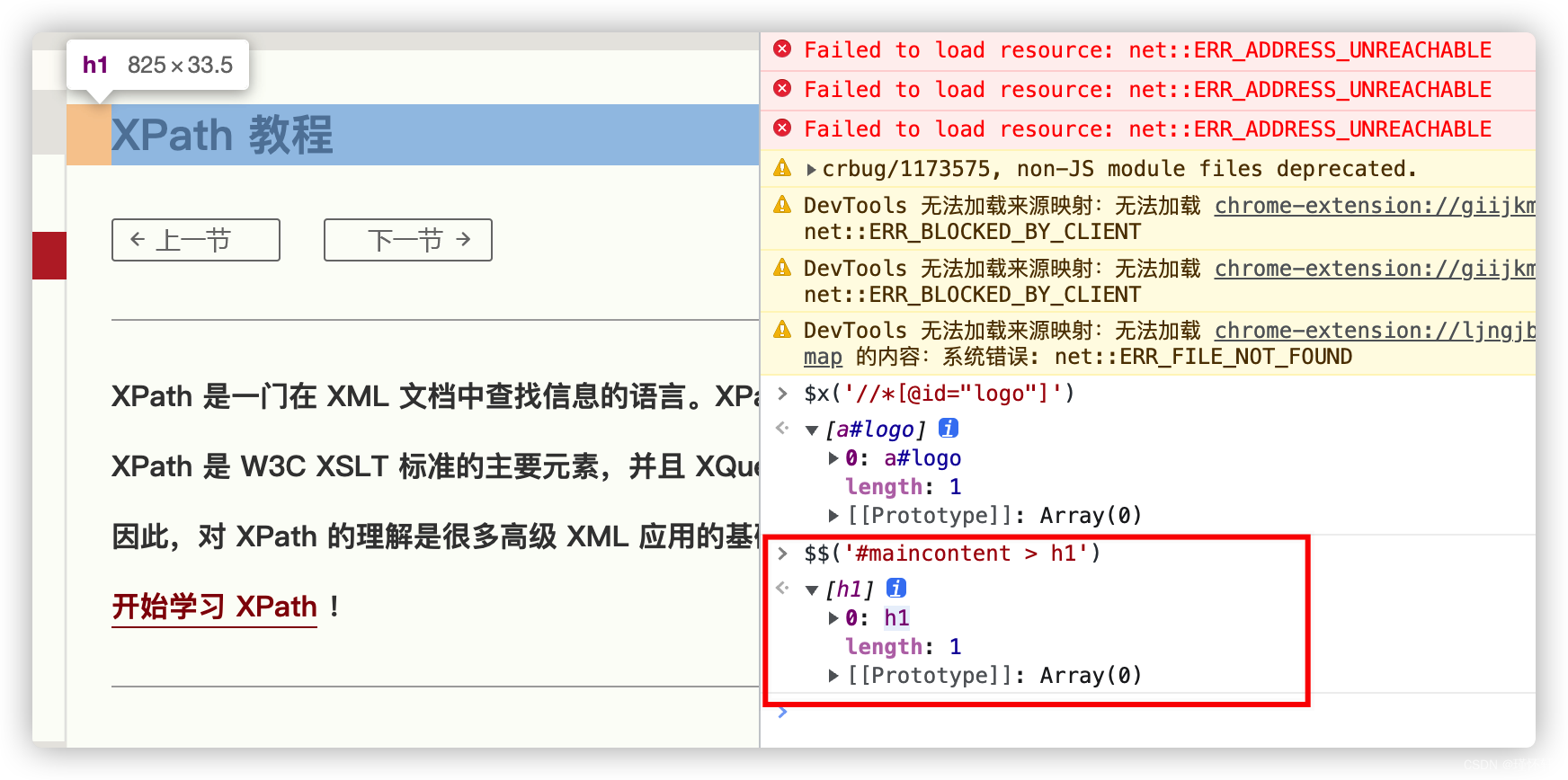
xpath语法
节点语法:
| 表达式 | 描述 |
|---|---|
| nodename | 选取此节点的所有子节点。 |
| / | 从根节点选取(取子节点)。 |
| // | 从匹配选择的当前节点选择文档中的节点,而不考虑它们的位置(取子孙节点)。 |
| . | 选取当前节点。 |
| .. | 选取当前节点的父节点。 |
| @ | 选取属性。 |
谓语语法
谓语: '//div[not(@*)]'
'//*[count(li)=2]' 选择含有两个li的元素
'//*[name()="li"]' ~'//li'
| 路径表达式 | 结果 |
|---|---|
| /bookstore/book[1] | 选取属于 bookstore 子元素的第一个 book 元素。 |
| /bookstore/book[last()] | 选取属于 bookstore 子元素的最后一个 book 元素。 |
| /bookstore/book[last()-1] | 选取属于 bookstore 子元素的倒数第二个 book 元素。 |
| /bookstore/book[position()<3] | 选取最前面的两个属于 bookstore 元素的子元素的 book 元素。 |
| //title[@lang] | 选取所有拥有名为 lang 的属性的 title 元素。 |
| //title[@lang='eng'] | 选取所有 title 元素,且这些元素拥有值为 eng 的 lang 属性。 |
| /bookstore/book[price>35.00] | 选取 bookstore 元素的所有 book 元素,且其中的 price 元素的值须大于 35.00。 |
| /bookstore/book[price>35.00]//title | 选取 bookstore 元素中的 book 元素的所有 title 元素,且其中的 price 元素的值须大于 35.00。 |
未知节点
| 通配符 | 描述 |
|---|---|
| * | 匹配任何元素节点。 |
| @* | 匹配任何属性节点。 |
| node() | 匹配任何类型的节点。 |
选取若干路径
| 路径表达式 | 结果 |
|---|---|
| //book/title | //book/price | 选取 book 元素的所有 title 和 price 元素。 |
| //title | //price | 选取文档中的所有 title 和 price 元素。 |
| /bookstore/book/title | //price | 选取属于 bookstore 元素的 book 元素的所有 title 元素,以及文档中所有的 price 元素。 |
四、Css Selector
CSS 选择器参考手册 http://caibaojian.com/w3c/cssref/css_selectors.htmlCss Selector 和 Xpath可以对应
http://caibaojian.com/w3c/cssref/css_selectors.htmlCss Selector 和 Xpath可以对应

