










该论文发表于2017CVPR,由北理工+旷视科技+北大共同完成
论文传送门
本人主要借鉴其中的思想在目标检测中的可行性,故不考虑语义分割相关的内容
初次实现,如有不足之处,还请指出,谢谢!
名词解释
- Global contextual information: 译为中文即为全局语义信息,即图像中的物体并不是孤立的,像素之间都是有联系的,这种联系就是语义信息,而全局语义信息是从图像全局的像素之间的联系,以下面的图为例[1],“盲人摸象”的典故能够很形象地说明全局语义信息的重要性。

图 1.a 从这一小块区域,无法判断出其所在的整张图片的类别
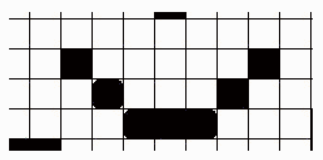
图 1.b 从另一小块区域,同样无法判断其所在的整张图片的类别

图 1.c 稍微扩大一下小块区域的范围,同样无法判断出这张图片所属的类别

图 1.d 当看到了全局的信息,我们可以很肯定的给这张图片一个类别
- Global Average pooling: 全局平均池化,将张量[C, H, W]变为[C, 1, 1],用来获取全局语义信息。如下图:[2]

- Dilated convolution: 空洞卷积,广泛应用于图像分割和目标检测任务中,可以看作是标准卷积的一种特殊形式,可以通过在卷积核中插入0或者对输入等间隔采样来实现,具体过程以图为例:

- 扩大感受野:在不丢失特征分辨率的情况下扩大感受野,扩大感受野对于检测大物体有好处。
- 捕获多尺度上下文信息:通过调整扩张率(dilation rate)获得多尺度信息。
其中不丢失特征分辨率的情况下扩大感受野的意思是:在非空洞卷积中,要想扩大感受野,必须通过下采样的方式进行(可以通过pooling或者标准卷积),这样一来必定会造成空间分辨率的降低,以下图为例[3]:

