






 研究发现,卷积神经网络(CNNs)过度依赖纹理而非形状进行对象识别,与人类视觉策略不同。通过引入Stylized-ImageNet数据集,成功诱导CNNs学习基于形状的识别,提升了其鲁棒性和识别性能。
研究发现,卷积神经网络(CNNs)过度依赖纹理而非形状进行对象识别,与人类视觉策略不同。通过引入Stylized-ImageNet数据集,成功诱导CNNs学习基于形状的识别,提升了其鲁棒性和识别性能。
ImageNet训练的神经网络偏向于纹理,增加形状偏置可以提高精度
ImageNet-trained CNNs are biased towards texture; increasing shape bias improves accuracy
论文:https://arxiv.org/abs/1811.12231
Github:https://github.com/rgeirhos/texture-vs-shape
SIN数据集:https://github.com/rgeirhos/Stylized-ImageNet
阅读参考:愚蠢的CNN,换个马甲就认不出猫!但,这病能治 | ICLR Oral
摘要:卷积神经网络 ( CNNs ) 通常被认为是通过学习越来越复杂的物体形状表示来识别物体。最近的一些研究表明,图像纹理的作用更为重要。在此,我们将这些相互矛盾的假设进行定量测试,通过评估CNNs和人类观察者对具有纹理-形状提示冲突的图像的反应。我们发现,imagenet-training 的 CNNs 对识别纹理而不是形状有强烈的偏置,这与人类行为证据形成了鲜明的对比,揭示了根本不同的分类策略。然后,我们演示了相同的标准体系结构 ( ResNet-50 ),它学习基于 ImageNet 的基于纹理的表示,而当在 “ Stylized ImageNet ” ( ImageNet 的一个风格化版本 ) 上进行训练时,能够学习基于形状的表示。这在我们控制良好的心理物理实验室环境中更符合人类行为表现 ( 9个实验,共计通过97名观察者进行了48560项心理物理试验 ),它带来了许多意想不到的额外好处,比如改进了对象检测性能,以及对广泛的图像失真具有前所未有的鲁棒性,突出了基于形状表示的优点。

Figure 1:(a)纹理图像的标准ResNet-50分类(大象皮肤:仅纹理提示);(b)猫的正常图像(同时具有形状和纹理线索);(c)前两幅图像之间的样式转换产生的纹理-形状线索冲突的图像。
1 INTRODUCTION
卷积神经网络 ( CNNs ) 如何能够在复杂的感知任务上取得令人印象深刻的性能,如对象识别 ( Krizhevsky et al., 2012 ) 和语义分割 ( Long et al., 2015 ) ?一个被广泛接受的直觉是,CNNs 将低层特征 ( 如边缘 ) 与日益复杂的形状 ( 如车轮、车窗 ) 结合在一起,直到对象 ( 如汽车 ) 可以很容易地分类。正如 Kriegeskorte ( 2015 ) 所说,“ 网络获得与每个类别相关的形状类型的复杂知识。[…] 高级单元似乎学习自然图像中出现的形状表示 ” ( 第429页 ) 。这一概念也出现在其他解释中,如 LeCun et al. ( 2015 ):CNN 中间层识别 “ 熟悉对象的部分,以及随后的层 […] 将目标检测为这些部分的组合 ” ( 第436页 ) 。我们把这种解释称为形状假说。
