









1、Fork/Join框架是什么
Fork/Join框架是一个比较特殊的线程池框架,专用于需要将一个任务不断分解成多个子任务(分支),并将多个子任务的结果不断进行汇总得到最终结果(聚合)的并行计算框架。
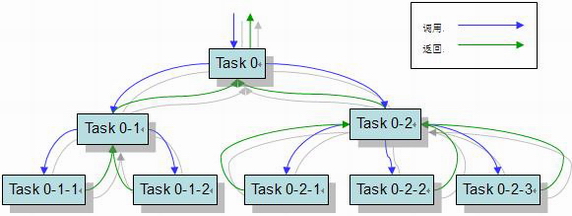
Fork/Join框架示例图(图片来自互联网)
2、相关类说明
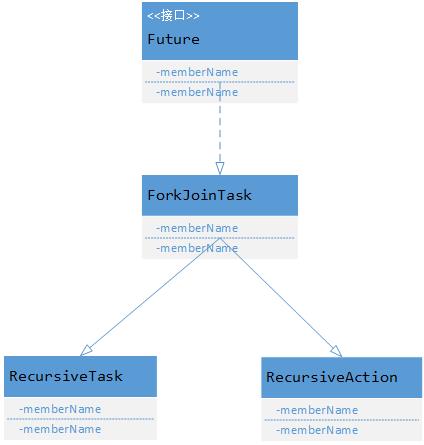
ForkJoinTask:我们要使用ForkJoin框架,必须首先创建一个ForkJoin任务。它提供在任务中执行fork()和join()操作的机制,通常情况下我们不需要直接继承ForkJoinTask类,而只需要继承它的子类,Fork/Join框架提供了以下两个子类:
- RecursiveTask:用于有返回结果的任务。
- RecursiveAction:用于没有返回结果的任务。
继承关系如下图所示:
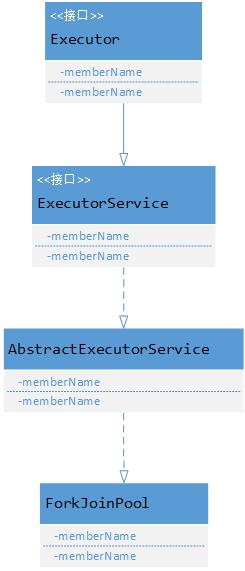
ForkJoinPool:ForkJoinTask需要通过ForkJoinPool来执行,任务分割出的子任务会添加到当前工作线程所维护的双端队列中,进入队列的头部。当一个工作线程的队列里暂时没有任务时,它会随机从其他工作线程的队列的尾部获取一个任务。比起传统的线程池类ThreadPoolExecutor,ForkJoinPool 实现了工作窃取算法,使得空闲线程能够主动分担从别的线程分解出来的子任务,从而让所有的线程都尽可能处于饱满的工作状态,提高执行效率。
ForkJoinPool 提供了三类方法来调度子任务:
- execute 系列:异步执行指定的任务。
- invoke 和 invokeAll:执行指定的任务,等待完成,返回结果。
- submit 系列:异步执行指定的任务并立即返回一个 Future 对象。
继承关系如下图所示:
3、使用Fork/Join框架
任务说明:采用Fork/Join框架遍历指定目录(含子目录)中的文件数量。
任务实现逻辑:
1、获取指定目录中的文件和子目录
2、遍历目录中的文件和子目录
3、如果是文件则计数器加1
4、如果是目录,则递归创建子任务
5、将各任务的结果进行汇总形成最终结果
import java.io.IOException;
import java.nio.file.DirectoryStream;
import java.nio.file.Files;
import java.nio.file.LinkOption;
import java.nio.file.Path;
import java.nio.file.Paths;
import java.util.ArrayList;
import java.util.List;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.ForkJoinPool;
import java.util.concurrent.Future;
import java.util.concurrent.RecursiveTask;
/**
* <p>Title: CountingTask</p>
* <p>Description: 统计指定目录(含子目录)的文件数量</p>
* @author liuzhibo
* @date 2016年8月17日
*/
public class CountingTask extends RecursiveTask<Integer> {
private Path dir;
public CountingTask(Path dir) {
this.dir = dir;
}
@Override
protected Integer compute() {
int count = 0;
List<CountingTask> subTasks = new ArrayList<>();
// Opens a directory, returning a DirectoryStream to iterate over all entries in the directory.
// 打开目录,返回一个DirectoryStream对象,用来遍历这个目录下的所有实体。
try (DirectoryStream<Path> ds = Files.newDirectoryStream(dir)) {
for (Path subPath : ds) {
if (Files.isDirectory(subPath, LinkOption.NOFOLLOW_LINKS)) {
// 对每个子目录都新建一个子任务。
subTasks.add(new CountingTask(subPath));
} else {
// 遇到文件,则计数器增加 1。
count++;
}
}
if (!subTasks.isEmpty()) {
// 在当前的 ForkJoinPool 上调度所有的子任务。
for (CountingTask subTask : invokeAll(subTasks)) {
count += subTask.join();
}
}
} catch (IOException ex) {
return 0;
}
return count;
}
public static void main(String [] args){
try {
// 用一个 ForkJoinPool 实例调度“总任务”
System.out.println("task start");
ForkJoinPool pool = new ForkJoinPool();
CountingTask task = new CountingTask(Paths.get("D:/"));
Integer count = 0;
Future<Integer> result = pool.submit(task);
count = result.get();
System.out.println("文件数量:" + count);
System.out.println("task end");
} catch (Exception e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}分析:
1、DirectoryStream<Path> ds = Files.newDirectoryStream(dir)获取指定目录中的文件和子目录
2、for (Path subPath : ds) {}遍历目录中的文件和子目录
3、count++;如果是文件则计数器加1
4、if (Files.isDirectory(subPath, LinkOption.NOFOLLOW_LINKS)){subTasks.add(new CountingTask(subPath));}如果是目录,则递归创建子任务
5、count += subTask.join();将各任务的结果进行汇总形成最终结果
4、Fork/Join框架的异常处理
ForkJoinTask在执行的时候可能会抛出异常,但是我们没办法在主线程里直接捕获异常,所以ForkJoinTask提供了isCompletedAbnormally()方法来检查任务是否已经抛出异常或已经被取消了,并且可以通过ForkJoinTask的getException方法获取异常。使用如下代码:
if(task.isCompletedAbnormally())
{
System.out.println(task.getException());
}getException方法返回Throwable对象,如果任务被取消了则返回CancellationException。如果任务没有完成或者没有抛出异常则返回null。
5、应用场景
Fork/Join框架适合能够进行拆分再合并的计算密集型(CPU密集型)任务。Fork/Join框架是一个并行框架,因此要求服务器拥有多CPU、多核,用以提高计算能力。
如果是单核、单CPU,不建议使用该框架,会带来额外的性能开销,反而比单线程的执行效率低。当然不是因为并行的任务会进行频繁的线程切换,因为Fork/Join框架在进行线程池初始化的时候默认线程数量为Runtime.getRuntime().availableProcessors(),单CPU单核的情况下只会产生一个线程,并不会造成线程切换,而是会增加Fork/Join框架的一些队列、池化的开销。
6、约束条件
- 除了fork() 和 join()方法外,线程不得使用其他的同步工具。线程最好也不要sleep()
- 线程不得进行I/O操作
- 线程不得抛出checked exception















 435
435

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









