







https://blog.csdn.net/weixin_39568744/article/details/82250663
https://www.zhihu.com/question/52668301/answer/131573702
https://www.cnblogs.com/wj-1314/p/9593364.html
卷积层——提取边缘特征特征
MNIST既可以用全连接神经网络进行训练分类,但CNN是更优的选择,因为CNN一个厉害的地方就在于通过局部感知和权值共享 减少了神经网络需要训练的参数的个数
- 局部感知:一般认为人对外界的认知是从局部到全局的,而图像的空间联系也是局部的像素联系较为紧密,而距离较远的像素相关性则较弱。因而,每个神经元其实没有必要对全局图像进行感知,只需要对局部进行感知,然后在更高层将局部的信息综合起来就得到了全局的信息
- 权值共享:使用一个卷积核组可以在整个图片上滑动,生成多个神经元,这些神经元都共享了一组权值。(但这只提取了一种特征?)故需多个卷积核组,不同的卷积核组对应不同的滤波器种类,提取不同的特征(各个卷积核组分别提取向左弯曲曲线、向右弯曲曲线、圆形.....)
从高层次角度而言卷积是如何工作的?每个过滤器可以被看成是特征标识符( feature identifiers)。这里的特征指的是例如直边缘、原色、曲线之类的东西。想一想所有图像都共有的一些最简单的特征。假设第一组过滤器是 7 x 7 x 3 的曲线检测器。(在这一节,为了易于分析,暂且忽略该过滤器的深度为 3 个单元,只考虑过滤器和图像的顶层层面。)作为曲线过滤器,它将有一个像素结构,在曲线形状旁时会产生更高的数值(切记,我们所讨论的过滤器不过是一组数值!)

左图:过滤器的像素表示;右图:曲线检测器过滤器的可视化;对比两图可以看到数值和形状的对应
回到数学角度来看这一过程。当我们将过滤器置于输入内容的左上角时,它将计算过滤器和这一区域像素值之间的点积。拿一张需要分类的照片为例,将过滤器放在它的左上角。

切记,我们要做的是将过滤器与图像的原始像素值相乘。

左图:感受野的可视化;右图:感受野的像素表示 * 过滤器的像素表示
简单来说,如果输入图像上某个形状看起来很像过滤器表示的曲线,那么所有点积加在一起将会得出一个很大的值!让我们看看移动过滤器时会发生什么。