这一假设得到了许多实证结果的支持。像反体积网络 ( Zeiler & Fergus, 2014 ) 这样的可视化技术经常在 CNN 的高级功能中突出显示对象部分。此外,Kubilius 等人 ( 2016 ) 提出了 CNNs 作为人体形状感知的计算模型,他们进行了大量对比人体和 CNN 形状表征的实验,得出 CNNs “ 隐含学习反映人体形状感知的形状表征 ” 的结论 ( 第15页 )。Ritter et al. ( 2017 ) 发现 CNNs 就像儿童一样会产生所谓的 “ 形状偏置 ”,即物体的形状对于物体分类来说比颜色更重要 ( 但是相反的证据参见 Hosseini et al. ( 2018 ) ) 。此外,CNNs 目前是人类腹侧流目标识别的最具预测性的模型 ( 如 Cadieu et al.,2014:Yamins等,2014 );众所周知,物体的形状是人类识别物体最重要的线索 ( Landau et al.,1988 ),远远超过其他线索,如大小或纹理 ( 这可能解释了人类识别线条图或千年洞穴壁画的容易程度 )。
另一方面,一些不相关的发现指出了物体纹理在 CNN 物体识别中的重要作用。即使整体形状结构被完全破坏,CNNs 仍然可以很好地对纹理图像进行分类 ( Gatys et al.,2017:Brendel & Bethge,2019 ) 。相反,标准的 CNNs 不善于识别保存了对象形状但丢失了所有纹理线索的对象草图 ( Ballester & de Araujo, 2016 ) 。此外,两项研究表明,局部信息,如纹理,实际上可能足以 “ 解决 ” ImageNet 对象识别:Gatys et al. ( 2015 ) 发现基于 CNN 纹理表示 ( Gram矩阵 ) 的线性分类器与原始网络性能相比几乎没有任何分类性能损失。最近,Brendel & Bethge ( 2019 ) 证明,在所有层中都明确限制接收域大小的 CNNs 能够在 ImageNet 上达到惊人的高准确度,尽管这实际上限制了模型只能识别局部小块区域,而不能将目标部件集成起来进行形状识别。总的来说,局部纹理似乎确实提供了足够的对象类信息——ImageNet 对象识别原则上可以通过单独的纹理识别来实现。根据这些发现,我们认为是时候考虑第二个解释了,我们称之为纹理假设:与常见的假设相反,对于 CNN 对象识别来说,对象纹理比全局对象形状更重要。
解决这两个相互矛盾的假设对于深度学习社区 ( 提高我们对神经网络决策的理解 ) 以及人类视觉和神经科学社区 ( CNNs 被用作人类目标识别和形状感知的计算模型 ) 都很重要。在这项工作中,我们的目标是通过一些精心设计但相对简单的实验来阐明这一争论。利用 style transfer ( Gatys et al.,2016 ),我们创建了具有纹理-形状提示冲突的图像,例如 Figure 1 (c) 中描述的猫的形状具有大象的纹理。这使我们能够量化人类和 CNNs 的纹理和形状偏见。为此,我们进行了9项全面而细致的心理物理实验,在完全相同的图像上将人类与 CNNs 进行比较,在97名观察者中进行了总计48560项心理物理实验。这些实验提供了支持纹理假说的行为证据:拥有大象纹理的猫对 CNNs 来说是大象,对人类来说仍然是猫。除了量化现有的偏置,我们随后还为我们的另外两个主要贡献提供了结果:改变偏置,以及发现改变偏置的额外好处。结果表明,在合适的数据集上训练,可以克服标准 CNNs 中的纹理偏置,使其向形状偏置转变。值得注意的是,具有较高形状偏差的网络对许多不同的图像失真天生就更有鲁棒性 ( 有些甚至达到或超过了人类的表现,尽管从未进行过任何训练 ),并在分类和目标识别任务上达到更高的性能。
2 METHODS
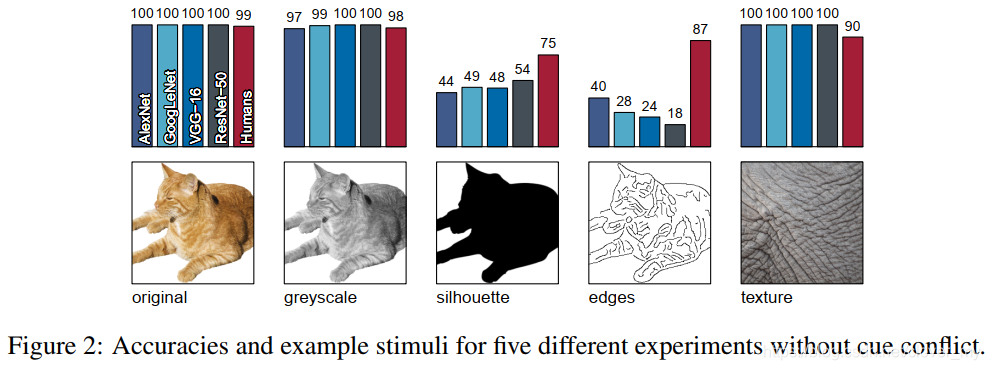
