







概论
梯度下降不会直接用于深度学习,在生产环境中,会使用梯度下降的优化算法
深度学习中的目标函数通常是训练集中每个样本的损失函数平均值。给定 n n n个样本的训练数据集,假设 f i ( x ) f_i(x) fi(x)是第 i i i个训练样本的损失函数,其中 X X X是参数向量。然后我们得到目标函数
f ( X ) = 1 n ∑ i = 1 n f i ( X ) f(X) = \frac{1}{n}\sum_{i=1}^nf_i(X) f(X)=n1i=1∑nfi(X)
X X X的目标函数的梯度计算方式为
∇ f ( x ) = 1 n ∑ i = 1 n ∇ f i ( x ) \nabla f(x)=\frac{1}{n} \sum_{i=1}^n\nabla f_{i}(x) ∇f(x)=n1i=1∑n∇fi(x)
梯度下降法,每个自变量的计算代价是 O ( n ) \mathcal{O}(n) O(n),训练数据集较大时,时间复杂度较高。
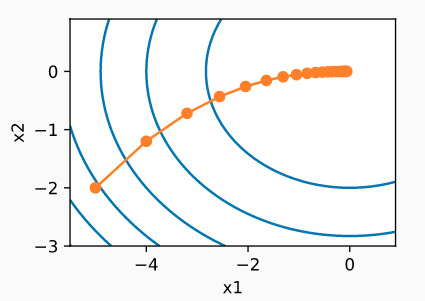
随机梯度下降
随机梯度下降(stochastic gradient descent)算法是深度学习中使用最广泛的优化算法。随机梯度下降(SGD)可降低每次迭代时的计算代价。在每次迭代过程中,我们对数据样本随机均匀采样一个索引 i i i,其中 i ∈ { 1 , … , n } i\in\{1,\ldots, n\} i∈{ 1,…,n},并计算梯度 ∇ f i ( x ) \nabla f_i(x) ∇fi(x)来更新 x x x
x ← x − η ∇ f i ( x ) x \leftarrow x- \eta \nabla f_i(x) x←x−η∇fi(x)
其中 η \eta η是学习率。每次迭代的时间复杂度从 O ( n ) \mathcal{O}(n) O(n)降低到 O ( 1 ) \mathcal{O}(1) O(1)。其中随机梯度 ∇ f i ( x ) \nabla f_i(x) ∇fi(x)是对完整梯度 ∇ f ( x ) \nabla f(x) ∇f(x)的无偏估计,因为
E i ∇ f i ( x ) = 1 n ∑ i = 1 n ∇ f i ( x ) = ∇ f ( x ) . \mathbb{E}_i \nabla f_i(\mathbf{x}) = \frac{1}{n} \sum_{i = 1}^n \nabla f_i(\mathbf{x}) = \nabla f(\mathbf{x}). E
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 492
492











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