左图0-9为10个像素,左侧是对这10个像素进行标准卷积的过程,标准卷积核的大小为
3
×
3
3\times3
3×3,步长为1,padding为1,stride为1得到绿色特征,绿色特征的分辨率没有减小,此时绿色特征对应的感受野为
3
×
3
3\times3
3×3,然后绿色特征再次经过标准卷积
3
×
3
3\times3
3×3得到黄色特征,黄色特征的分辨率减小了,此时黄色特征对应的感受野为
5
×
5
5\times5
5×5;右图对应的是空洞卷积,卷积核为
3
×
3
3\times3
3×3,步长为1,dilated rate为2,得到绿色特征,绿色特征分辨率没有减小,此时绿色特征对应的感受野为
5
×
5
5\times5
5×5,由此可以看到,空洞卷积的分辨率和作图的绿色特征分辨率相同的情况下,其感受野要比左图的绿色特征的感受野有所扩大,而作图要想拥有和右图相同大小的感受野,则需要损失分辨率(黄色特征)
其中能够捕获多尺度上下文信息的意思是:通过调整扩张率可以改变感受野的大小,不同大小的感受野可以感受不同尺度信息的物体。
摘要
这篇论文提出了Pyramid Attention Network(PAN),用于探究全局上下文信息在语义分割中的重要性,结合注意力机制和空间金字塔提取用于像素分类的特征。主要的贡献就是提出了两个重要结构模块。(1)Feature Pyramid Attention模块:在高层语义特征的基础上连接空间金字塔注意力结构,增大感受野,获取不同尺度的上下文信息,并结合全局池化特征,从高层语义信息中学习更加有用的表示。(2)Global Attention Upsample模块:应用于每个解码层,将全局信息作为指导,指导低水平特征选择更加有利于定位的细节信息,逐步恢复细节信息。
引言
随着卷积神经网络的发展,我们可以利用卷积神经网络的层级结构以及端到端的训练方式,提取出丰富的层级特征,这种方式推动了语义分割的发展进步。然而,在对高维特征进行编码的时候,特征分辨率会发生损失,我们主要考虑两个问题:
- 多尺度物体的存在会对分类造成困难。为了解决这个问题,PSPNet进行不同尺度的空间金字塔池化,而空间金字塔池化的过程中会损失定位的细节信息;DeepLab使用空洞卷积,而空洞卷积会导致棋盘格效应。本研究受SENet和Parsenet的启发,提出FPA模块,FPA模块通过增加感受野,捕获不同尺度的语义信息。
- 高水平特征利于分类,但在重建原始分辨率方面存在缺陷。为了解决这个问题,一些U形结构的网络被提出,比如SegNet, Refinenet以及提拉米苏结构提出复杂的解码模块,使用低水平特征来帮助高水平特征恢复细节信息。然而,结构复杂必然导致计算耗时。于是本研究提出更加有效的GAU模块,该模块利用高层语义信息作为指导,指导低水平特征选取细节信息,并进行融合,逐步恢复细节信息,这也是一种有效的解码模块。
相关研究
目前的研究主要集中于探索能够更好地利用上下文信息的网络结构。本文将这些研究主要分为三大类:
- Encoder-decoder结构:SOTA的分割方法主要基于这种结构,然而大部分方法都是试图直接融合相邻层的特征来加强低水平特征的语义信息,却没有考虑不同层特征的多样性以及全局上下文信息。具体体现为不应该直接融合,而应该考虑重要性;还应该考虑全局上下文信息,仅各层特征可能会“一叶障目”。
- Global Context Attention:受ParseNet的启发,许多方法都使用global branch来利用全局上下文信息。本研究也同样在FPA模块中使用global branch以从多尺度特征表示中对特征进行选取。
- Spatial Pyramid: 用于获取多尺度上下文信息,但是计算量大。
方法
Feature Pyramid Attention模块
动机 受注意力机制的启发,考虑为高层特征提供像素级注意力。目前的研究缺乏全局语义信息作为指导;并且类似SENet模块的结构在通道注意力方面并不能对多尺度信息进行选择。鉴于此,提出FPN模块,对高层特征执行不同大小卷积核的卷积运算,提取不同尺度的信息;然后逐步对不同尺度的信息进行融合,这样可以更加准确地对相邻的上下文信息进行整合;接下来将经过 1 × 1 1\times1 1×1卷积的高层特征和融合后的注意力特征进行相乘;最后再和全局语义信息进行相加。