Figure 2:五种不同实验的准确性和示例激励,没有提示冲突。
在本节中,我们将概述范例和过程的核心元素。附录中提供了便于复制的详细信息。数据、程式码及资料可从这个资料库取得:https://github.com/rgeirhos/texture-vs-shape
2.1 PSYCHOPHYSICAL EXPERIMENTS
所有的心理物理实验都是在控制良好的心理物理实验室环境中进行的,并遵循 Geirhos 等人 ( 2018 ) 的范式,该范式允许直接比较人类和 CNN 在完全相同的图像上的分类性能。简单地说,在每个实验参与者面前都有一个300毫秒的固定正方形,然后是300毫秒的激励图像。在激励图像之后,我们展示了一个200毫秒的全对比度粉色噪声掩模 ( 1/f 光谱形状 ),以最小化人类视觉系统的反馈处理,从而使与前馈神经网络的比较尽可能公平。随后,参与者必须从16个初级类别中选择一个,点击一个1500毫秒的响应屏幕。在这个屏幕上,16个类别的图标都排列在一个4×4的网格中。这些类别包括飞机、熊、自行车、鸟、船、瓶子、汽车、猫、椅子、时钟、狗、大象、键盘、刀、烤箱和卡车。(airplane, bear, bicycle, bird, boat, bottle, car, cat, chair, clock, dog, elephant, keyboard, knife, oven, truck)这些是 Geirhos 等人 ( 2018 ) 引入的所谓 “ 16类 ImageNet ” 类别。
同样的图像被输入给4个 CNNs,并在标准 ImageNet 上进行预处理:AlexNet ( Krizhevsky et al.,2012 ),GoogLeNet ( Szegedy et al.,2015 ),VGG-16 ( Simonyan & Zisserman,2015 ),ResNet-50 ( He et al., 2015 ) 。将1000个 ImageNet 类预测映射到使用 WordNet 层次结构的16个类别 ( Miller,1995 )。例如,ImageNet中类别虎斑猫将被映射到猫。总的来说,本研究的结果是基于48560个心理物理试验和97名参与者。
2.2 DATA SETS (PSYCHOPHYSICS)
为了评估纹理和形状的偏差,我们进行了6个主要的实验和3个对照实验,这些实验在附录中进行了描述。前五个实验 ( Figure 2 中显示的示例 ) 是简单的对象识别任务,唯一的区别是参与者可用的图像特征:
- Original:160幅以白色为背景的天然彩色图像(每类别10幅)。
- Greyscale:使用 skimage.color.rgb2gray 将原始数据集中的图像转换为灰度。对于 CNNs,灰度图像沿着彩色通道堆叠。
- Silhouette:从原始数据集转换成剪影图像显示一个完全黑色的物体在白色背景上 ( 见附录 A .6 程序 )。
- Edges:利用 MATLAB 中实现的 Canny 边缘提取器,将原始数据集的图像转换为基于边缘的图像表示。
- Texture:48张纹理的自然彩色图片 ( 每类3张 ) 。通常,纹理由动物的全宽块 ( 例如皮肤或皮毛 ) 组成,特别是对于人造对象,由具有相同对象多次重复的图像组成 ( 例如,许多瓶子彼此相邻,参见附录中的图7 ) 。
需要注意的是,我们只选择了被所有四个网络正确分类的对象和纹理图像。这是为了确保我们在第6次提示/线索冲突实验中的结果是完全可解释的,在形状和纹理假说中,提示冲突是最具决定性的。在线索冲突实验中,我们展示了具有矛盾特征的图像 ( 见Figure 1 ) ,但仍然要求参与者分配一个类。注意,给人类观察者的指令是完全中立的 w.r.t. 形状或纹理 ( “ 点击你在图片中看到的对象类别;如果不确定请猜想。没有对错之分,我们感兴趣的是你的主观印象 ” ) 。
