






- 摘要
卷积神经网络(CNN)通常被认为通过学习对象形状的日益复杂的表示来识别对象。最近的一些研究表明图像纹理具有更重要的作用。我们在这里通过评估具有纹理-形状线索冲突的图像的CNN和人类观察者来将这些相互矛盾的假设置于定量测试中。我们表明,ImageNet训练的CNN强烈偏向于识别纹理而不是形状,这与人类行为证据形成鲜明对比,并揭示了根本不同的分类策略。然后,我们证明在ImageNet上学习基于纹理的表示的相同标准体系结构(ResNet-50)能够学习基于形状的表示,在ImageNet的stylized版本“Stylized-ImageNet”上进行训练。这为我们良好控制的心理物理实验室环境中的人类行为表现提供了更好的适应性(共有97个观察者进行了总共48,560次心理物理试验的九个实验),并且具有许多意想不到的突发性好处,例如改进的物体检测性能和以前在广泛的图像失真中看不见的稳健性,突出了基于形状的表示的优点。

- 方法
在本节中,我们概述了范式和过程的核心要素。 附录中提供了便于复制的详细信息。 此存储库中提供了数据,代码和材料:https://github.com/rgeirhos/texture-vs-shape
- 心理-物理实验
所有的心理物理实验都是在一个控制良好的心理物理实验室环境中进行的,并遵循Geirhos等人的范例(2018),其允许在完全相同的图像上直接比较人类和CNN分类表现。简而言之,在每个试验中,参与者被呈现300ms的固定方格,然后是300ms的刺激图像呈现。在刺激图像之后,我们呈现全对比度粉红色噪声掩模(1 / f光谱形状)200ms,以最小化人类视觉系统中的反馈处理,从而使前馈CNN的比较尽可能公平。随后,参与者必须通过单击显示1500毫秒的响应屏幕来选择16个入门级类别中的一个。在此屏幕上,所有16个类别的图标排列在4X4网格中。这些类别是飞机,熊,自行车,鸟,船,瓶,汽车,猫,椅子,时钟,狗,大象,键盘,刀,烤箱和卡车。这些是Geirhos等人提出的所谓的“16类 - ImageNet”类别(2018)。
相同的图像被送到四个在标准ImageNet上预训练的CNN,即AlexNet(Krizhevsky等,2012),GoogLeNet(Szegedy等,2015),VGG-16(Simonyan&Zisserman,2015)和ResNet-50 (He等,2015)。 使用WordNet层次结构(Miller,1995)-e.g将1,000个ImageNet类预测映射到16个类别。 ImageNet类别虎斑猫将被映射到cat。 总的来说,本研究中的结果基于48,560项心理物理试验和97名参与者。