代码实现:
class ConvGnRelu(nn.Module):
"""
作用:
FPA模块中的Conv层,论文使用的是BN,我自己用的是GN
参数:
in_channel: 输入通道数
out_channel: 输出通道数
kernel_size
stride
padding
返回:
输出的特征张量
"""
def __init__(self, in_channel, out_channel, kernel_size=3, stride=1, padding=0):
super(ConvGnRelu, self).__init__()
self.conv = nn.Sequential(
nn.Conv2d(in_channel, out_channel,
kernel_size=kernel_size,
stride=stride,
padding=padding),
nn.GroupNorm(32, out_channel),
nn.ReLU(inplace=True)
)
def forward(self, x):
out = self.conv(x)
return out
class FPAModule(nn.Module):
"""
作用:
构造FPA模块
参数:
in_channel: 输入通道数
out_channel: 输出通道数
返回:
FPA输出特征
"""
def __init__(self, in_channel, out_channel):
super(FPAModule, self).__init__()
mid_channel = int(in_channel / 4)
self.global_branch = nn.Sequential(
nn.AdaptiveAvgPool2d(1),
ConvGnRelu(in_channel, out_channel,
1, 1, 0)
)
self.middle_branch = ConvGnRelu(in_channel, out_channel, 1, 1, 0)
self.down1 = nn.Sequential(
nn.MaxPool2d(kernel_size=2, stride=2),
ConvGnRelu(in_channel, mid_channel,
7, 1, 3))
self.down2 = nn.Sequential(
nn.MaxPool2d(kernel_size=2, stride=2),
ConvGnRelu(mid_channel, mid_channel,
5, 1, 2))
self.down3 = nn.Sequential(
nn.MaxPool2d(kernel_size=2, stride=2),
ConvGnRelu(mid_channel, mid_channel,
3, 1, 1),
ConvGnRelu(mid_channel, mid_channel, 3, 1, 1))
self.conv1 = ConvGnRelu(mid_channel, mid_channel, 7, 1, 3)
self.conv2 = ConvGnRelu(mid_channel, mid_channel, 5, 1, 2)
self.conv3 = ConvGnRelu(mid_channel, out_channel, 1, 1, 0)
self.relu = nn.ReLU(inplace=True)
def forward(self, x):
h, w = x.size(2), x.size(3)
b1 = self.global_branch(x)
b1 = F.interpolate(b1, size=(h, w), mode="bilinear", align_corners=True)
middle = self.middle_branch(x)
# branch1
x1_1 = self.down1(x)
x1_2 = self.conv1(x1_1)
# branch2
x2_1 = self.down2(x1_1)
x2_2 = self.conv2(x2_1)
# branch3
x3_2 = self.down3(x2_1)
# merge branch1 and branch2
x3_up = F.interpolate(x3_2, size=(h//4, w//4), mode="bilinear", align_corners=True)
x2_merge = self.relu(x2_2 + x3_up)
x2_up = F.interpolate(x2_merge, size=(h//2, w//2), mode="bilinear", align_corners=True)
x1_merge = self.relu(x1_2 + x2_up)
x1_up = F.interpolate(x1_merge, size=(h, w), mode="bilinear", align_corners=True)
x1_up = self.conv3(x1_up)
x_middle = middle * x1_up
out = self.relu(b1 + x_middle)
return out
Global Attention Upsample模块
目前的研究比如PSPNet和Deeplab都是直接在解码的时候使用上采样,而这种直接的方式缺乏多尺度信息的参与,这对于细节信息的恢复无益;虽然有些考虑了不同尺度的信息,但是又缺乏高层语义信息的指导。所以本研究提出了GAU模块,两大优点:
- 有效利用多尺度信息
- 使用高层语义信息对底层信息进行指导,选取更加准确的细节信息

细节信息 低水平特征经过
3
×
3
3\times3
3×3卷积改变通道数;高水平特征通过GAP得到全局上下文信息,然后全局信息经过
1
×
1
1\times1
1×1卷积,BN和ReLU,这一步也改变了通道数,然后和经过
3
×
3
3\times3
3×3卷积的低水平特征进行相乘,这样就相当于利用全局信息对低水平特征进行了加权的操作;最后,高水平特征经过上采样和加权后的低水平特征进行融合。
代码实现:
# GAU模块中所使用的3x3卷积层
class ConvGn(nn.Module):
def __init__(self, in_channel, out_channel):
super(ConvGn, self).__init__()
self.conv = nn.Sequential(
nn.Conv2d(in_channel, out_channel,
kernel_size=3, stride=1,
padding=1),
nn.GroupNorm(32, out_channel))
def forward(self, x):
out = self.conv(x)
return out
# GAU模块中高层特征全局语义信息的1x1卷积层
class ConvGnRelu(nn.Module):
def __init__(self, in_channel, out_channel):
super(ConvGnRelu, self).__init__()
self.conv = nn.Sequential(
nn.Conv2d(in_channel, out_channel,
kernel_size=1, stride=1,
padding=0),
nn.GroupNorm(32, out_channel),
nn.ReLU(inplace=True))
def forward(self, x):
out = self.conv(x)
return out
# GAU模块
class GAUModule(nn.Module):
def __init__(self, in_channel, out_channel):
super(GAUModule, self).__init__()
# 全局信息获取
self.layer1 = nn.Sequential(
nn.AdaptiveAvgPool2d(1),
ConvGnRelu(out_channel, out_channel))
# 底层特征3x3卷积改变通道数
self.layer2 = ConvGn(in_channel, out_channel)
def forward(self, x, y):
low_feature = self.layer2(x)
global_context = self.layer1(y)
weighted_low_feature = low_feature * global_context
high_feature = F.interpolate(y, x.shape[-2:], mode="bilinear", align_corners=True)
return weighted_low_feature + high_feature
Pyramid Attention Network(PAN)
最后将FPA模块和GAU模块进行组合,就得到最后的PAN网络结构。具体的组合方式为:利用FPA模块从高层特征中提取不同尺度的上下文信息;然后利用GAU模块将全局信息作为指导,指导低水平特征进行更好的细节选择。