- Cue conflict:在纹理数据集的图像 ( 作为风格/样式 ) 和原始数据集的图像 ( 作为内容 ) 之间使用迭代样式传输生成的图像 ( Gatys et al.,2016 ) 。我们总共生成了1280张提示冲突图像 ( 每个类别80张 ) ,允许在单个实验会话中向人类观察者呈现。
我们将 “ silhouette ” 定义为二维物体的边界轮廓 ( 即,对象分割大纲 ) 。当提到 “ object shape ” 时,我们使用了一个比物体的 silhouette 更宽泛的定义:我们指的是一组描述物体三维形状的轮廓线(contour),即包括那些不属于 silhouette 的轮廓线。在 Gatys 等人 ( 2017 ) 之后,我们将 “ 纹理 / texture ” 定义为具有空间平稳统计量的图像 ( 区域 ) 。注意,在一个非常局部的层次上,纹理 ( 根据这个定义 ) 可以有非平稳的元素 ( 如局部形状 ):例如,一个瓶子显然有非平稳的统计数据,但许多相邻的瓶子被视为纹理:“ 物体 / thing ”变成了 “ 填充物 / stuff ” ( Gatys et al.,2017,第178页 ) 。有关“瓶子纹理”的示例,请参见 Figure 7 。
2.3 STYLIZED-IMAGENET

Figure 3:通过将 AdaIN 风格转换应用到 ImageNet 图像中创建风格化的 ImageNet ( SIN ) 可视化图像。左:随机选取环尾狐猴类的 ImageNet 图像。右:基于左图内容/形状的10个例图,风格/纹理来自不同的绘画。应用 AdaIN 样式转移后,局部纹理提示不再是目标类的高度预测,而全局形状趋于保留。注意,在 SIN 中,每个源映像只被风格化一次。
从 ImageNet 我们构造一个新的数据集 ( 称为 Stylized-ImageNet 或 SIN ) ,通过 AdaIN style transfer,将每一幅图像的原始纹理剥离出来,用随机选取的绘画风格替换 ( Huang & Belongie, 2017 ) ( 请参见Figure 3 ) ,因袭系数 α = 1:0 。由于 Kaggle 的 Painter by Numbers dataset 具有较大的风格多样性和尺寸 ( 79,434幅画作 ),所以我们将其作为一个风格来源。我们使用 AdaIN fast style transfer 而不是迭代风格化 ( 例如 Gatys et al.,2016 ) ,原因有二:首先,为了确保对 SIN 的训练和对提示冲突激励的测试使用不同的风格化技术,这样的结果就不依赖于单一的风格化方法。其次,启用整个 ImageNet 的风格化,使用迭代方法将花费非常长的时间。我们在这里提供代码来创建风格化的 ImageNet :https://github.com/rgeirhos/Stylized-ImageNet
3 RESULTS
3.1 TEXTURE VS SHAPE BIAS IN HUMANS AND IMAGENET-TRAINED CNNS
几乎所有的物体和纹理图像 ( 原始和纹理数据集 ) 都能被 CNNs 和人类正确识别 ( Figure 2 ) 。物体的灰度版本 Greyscale ,仍然包含形状和纹理,被识别得同样好。当用黑色填充物体轮廓来生成轮廓时,CNN 的识别精度远低于人类的识别精度。这在边缘激励下表现得更为明显,表明人类观察者在处理纹理信息很少甚至没有的图像时表现得更好。在这些实验中令人困惑的一点是,CNNs 往往不能很好地处理域转移,即图像统计从自然图像 ( 网络已经训练过 ) 到草图 ( 网络从未见过 ) 的巨大变化。