- 数据集
为了评估纹理和形状偏差,我们进行了六个主要实验以及三个对照实验,这些实验在附录中描述。 前五个实验(图2中可视化的样本)是简单的对象识别任务,唯一的区别是参与者可用的图像特征:
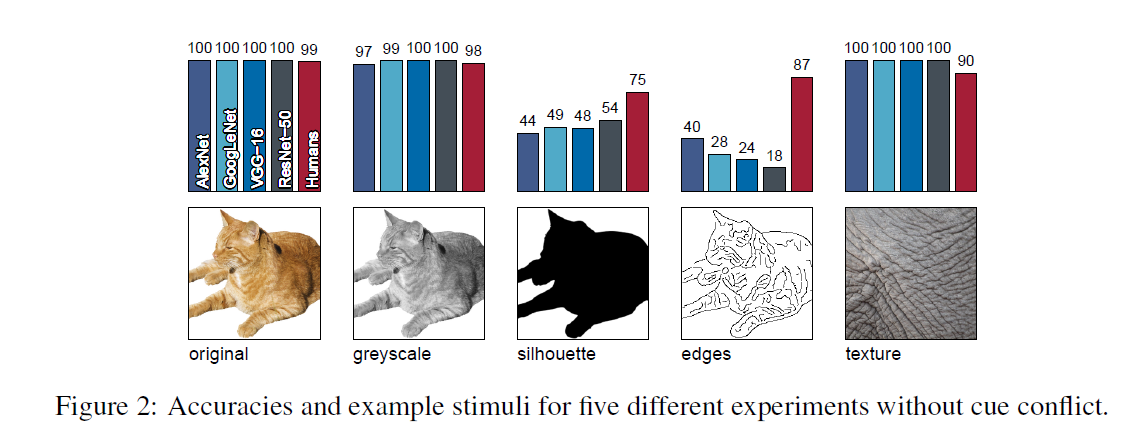
原始。160个白色背景的自然彩色图像的对象(每类10个)。
Greyscale。原始数据集中的图像使用skimage.color.rgb2gray转换为灰度。 对于CNN,沿着颜色通道堆叠灰度图像
Silhouette。原始数据集中的图像转换为轮廓图像,在白色背景上显示完全黑色的对象(有关步骤,请参阅附录A.6)。
Edges。使用在MATLAB中实现的Canny边缘提取器将原始数据集中的图像转换为基于边缘的表示。
Texture。纹理的48个自然彩色图像(每类3个)。 通常,纹理由动物的全宽贴片(例如皮肤或毛皮)组成,或者特别是对于人造物体,由具有相同物体的多次重复的图像组成(例如,彼此相邻的许多瓶子,参见图7中的 附录)。

值得注意的是,我们只选择了由所有四个网络正确分类的对象和纹理图像。 这是为了确保我们在关于提示冲突的第六个实验中的结果是完全可解释的,这在形状与纹理假设方面是最具决定性的。 在提示冲突实验中,我们呈现具有矛盾特征的图像(参见图1),但仍然要求参与者分配单个类。 请注意,对人类观察者的指示是完全中立的w.r.t. 形状或纹理(“点击您在呈现的图像中看到的对象类别;猜测是否不确定。没有正确或错误的答案,我们对您的主观印象感兴趣”)。
Cue conflict。使用迭代样式转移(Gatys等人,2016)在纹理数据集(作为样式)的图像和来自原始数据集(作为内容)的图像之间生成的图像。 我们共生成了1280个提示冲突图像(每个类别80个),允许在单个实验会话中向人类观察者进行演示。
我们将“轮廓”定义为2D中对象的边界轮廓(即,对象分割的轮廓)。 当提到“对象形状”时,我们使用比仅仅对象的轮廓更宽的定义:我们指的是描述对象的3D形式的轮廓集,即包括不是轮廓的一部分的那些轮廓。 继Gatys等人之后(2017),我们将“纹理”定义为具有空间静态统计的图像(区域)。 注意,在非常局部的层面上,纹理(根据该定义)可以具有非静止元素(例如局部形状):例如, 一个瓶子显然有非平稳的统计数据,但许多瓶子彼此相邻被认为是一种质地:“things”变成“stuff”(Gatys等,2017,第178页)。 有关“瓶子纹理”的示例,请参见图7。