小知识点:
将当前环境整理依赖文件
pip freeze >requirements.txt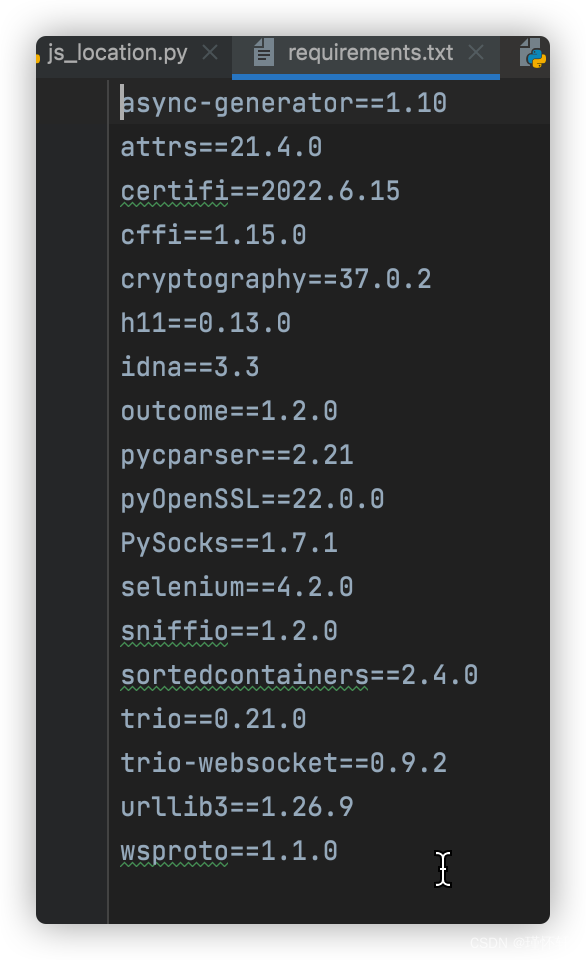
安装:
pip install -r requirements.txt
















 2108
2108











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