因此,我们设计了一个提示冲突实验,该实验基于具有自然统计数据但纹理和形状证据相矛盾的图像 ( 参见 Methods ) 。参与者和 CNNs 必须根据他们最依赖的特征 ( 形状或纹理 ) 对图像进行分类。实验结果如 Figure 4 所示。人类观察者对形状类别的反应表现出明显的偏置 ( 95.9% 的正确决策 ) 。对于CNNs,这种模式是相反的,它显示出对纹理类别响应的明显偏置 ( VGG-16:17.2% shape vs. 82.8% texture;GoogLeNet:31.2% vs. 68.8%;AlexNet:42.9% vs. 57.1%;ResNet-50:22.1% vs. 77.9% ) 。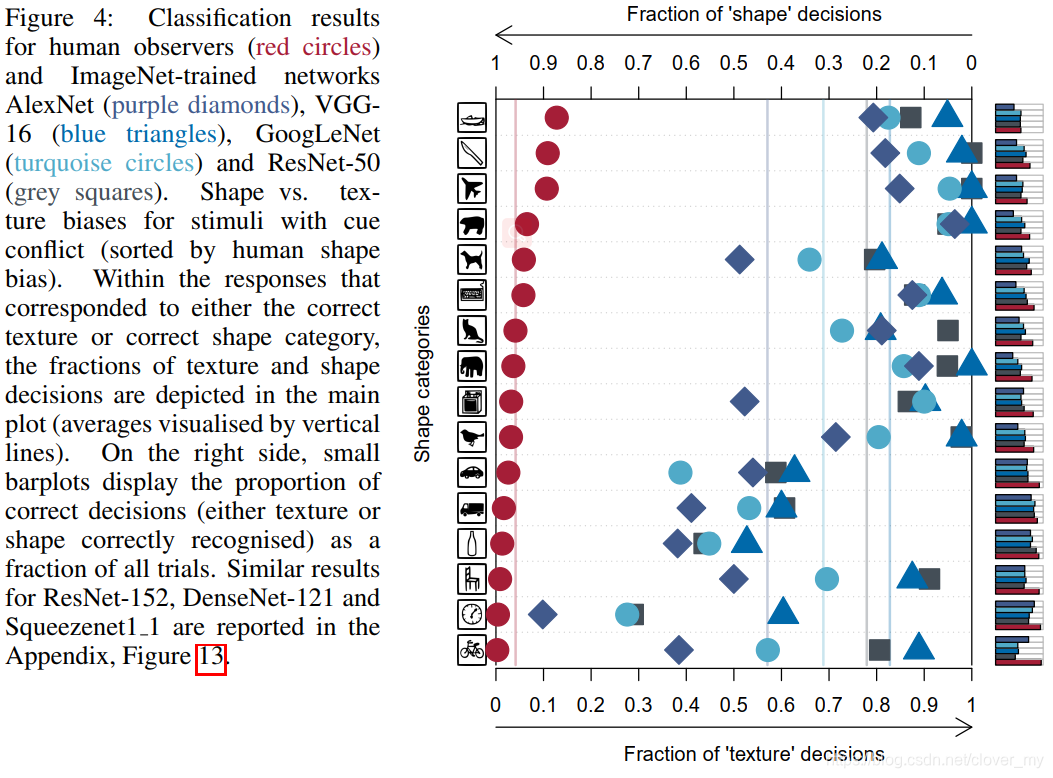
Figure 4:人类观察者的分类结果 ( 红色圆圈 ) ,经过 ImageNet 训练的网络 AlexNet ( 紫色菱形 ) 、VGG-16 ( 蓝色三角形 ) 、GoogLeNet ( 绿色圆圈 ) 、ResNet-50 ( 灰色正方形 ) 。提示冲突激励的 Shape vs. texture 偏置 ( 按人类形状偏置排序 ) 。在对应于正确纹理或正确形状类别的响应中,纹理和形状的决策部分被描述在主图中 ( 用垂直线表示的平均值 ) 。在右侧,小条形图显示了正确决策 ( 正确识别纹理或形状 ) 在所有试验中的比例。附录中报告了 ResNet-152、DenseNet-121 和 squeezenet11 的类似结果,Figure 13。
3.2 OVERCOMING THE TEXTURE BIAS OF CNNS
心理物理实验表明,与人类不同,ImageNet 训练的 CNNs 表现出强烈的纹理偏置。原因之一可能是培训任务本身:从Brendel & Bethge ( 2019 ) 我们知道,仅利用局部信息就可以高精度地求解 ImageNet 。换句话说,它可能只需要集成来自许多局部纹理特征的证据,而不需要经过集成和分类全局形状的过程。为了验证这一假设,我们在 Stylized-ImageNet ( SIN ) 数据集上训练了一个 ResNet-50,在这个数据集中,我们用随机选择的艺术绘画的无信息性风格替换了与对象相关的局部纹理信息。
在 Stylized-ImageNet ( SIN ) 上训练和评估的标准 ResNet-50 可以达到79.0%的 top-5 准确度 ( 见 Table 1 ) 。相比之下,在 ImageNet ( IN ) 上训练和评估的相同架构的准确率达到了92.9%的 top-5 。这种性能差异表明 SIN 是一个比 IN 困难得多的任务,因为纹理不再具有预测性,而是一个讨厌的因素 ( 如所预测 ) 。有趣的是,ImageNet 对 SIN 的泛化很差 ( 在top-5只有16.4%的正确率 );然而,在 SIN 上学习到的特性可以很好地泛化到 ImageNet ( 没有任何微调时top-5的精度为82.6% ) 。