这个值小了很多!这是因为图像的这一部分和曲线检测器过滤器不存在对应。记住,这个卷积层的输出是一个激活映射(activation map)。因此,在这个带有一个过滤器卷积的例子里(当筛选值为曲线检测器),激活映射将会显示出图像里最像曲线的区域。在该例子中,28 x 28 x 1 的激活映射的左上角的值为 6600。高数值意味着很有可能是输入内容中的曲线激活了过滤器。激活地图右上角的值将会是 0,因为输入内容中没有任何东西能激活过滤器(更简单地说,原始图片中的这一区域没有任何曲线)。这仅仅是一组检测右弯曲线的过滤器。还有其它检测左弯曲线或直线边缘的过滤器。过滤器越多,激活映射的深度越大,我们对输入内容的了解也就越多
池化层——降维
- invariance(不变性),计算后不会改变原图像的特征。这种不变性包括translation(平移),rotation(旋转),scale(尺度)
- 在保留主要特征的同时,降维(减少参数),降低计算量
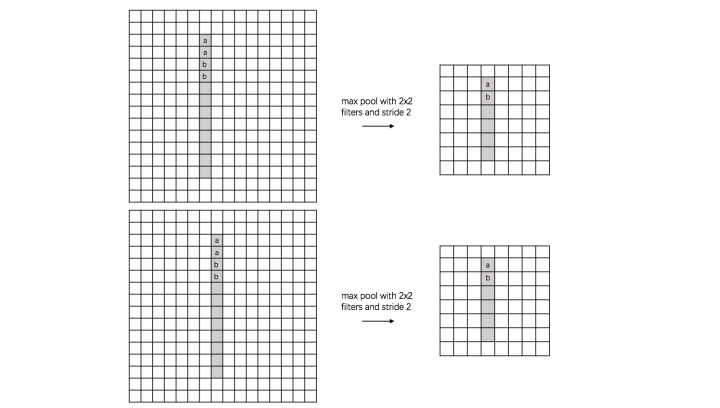
以数字识别为例,图片大小16x16
(1) translation invariance:
图片里有个数字1,我们需要识别出来,这个数字1可能写的偏左一点(图1),这个数字1可能偏右一点(图2),图1到图2相当于向右平移了一个单位,但是图1和图2经过max pooling之后它们都变成了相同的8x8特征矩阵,主要的特征我们捕获到了,同时又将问题的规模从16x16降到了8x8,而且具有平移不变性的特点。图中的a(或b)表示,在原始图片中的这些a(或b)位置,最终都会映射到相同的位置。
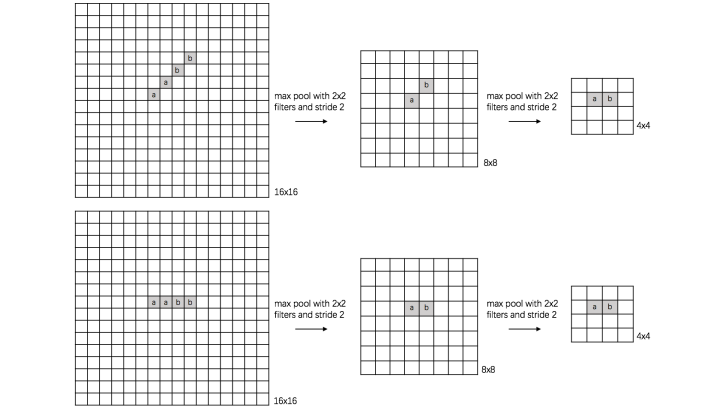
(2) rotation invariance:
下图表示汉字“一”的识别,第一张相对于x轴有倾斜角,第二张是平行于x轴,两张图片相当于做了旋转,经过多次max pooling后具有相同的特征
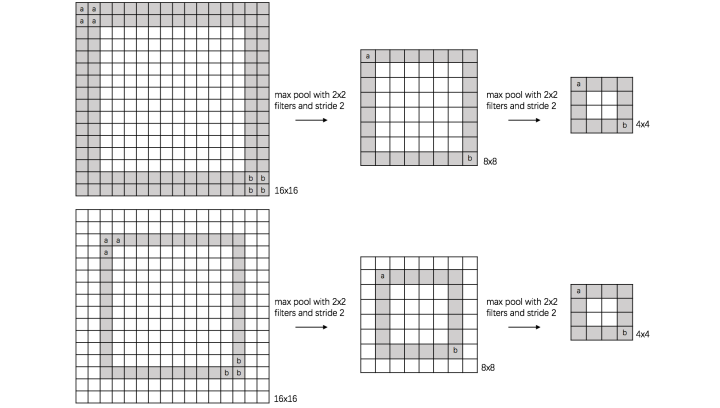
(3) scale invariance:
下图表示数字“0”的识别,第一张的“0”比较大,第二张的“0”进行了较小,相当于作了缩放,同样地,经过多次max pooling后具有相同的特征
全连接层——分类
在整个卷积神经网络中起到“分类器”的作用。如果说卷积层、池化层和激活函数层等操作是将原始数据映射到隐层特征空间(把原始的图片数据,转换成隐藏层的数据)的话,全连接层则起到将学到的“分布式特征表示”映射到样本标记空间的作用。
此时在进行的是传统的全连接神经网络的操作。在经过卷积—池化—卷积—池化后,此时的输入层数据已经减少了很多(但全连接层的参数个数占整个网络的80%,依然很多),可以采用全连接神经网络进行分类。
CNN实现
import torch
from torch import nn
from torch.autograd import Variable
import torchvision
import torchvision.transforms as transforms
from torch.utils.data import DataLoader, sampler
from torchvision.datasets import CIFAR10
import torch.nn.functional as F
import torch.optim as optim
transform = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
trainset = torchvision.datasets.CIFAR10(root = 'CIFAR10', train = True,
download = True, transform = transform)
trainloader = torch.utils.data.DataLoader(trainset, batch_size = 4,
shuffle = True, num_workers = 2)
testset = torchvision.datasets.CIFAR10(root = 'CIFAR10', train = False,
download = True, transform = transform)
testloader = torch.utils.data.DataLoader(testset, batch_size = 4,
shuffle = False, num_workers = 2)
classes = ('plane', 'car', 'bird', 'cat',
'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
class Net(nn.Module):
#定义CNN中各层的结构
def __init__(self):
#父类Module有属性,Net类需要把父类的属性继承下来,再新建自己的属性
#若不写super().__init__(),需把父类的属性全部重写
super(Net, self).__init__()
