







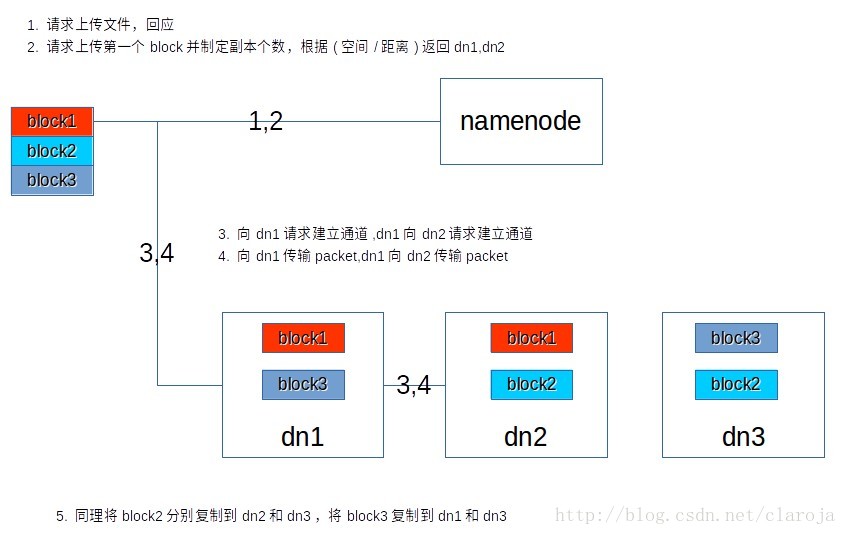
HDFS上传文件
1 客户端:向namenode请求上传文件,请返回批准
1 namenode:可以上传
2 客户端:请求上传第一个block(0-128M),请返回datenode
2 namenode: 综合考虑空间/距离,返回若干datenode(dn1,dn2,dn4)。
3 客户端:向dn1请求建立block传输通道channel,并让dn1和dn2,dn4建立channel
3 datanode:dn1同dn2,dn4建立通道,成功后应答
4 客户端:以64k大小的packet写入dn1(建立的有缓冲区),缓冲区的packet会复制给dn2,然后dn2的packet会复制给dn4(以chunk为单位校验512Byte)
4 datanode:成功后响应(只要有一个成功就可以,后续namenode会异步传输)
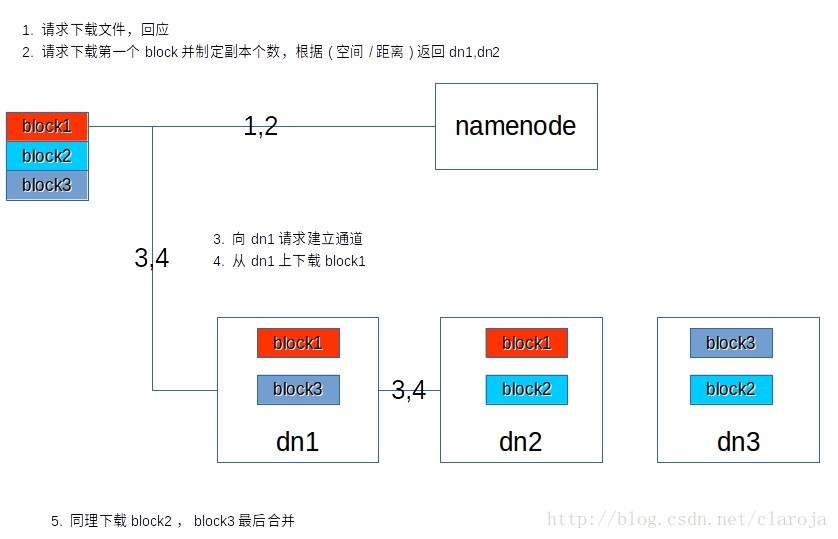
HDFS下载文件
namenode secondarynamenode
- 元数据修改请求会在内存里更新,并且在硬盘里追加到edit文件里
- secondary会依据一定条件(定时/edit记录数量),下载edits和fsimage文件并按照内存的算法合并二者,再重新上传到namenode里,这样就可以保证namenode内存中的元数据和fsimage里的数据保持一致
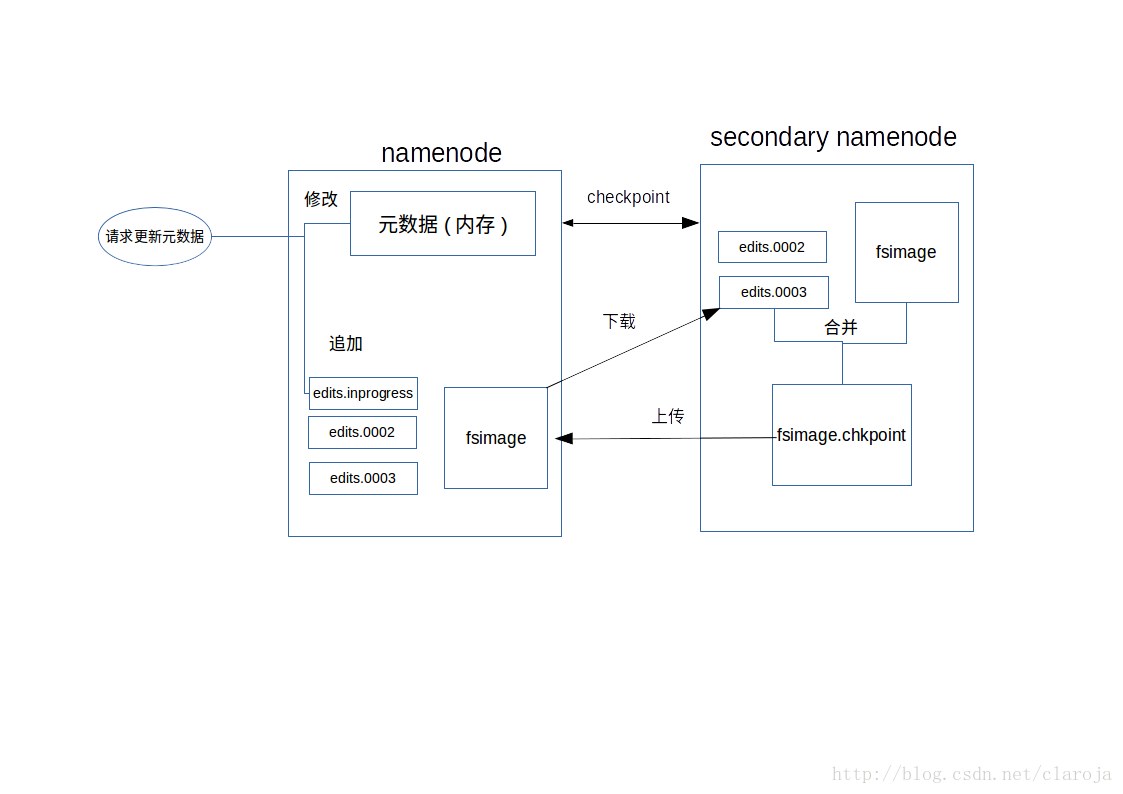
如果namenode损坏,可以将secondarynamenode的元数据拷给namenode
namenode配置
首先要格式化namenode工作目录
在core-site.xml里面配置临时文件保存的目录
<property>
<name>hadoop.tmp.dir</name>
<value>/tmp/hadoop-${user.name}</value>
<description>A base for other temporary directories.</description>
</property>
namenode的工作目录应该配在多块磁盘上,在hdfs-site.xml里配置
<property>
<name>dfs.name.dir</name>
<value>file://${hadoop.tmp.dir}/dfs/name</value>
</property>datanode配置
配置datanode汇报自身block信息的间隔时间
<property>
<name>dfs.blockreport.intervalMsec</name>
<value>3600000</value>
<description>Determines block reporting interval in milliseconds.</description>
</property>配置datanode的timeout时长
当datanode无法与namenode通信时,namenode不会立即把该节点判定为死亡,要经过一定时间才会判定,这个时间称之为timeout
timeout = 2 * heartbeat.recheck.interval + 10 * dfs.heartbeat.interval
<property>
<name>heartbeat.recheck.interval</name>
<value>2000</value>
</property>
<property>
<name>dfs.heartbeat.interval</name>
<value>1</value>
</property>













 418
418











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