以上图为例,按照这种方式进行组合即可。而结合我的具体情况,我是要研究其在目标检测中的使用,为了能将其嵌入到Faster R-CNN网络中替换掉FPN结构,我编写代码以适应自己的研究,核心代码如下:
class PANModule(nn.Module):
"""
作用:
接受来自C2,C3,C4,C5的特征{C2:Tensor, C3:Tensor, C4:Tensor, C5:Tensor}
输出经过融合以后的各层特征,例如为{P2:Tensor, P3:Tensor, P4:Tensor, P5:Tensor}
Note: 该模块所输出的特征将进入Bottom_up模块中(Bottom_up模块是我研究中的模块)
参数:
in_channels_list: 输入特征的通道数
out_channel: PANModule模块每层的输出通道数,即P2,P3,P4,P5的通道数,一般来说我设置为相同的256
输出:
out: 是个OrderedDict,形如{P2: Tensor, P3: Tensor, P4: Tensor, P5: Tensor}
"""
def __init__(self, in_channels_list, out_channel):
super(PANModule, self).__init__()
# 为了消除融合后特征的混叠效应,我加入了conv3x3
self.conv3x3 = nn.ModuleList()
for i in range(len(in_channels_list)):
self.conv3.append(
nn.Sequential(
nn.Conv2d(out_channel, out_channel, 3, 1, 1),
nn.GroupNorm(32, out_channel)))
self.FPA = FPAModule(in_channels_list[-1], out_channel)
self.GAU_3 = GAUModule(in_channels_list[-2], out_channel)
self.GAU_2 = GAUModule(in_channels_list[-3], out_channel)
self.GAU_1 = GAUModule(in_channels_list[0], out_channel)
def get_results_from_layer_blocks(self, x, idx):
num_blocks = 0
for m in self.conv3x3:
num_blocks += 1
if idx < 0:
idx += num_blocks
out = x
i = 0
for module in self.conv3x3:
if i == idx:
out = module(x)
i += 1
return out
def forward(self, x):
names = list(x.keys())
x = list(x.values())
result = []
P5 = self.FPA(x[-1])
P5 = self.get_results_from_layer_blocks(P5, -1)
result.append(P5)
gau3_out = self.GAU_3(x[-2], P5)
P5_up = F.interpolate(P5, (x[-2].size(2), x[-2].size(3)),
mode="bilinear", align_corners=True)
P4 = P5_up + gau3_out
P4 = self.get_results_from_layer_blocks(P4, -2)
result.insert(0, P4)
P4_up = F.interpolate(P4, (x[-3].size(2), x[-3].size(3)),
mode="bilinear", align_corners=True)
gau2_out = self.GAU_2(x[-3], P4_up)
P3 = P4_up + gau2_out
P3 = self.get_results_from_layer_blocks(P3, -3)
result.insert(0, P3)
P3_up = F.interpolate(P3, (x[0].size(2), x[0].size(3)),
mode="bilinear", align_corners=True)
gau1_out = self.GAU_1(x[0], P3_up)
P2 = P3_up + gau1_out
P2 = self.get_results_from_layer_blocks(P2, 0)
result.insert(0, P2)
out = OrderedDict([(k, v) for k, v in zip(names, result)])
return out
感想
这篇总体来说个人感觉还不错,创新性地提出了FPA和GAU模块,但是个人感觉是从SENet的基础上启发而来;其中考虑到在顶层特征中继续使用不同尺度的卷积核继续卷积,增大感受野,获取不同尺度的信息,还应用全局信息去指导底层信息的选择,结果也不错。但个人感觉还能和PANet的bottom up结构进行结合,看看是不是会再有提升。















 462
462











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