# 3:输入图片的通道数,图片是RGB 3通道
# 6:输出的通道数,即为卷积核组。一个卷积核组作用于图片,得到一个输出通道,共有6个卷积核组作用于图片,得到6个输出通道
# 5:卷积核size是5*5*3。5*5的矩阵作用在一个图片通道,图片共有3个通道,需要3层卷积核,作为卷积核组
self.conv1=nn.Conv2d(3,6,5)
# nn.Conv2d是一个类,继承自Conv2d->_ConvNd->Module,在建立Module类时,定义了__call()__。说明这个类、子类、对象时可调用的
# self.conv1是一个可调用的对象,self.conv1(x) = self.conv1.forward(x)
#池化层一个2*2的矩阵
self.pool=nn.MaxPool2d(2,2)
self.conv2=nn.Conv2d(6,16,5)
#全连接层。输入层的5*5*16个神经元 与 输出层的120个神经元全连接
self.fc1=nn.Linear(5*5*16,120)
self.fc2=nn.Linear(120,84)
self.fc3=nn.Linear(84,10)
#描述前向传播过程,将定义好的各层 按顺序组织起来
#整个过程:卷积-激活-池化-卷积-激活-池化-全连接-激活-全连接-激活-全连接
#输入x的size:32*32*3
def forward(self, x):
#将输入进行第一次卷积,一个卷积核组得到一个28*28的数组(输出通道),6个卷积核组得到6个28*28的数组(输出通道)
x=self.conv1(x)
#激活函数。将卷积的输出28*28*6的每一个元素,带入激活函数。不改变通道的size
x=F.relu(x)
#1、28*28的输出通道分割成2*2的不重叠小块,取每一块的最大值。
#对所有6个输出通道进行1操作,输出14*14*6的通道
x=self.pool(x)
#第二次卷积,每个卷积核组得到10*10的输出通道,共有16个输出通道。
#激活不改变通道size
#池化后,输出5*5*16的通道
x=self.pool(F.relu(self.conv2(x)))
# 将池化层输出展开成一行:16*5*5 ——> 1行。x.view等价于x.reshape,两个参数分别是变化后的行 列数。
# 行的值为-1:自动匹配行数
x = x.view(-1, 16 * 5 * 5)
#将所有通道的5*5*16=400个元素,激活函数作用后,作为神经元 全连接到120个神经元上
x=F.relu(self.fc1(x))
x=F.relu(self.fc2(x))
x=self.fc3(x)
return x
net=Net().cuda()
#net里面各参数都是Variable
criterion =nn.CrossEntropyLoss()
optimizer =optim.SGD(net.parameters(),lr = 0.01,momentum = 0.9)
if __name__ == '__main__':
for epoch in range(2):
running_loss=0.0
for i,data in enumerate(trainloader,0):
inputs,labels=data
inputs,labels=Variable(inputs.cuda()),Variable(labels.cuda())
optimizer.zero_grad()
outputs=net(inputs) #前向传播
loss=criterion(outputs,labels) #代价函数
# 各参数是一个Variable。算各参数的梯度,并保存到Variable.grad
loss.backward()
# 根据各参数的梯度Variable.grad,更新其参数值Variable.data
optimizer.step()
running_loss+=loss.data[0]
if i % 2000 == 1999:
print('[%d, %5d] loss: %.3f' %
(epoch + 1, i + 1, running_loss / 2000))
running_loss = 0.0
class_correct = list(0. for i in range(10))
class_total = list(0. for i in range(10))
for data in testloader:
images, labels = data
outputs = net(Variable(images))
_, predicted = torch.max(outputs.data, 1)
c = (predicted == labels).squeeze()
for i in range(4):
label = labels[i]
class_correct[label] += c[i]
class_total[label] += 1
for i in range(10):
print('Accuracy of %5s : %2d %%' % (classes[i], 100 * class_correct[i] / class_total[i]))














 9000
9000











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