为了测试局部纹理特征是否仍然足以 “ 解决 ” SIN ,我们评估了所谓的 BagNets 的性能。BagNets 最近由 Brendel & Bethge ( 2019 ) 引入,它有一个 ResNet-50 架构,但是它们的最大接受域大小限制在9×9、17×17或33×33像素。这使得 BagNets 无法学习或使用任何远程空间关系进行分类。虽然这些受限网络在 ImageNet 上可以达到很高的精度,但在 SIN 上却无法达到同样的精度,在较小的接受域大小下,性能显著下降 ( 例如,对于接收域大小为9×9像素的 BagNet , SIN 的 top-5 准确率为10.0%,而 ImageNet 的准确率为70.0% ) 。这清楚地表明,我们提出的 SIN 数据集实际上删除了本地纹理提示,迫使网络集成远程空间信息。
最重要的是,SIN 训练的 ResNet-50 在我们的提示冲突实验中显示出更强的形状偏差 ( Figure 5 ),从未训练模型的22%增加到81%。在许多类别中,形状偏置几乎和人类一样强烈。
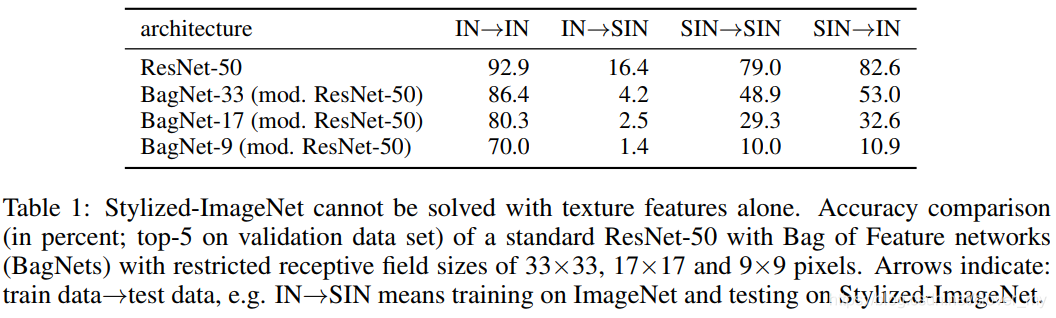
Table 1:Stylized-ImageNet 不能单独用纹理特征来解决。标准 ResNet-50 与33×33、17×17和9×9像素接受域受限的特征网络 ( BagNets ) 的准确度比较 ( 以百分比表示;验证数据集的 top-5 )。箭头表示:训练数据→测试数据,例如,IN→SIN 的意思是在 ImageNet 训练,在 Stylized-ImageNet 测试。
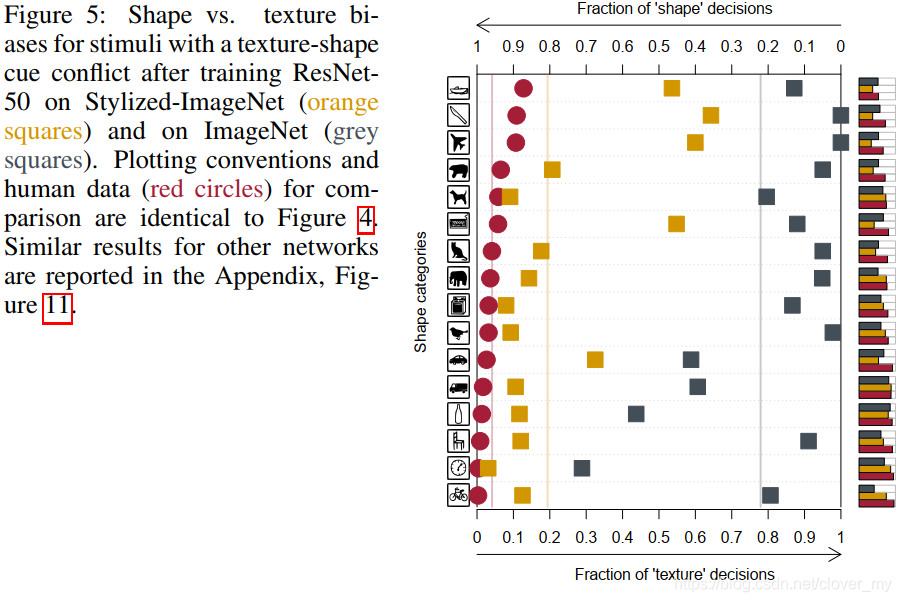
Figure 5:ResNet-50 在 Stylized-ImageNet ( 橙色方块 ) 和 ImageNet ( 灰色方块 ) 上训练后,纹理-形状提示冲突激励的 Shape vs. texture 偏置。用于比较的绘制约定和人工数据 ( 红色圆圈 ) 与 Figure 4 相同。附录 ( Figure 11 ) 中报告了其他网络的类似结果。
3.3 ROBUSTNESS AND ACCURACY OF SHAPE-BASED REPRESENTATIONS
增加的形状偏差,从而改变的表示方式,是否也会影响CNNs的性能或鲁棒性?除了基于 IN 和基于 SIN 训练的 ResNet-50 体系结构之外,我们还分析了两种联合培训方案。
- SIN 和 IN 联合训练。
- SIN 和 IN 联合训练并在 IN 上微调,我们将这个模型称为 Shape-ResNet 。
然后,我们将这些模型与 Vanilla ResNet-50 在3个实验上进行了比较:(1) IN 上的分类性能,(2)转移到 Pascal VOC 2007 上,(3)对图像扰动的鲁棒性。
- Classification performance:Shape-ResNet 在 ImageNet 验证集上 top-1 和 top-5 的精度超过了 Vanilla ResNet,如 Table 2 所示。这表明 SIN 可能是 ImageNet 上的一个有效的数据增强,可以在不进行任何架构更改的情况下提高模型性能。
- Transfer learning:我们在 Pascal VOC 2007 上测试了每个模型作为Fsater R-CNN ( Ren et al.,2017 ) 的骨干特征网络时的表征。在训练数据中加入 SIN 大大提高了目标检测性能,从70.7提高到75.1,mAP50,如 Table 2 所示。这符合一种直觉,即对于对象检测,基于形状的表示比基于纹理的表示更有益,因为包含对象的ground truth矩形在设计上与全局对象形状一致。
