






BGD MBGD SGD 3种梯度下降算法
复现西湖大学赵世钰老师b站强化学习课程第6课,讲解比较3种梯度下降算法。
批量梯度下降 batch_gradient_descent
小批量梯度下降 mini_batch_gradient_descent
随机梯度下降 stochastic_gradient_descent
随机生成100份二维数据样本(X, Y)
分别构建函数求解均值
实现时遇到一个问题,每次更新后得到的结果(列表)内元素是一样的,经过debug找到是由于更新时对estimate赋值时没有采用.copy(),导致列表元素estimate同时变化,只能看到最后一次更新的数据!即更新estimate时也更新了之前的estimate值,如果不明白可以删除.copy(),做一个比较。
import numpy as np
import matplotlib.pyplot as plt
# 设置随机种子以确保结果的可重复性
np.random.seed(0)
# 生成样本数据
samples = np.random.uniform(low=-10, high=10, size=(100, 2)) + np.random.rand(100, 2) * 0.3
# 真实均值
true_mean = np.mean(samples, axis=0)
# 初始估计值
estimate = np.array([10.0, 10.0])
iterations = 100
iteration=0.03
# 计算距离的函数
def calculate_distance(estimates, true_mean):
"""计算估计值与真实均值之间的距离"""
# axis=1表示在行方向(即向量维度)上计算范数,通常是欧式距离
return np.linalg.norm(estimates - true_mean, axis=1)
# 批量梯度下降
def batch_gradient_descent(samples, true_mean, estimate):
estimates = [[10.0,10.0]]
distances = [calculate_distance(np.array([estimate]), true_mean)[0]]
for k in range(iterations):
gradient = np.mean(samples, axis=0) - estimate
estimate += 1/(k+1) * gradient
# 如果不使用.copy(),则列表元素estimate同时变化,只能看到最后一次更新的数据!
estimates.append(estimate.copy())
distances.append(calculate_distance(np.array([estimate]), true_mean)[0])
return np.array(estimates), np.array(distances)
# 小批量梯度下降
def mini_batch_gradient_descent(samples, true_mean, estimate, batch_size=5):
estimates = [[10.0,10.0]]
distances = [calculate_distance(np.array([estimate]), true_mean)[0]]
for k in range(iterations):
indices = np.random.choice(samples.shape[0], batch_size, replace=False)
gradient = np.mean(samples[indices], axis=0) - estimate
estimate += 1/(k+1) * gradient
estimates.append(estimate.copy())
distances.append(calculate_distance(np.array([estimate]), true_mean)[0])
return np.array(estimates), np.array(distances)
