







前向传播

X,数据集矩阵。
每一行的元素代表了一个样例的特征值x1,x2,x3...
共有n行,说明数据集一共n个样例
theta,参数矩阵
行数:要生成的神经元个数
列数:上一层的输入个数
每一行的元素代表了对样例各个特征值的权重
以数据集为X(5 * 3),使用上图的网络结构为例:
输入层
X(5 * 3)说明数据集有5个样例,每个样例有3个特征值
针对图中的输入层a(1),是一个样例的所有特征值。
隐藏层1
z2=X * theta1.T ——> (5,3) * (3,5) ——> (5,5)的矩阵
theta1:要生成5个神经元,上一层输入个数是3,所以其结构是(5 * 3)
公式中的 theta1 * a1 是算法思想的描述,代码实现需用X * theta.T
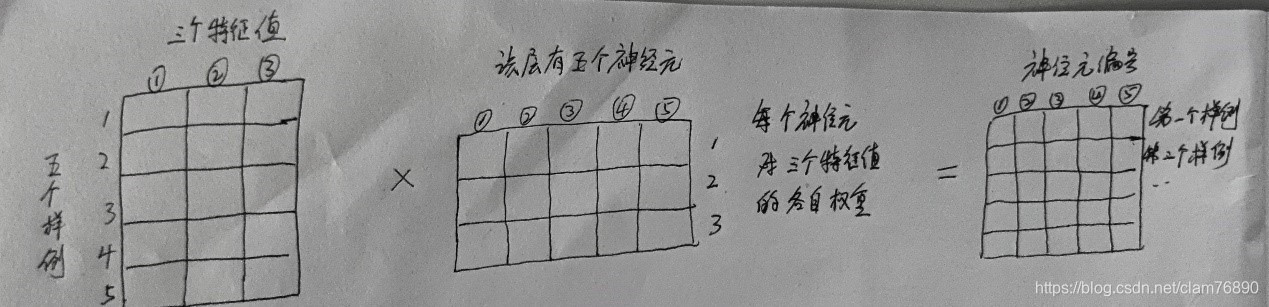
得到的矩阵,矩阵元素是神经元的暂时取值,后续需带入g( )。
有5列,代表5个神经元的各自暂时取值 {
- 样例特征值乘以其各自权重之后,相加。是一个数
- 5个神经元对特征值的权重不一样
}
有5行,每一行是一个样例的所有神经元的暂时取值
a2 = g( z2 )
将z2矩阵中的每一个元素作为参数传入g( )函数,进行运算。
运算后的矩阵行列数不变,矩阵中每一行是一个样例,一行中的每一个元素代表神经元的值,即a(2)1,a(2)2 ...
隐藏层2
以a2矩阵的每一行作为一个样例输入,与隐藏层1类似操作,得到a3矩阵
theta2 ——> (5,5)
输出层
z4 = a3 * theta3.T ——> (5 ,5) * (5,4) ——> (5,4)
theta3:要生成4个神经元(此层的神经元就是输出,4个神经元代表4种分类),上一层输入个数是5,所以其结构是(4,5)
a4 = h(x) = g(z4),运算后是一个(5,4)矩阵
每一行一个样例,共5个样例
每一行的4个元素,代表该样例是分类1的概率,是分类2的概率...
若分类1的概率最大,则该样例属于分类1。使用np.argmax,返回最大值的下标n,可将a4转换成(5,1)的向量。
反向传播
根据前向传播的预测结果,建立代价函数J。反向传播是为了计算J的梯度,以便进行最小化操作,得到最佳的theta1、2、3矩阵。
神经网络的代价函数如下,我们的目标是求出。求解需要用到J的梯度数据
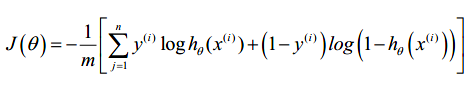
J是一个多元函数,所有的theta矩阵元素都是J的变量。其梯度是:J对每一个theta元素的偏导。如下可以证得(下图的网络结构与本例不同,具体做法有差别),偏导可以通过反向传播的误差矩阵求得。

具体做法是:

在本例中,可达到delta4,delta3,delta2。不对输入层做误差分析,故没有theta1。
,
由此可以得到D1,D2,D3矩阵,将D1、2、3降维,合并在一起,即可得到一个一维向量,即梯度grad。grad中的元素是J关于所有theta矩阵元素的偏导。
grad即是反向传播过程的输出。
有了代价函数J及梯度数据grad,可带入优化算法,运算得到训练后的theta1、2、3矩阵。















 4501
4501











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









