







 本文介绍CenterFace,一种基于mobilenetV2的轻量级人脸检测算法,对比ObjectsasPoints,采用判断特征图上的点是否为目标中心点,并计算目标框的宽和高。文章详细解释了其网络结构、groundtruth定义、LOSS定义及数据增强方法。
本文介绍CenterFace,一种基于mobilenetV2的轻量级人脸检测算法,对比ObjectsasPoints,采用判断特征图上的点是否为目标中心点,并计算目标框的宽和高。文章详细解释了其网络结构、groundtruth定义、LOSS定义及数据增强方法。
论文地址:https://arxiv.org/ftp/arxiv/papers/1911/1911.03599.pdf
github地址:https://github.com/Star-Clouds/centerface
此篇文章是参考的Objects as Points,在此附上Objects as Points的论文地址:
Objects as Points
核心思想,相比于Anchor的检测算法,去判断每个anchor是否包含需检测的目标,再去计算回归的offset,Centerface和Objects as Points的主要思想是,判断feature map对应在图像中的位置是否是目标的中心点,再去计算目标的宽和高。
因为此文主要借鉴Objects as Points,而关于Objects as Points的解读已经有很多了,所以与Objects as Points差异较小的地方,笔者会简略带过。
网络结构
因为CenterFace是轻量级的人脸检测器,所以其backbone用的是mobilenetV2,相比于Objects as Points采用的DLA 以及Hourglass,整体的backbone很小。网络结构可视化如下:
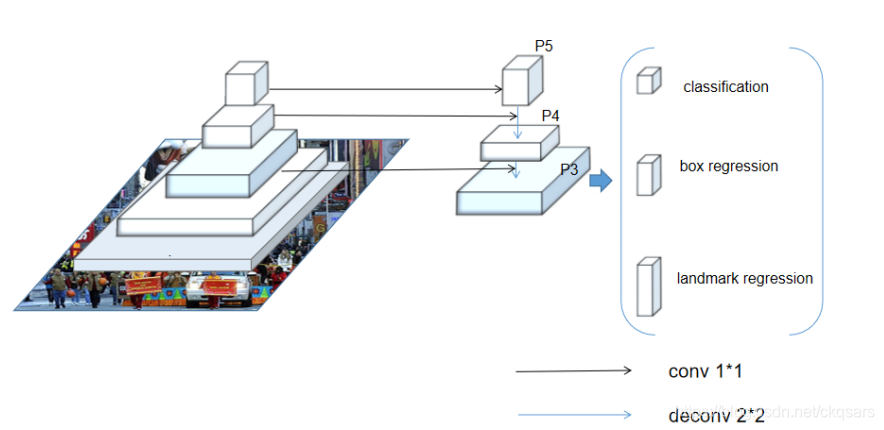
groundtruth的定义
目标中心点定义:在一般的目标检测中,一般记录目标的(
x
1
x_1
x1,
y
1
y_1
y1,
x
2
x_2
x2,
y
2
y_2
y2),对应目标的左上角和右下角的坐标。目标的中心点:
x
c
=
(
x
1
+
x
2
)
/
2
,
y
c
=
(
y
1
+
y
2
)
/
2
x_c=(x_1 + x_2)/2, y_c=(y_1 +y_2)/2
xc=(x1+x2)/2,yc=(y1+y2)/2。
在使用anchor的算法中,采用的是计算anchor和groundtruth之间的IOU,若IOU大于阈值,则为正样本,若小于阈值,则为负样本。
在centerface中,是计算中心点的坐标是否在feature map所对应的图像内。
x
~
c
=
⌊
x
c
R
⌋
,
y
~
c
=
⌊
y
c
R
⌋
\widetilde{x}_c=\lfloor\frac{x_c}{R}\rfloor,\widetilde{y}_c=\lfloor\frac{y_c}{R}\rfloor
x
c=⌊Rxc⌋,y
c=⌊Ryc⌋R就是对应的步长。中心点所在的feature map为1,对于标注,采用高斯的方式向外撒点。
LOSS的定义
在寻找关键点上,存在两个loss,一个是判断feature map是否包含关键点,采用focal loss,另一个是计算关键点 相对于 feature map映射到原图之后的偏移量,使用的smooth_L1。
在计算目标框上:区别于Objects as Points, 计算的是映射到feature map上的大小,而不是计算原图的大小
w
^
=
l
o
g
(
x
2
−
x
1
R
)
,
h
^
=
l
o
g
(
y
2
−
y
1
R
)
\hat{w}=log(\frac{x_2-x_1}{R}), \hat{h}=log(\frac{y_2-y_1}{R})
w^=log(Rx2−x1),h^=log(Ry2−y1)
计算目标框的Loss采用smooth_L1
Data augmentation
1.random filp
2.random scaling
3.color jittering
4.randomly crop square patch
以上数据增强方法都是常见的数据增强方法,不多做介绍。
测试结果
在arm端测试结果:
| 模型 | 速度 |
|---|---|
| CenterFace | 1200ms |
widerface测试结果
| easy | Medium | hard |
|---|---|---|
| 92.2 | 91.1 | 77.9 |

















 6374
6374

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