# 随机梯度下降
def stochastic_gradient_descent(samples, true_mean, estimate):
estimates = [[10.0,10.0]]
distances = [calculate_distance(np.array([estimate]), true_mean)[0]]
for k in range(iterations):
index = np.random.randint(samples.shape[0])
gradient = samples[index] - estimate
estimate += 1/(k+1) * gradient
estimates.append(estimate.copy())
distances.append(calculate_distance(np.array([estimate]), true_mean)[0])
return np.array(estimates), np.array(distances)
# 运行算法并比较结果
bgd_estimates, bgd_distances = batch_gradient_descent(samples, true_mean, estimate)
mbgd_estimates, mbgd_distances = mini_batch_gradient_descent(samples, true_mean, estimate)
sgd_estimates, sgd_distances = stochastic_gradient_descent(samples, true_mean, estimate)
# bgd_estimates = ((10.0, 10.0)) + bgd_estimates
print(bgd_estimates)
print(mbgd_estimates)
print(sgd_estimates)
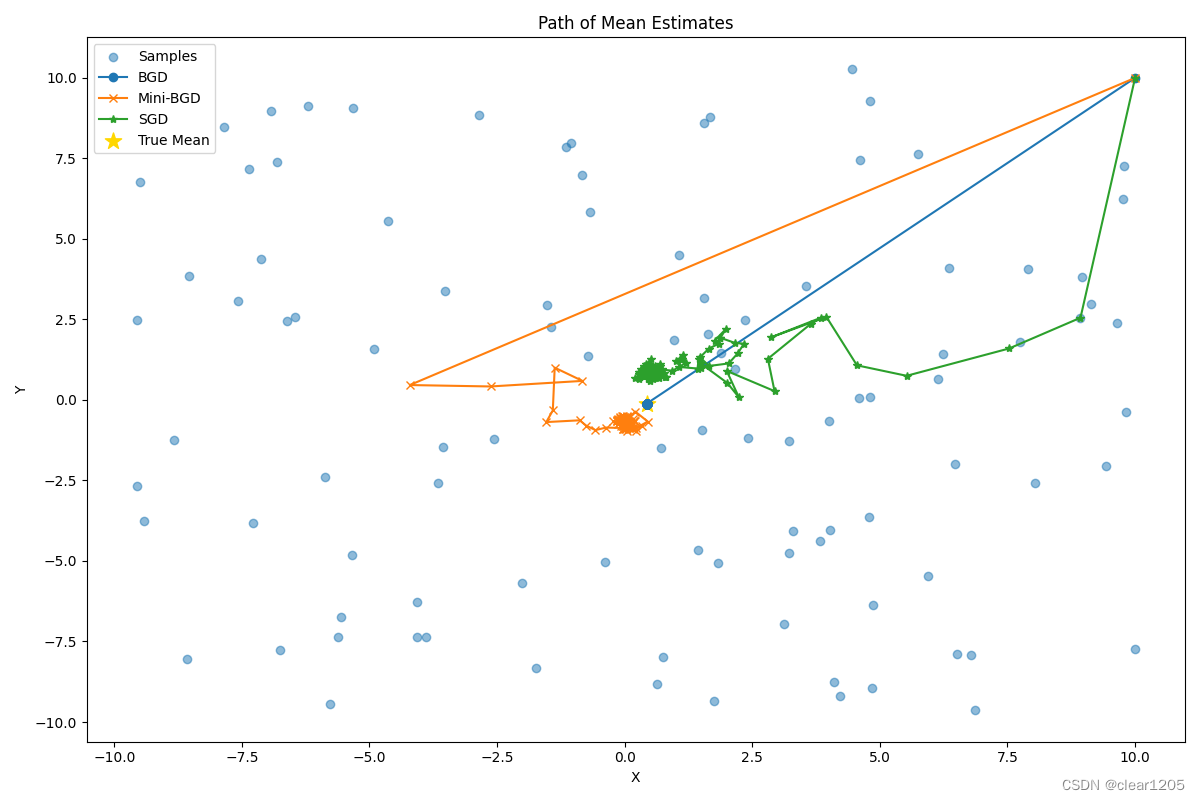
# 绘制结果
plt.figure(figsize=(12, 8))
# 绘制估计值的路径
plt.scatter(samples[:, 0], samples[:, 1], alpha=0.5, label='Samples')
plt.plot(bgd_estimates[:, 0], bgd_estimates[:, 1], 'o-', label='BGD')
plt.plot(mbgd_estimates[:, 0], mbgd_estimates[:, 1], 'x-', label='Mini-BGD')
plt.plot(sgd_estimates[:, 0], sgd_estimates[:, 1], '*-', label='SGD')
plt.scatter(true_mean[0], true_mean[1], marker='*', color='gold', s=150, label='True Mean')
plt.title('Path of Mean Estimates')
plt.xlabel('X')
plt.ylabel('Y')
plt.legend()
plt.tight_layout()
plt.show()
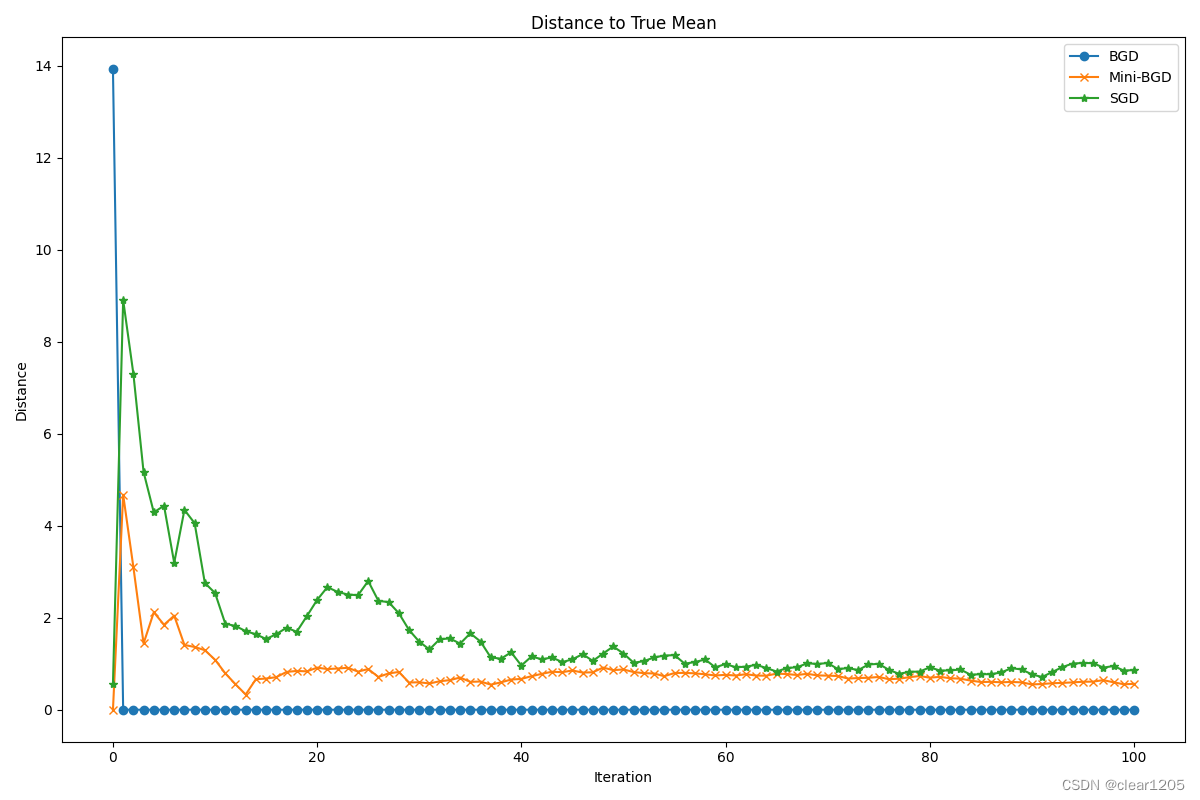
# 绘制到真实均值的距离
plt.figure(figsize=(12, 8))
plt.plot(bgd_distances, 'o-', label='BGD')
plt.plot(mbgd_distances, 'x-', label='Mini-BGD')
plt.plot(sgd_distances, '*-', label='SGD')
plt.title('Distance to True Mean')
plt.xlabel('Iteration')
plt.ylabel('Distance')
plt.legend()
plt.tight_layout()
plt.show()
代码运行结果














 492
492











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