- Robustness against distortions:我们系统地测试了当图像受到均匀或相位噪声、对比度变化、高、低通滤波或 eidolon 扰动的影响时,模型精度如何下降。此比较的结果 ( 包括供参考的人类数据 ) 如 Figure 6 所示。虽然在没有失真的图像上缺乏百分之几的准确性,但是在几乎所有的图像处理上经过 SIN 训练的 CNN 都优于经过 IN 训练的 CNN 。( 低通滤波/模糊是唯一一种经过 SIN 训练的网络更容易受到影响的失真类型,这可能是由于 SIN 图像中高频信号的过度表现和对锐边的依赖。) 经过 SIN 训练的 ResNet-50 接近人类水平的失真鲁棒性,尽管在训练过程中没有发现任何失真。
此外,我们在附录的 Table 4 中提供了在 ImageNet-C 上测试的模型的鲁棒性结果,ImageNet-C 是15种不同图像损坏的综合基准 ( Hendrycks & Dietterich, 2019 ) 。SIN 和 IN 联合训练,可大大改善13种损坏类型 ( 高斯、炮点和脉冲噪声;散焦,玻璃和运动模糊;雪、霜、雾天气类型;对比度,弹性,像素和JPEG数字损坏 ) 。这大大降低了整体的损坏错误,Vanilla ResNet-50 从76.7降到69.3。同样,这些破坏类型都不是训练数据的明确组成部分,这加强了在训练机制中加入 SIN 可以以非常普遍的方式提高模型的鲁棒性。

Table 2:在 PASCAL VOC 2007 上对 ImageNet ( IN ) 验证数据集和对象检测性能 ( mAP50 ) 的精度比较。所有模型都具有相同的 ResNet-50 体系结构。方法详见附录。
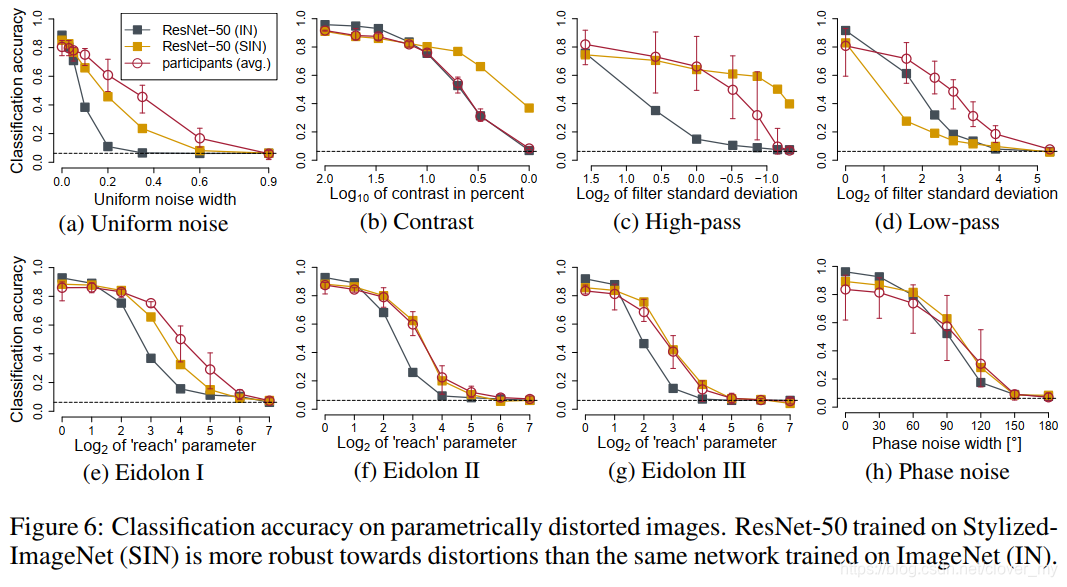
Figure 6:参数畸变/失真图像的分类精度。在 Stylized-ImageNet ( SIN ) 上训练的 ResNet-50 比在 ImageNet ( IN ) 上训练的相同网络对畸变的鲁棒性更强。
4 DISCUSSION
正如引言中所指出的,CNNs 使用越来越复杂的形状特征来识别物体的普遍假设与最近的经验发现之间似乎存在很大的差异,后者表明物体纹理在其中扮演着至关重要的角色。为了明确探究这个问题,我们使用 style transfer ( Gatys et al.,2016 ) 来生成形状和纹理信息冲突的图像。基于在受控的心理物理实验室环境中对 CNNs 和人类观察者进行的大量实验,我们提供了证据,表明与人类不同,经过 ImageNet 训练的 CNNs 倾向于根据局部纹理而不是全局对象形状对对象进行分类。以前的工作表明,改变其他主要的物体尺寸,如颜色 ( Geirhos et al.,2018 ) 和相对于上下文的物体尺寸 ( Eckstein et al.,2017 ) 对 CNN 的识别性能没有很强的不利影响,结合这一现象,突出显示了局部线索 ( 如纹理 ) 在 CNN 对象识别中的特殊作用。
有趣的是,这为一些相当不相关的发现提供了解释:CNNs 与人类的纹理外观相匹配 ( Wallis et al., 2017 ) ,其对人类腹侧神经响应的预测能力似乎在很大程度上是由于类人纹理表征,而不是类人轮廓表征 ( Laskar et al.,2018;Long & Konkle,2018 ) 。此外,基于纹理的生成建模方法,如 style transfer ( Gatys et al.,2016 )、single image super-resolution ( Gondal et al.,2018 ) 以及静态和动态纹理合成 ( Gatys et al.,2015;Funke et al.,2017 ) ,使用标准 CNNs 均能产生良好的效果,而基于 CNNs 的形状转移似乎非常困难 ( Gokaslan et al.,2018 ) 。CNNs 仍然可以识别形状混乱的图像 ( Gatys et al.,2017;Brendel & Bethge,2019 ) ,但他们在识别缺少纹理信息的物体时遇到的困难要多得多 ( Ballester & de Araujo,2016;Yu et al.,2017 ) 。我们的假设也可以解释为什么一个训练在合成纹理图像数据库上的图像分割模型,可以转换成自然图像和视频 ( Ustyuzhaninov et al.,2018 ) 。除此之外,我们的研究结果显示,经过 ImageNet 训练的 CNNs 和人类观察者之间存在显著的行为差异。虽然人类和机器视觉系统在标准图像上实现了类似的高准确度 ( Geirhos et al., 2018 ) ,但我们的发现表明,潜在的分类策略可能实际上是非常不同的。这是有问题的,因为CNNs被用作人类目标识别的计算模型 ( 如 Cadieu et al.,2014;yamin et al .,2014 ) 。
为了减少CNNs的纹理偏置,我们引入了 Stylized-ImageNet ( SIN ) ,这是一种通过样式转移来去除局部线索的数据集,从而迫使网络超越纹理识别。通过这个数据集,我们证明了一个 ResNet-50 架构确实可以学习基于对象形状来识别对象,这表明当前 CNNs 中的纹理偏置不是由设计引起的,而是由 ImageNet 训练数据引起的。这表明,标准的 ImageNet 训练模型可能通过关注局部纹理走了一条 “ 捷径 ” ,这可以看作是 Occam 's razor 的一个版本:如果纹理已经足够了,为什么 CNN 还要学习更多呢?虽然纹理分类可能比形状识别更容易,但我们发现,基于形状的特征训练的 SIN 可以很好地概括自然图像。
我们的研究结果表明,一种更基于形状的表示方法对于依赖于预先训练过的 ImageNet CNNs 的识别任务是有益的。此外,尽管 ImageNet 训练的 CNNs 对广泛的图像失真的泛化能力较差 ( 例如 Dodge & Karam, 2017;Geirhos et al.,2017;2018 ) ,我们的 ResNet-50 在风格图像集 ( Stylize - ImageNet ) 上的训练经常达到甚至超过人类水平的鲁棒性 ( 从未受过特定图像退化的训练 ) 。这是令人兴奋的,因为 Geirhos et al. ( 2018 ) 表明,一般情况下,针对特定扭曲进行训练的网络无法获得对其他不可见操纵图像的鲁棒性。这种额外表现强调了基于形状的表示的有用性:虽然局部纹理很容易被各种噪声 ( 包括现实世界中的雨雪等 ) 扭曲,但物体的形状仍然相对稳定。此外,这一发现提供了一个令人信服的简单解释,解释了人类在应对扭曲时惊人的鲁棒性:基于形状的表示。
5 CONCLUSION
总之,我们提供的证据表明,今天的机器识别过度依赖对象纹理,而不是通常假设的全局对象形状。我们展示了基于形状表示的鲁棒推理的优势 ( 使用我们的 Stylized-ImageNet 数据集在神经网络中诱导这种表示 ) 。设想我们的研究结果,以及我们公开的模型权重、代码和行为数据集 ( 97名观察人员进行了49K次试验 ) ,可以实现三个目标:首先,提高对 CNN 表征和偏置的理解。其次,向更合理的人类视觉对象识别模型迈进了一步。第三,对于未来的任务,一个有用的起点是领域知识表明,基于形状的表示可能比基于纹理的表示更有益。

















 547
547

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