- STYLIZED-IMAGENET
从ImageNet开始,我们通过剥离其原始纹理的每一个图像,并通过AdaIN样式转移(Huang&Belongie,2017)将其替换为随机选择的绘画风格,构建了一个新的数据集(称为Stylized-ImageNet或SIN)(参见 图3中的示例),其样式化系数= 1.0。 我们使用Kaggle的Painter by Numbers数据集作为风格来源,因为它的风格多样和大小(79,434幅画)。 我们使用AdaIN快速风格转移而不是迭代风格化(例如Gatys等,2016)有两个原因:首先,确保使用不同的程式化技术完成SIN训练和提示冲突刺激测试,结果不会依靠单一的程式化方法。 其次,为了实现整个ImageNet的风格化,使用迭代方法需要过长的时间。 我们提供了在这里创建Stylized-ImageNet的代码:
https://github.com/rgeirhos/Stylized-ImageNet

- 实验结果
- 人和ImageNet训练的CNN的内容与形状偏置对比
CNN和人类几乎都能正确识别所有物体和纹理图像(原始和纹理数据集)(图2)。 对象的灰度版本仍然包含形状和纹理,同样被认可。 当物体轮廓用黑色填充以产生轮廓时,CNN识别精度远低于人类精确度。 这对于边缘刺激来说甚至更加明显,这表明人类观察者对具有很少或没有纹理信息的图像处理得更好。 在这些实验中的一个混淆是CNN倾向于不能很好地应对域移位,即图像统计从自然图像(网络已被训练)到草图(网络以前从未见过)的大的变化。
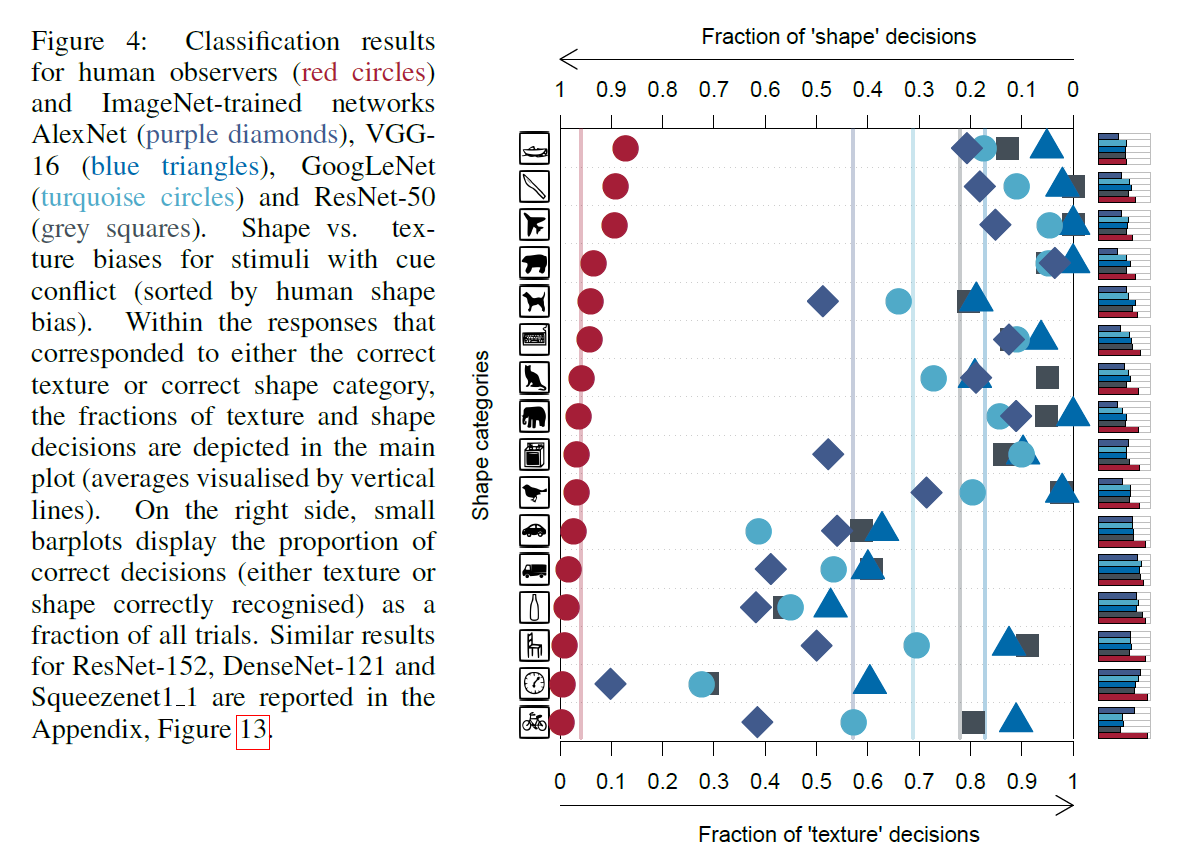
因此,我们设计了一个提示冲突实验,该实验基于具有自然统计的图像,但与纹理和形状证据相矛盾(参见方法)。 参与者和CNN必须根据他们最依赖的特征(形状或纹理)对图像进行分类。 图4中显示了该实验的结果。人类观察者对形状类别(95.9%的正确决策)的反应表现出明显偏向.CNN的这种模式是相反的,这显示了对纹理类别的响应的明显偏见 (VGG-16:形状为17.2%,纹理为82.8%; GoogLeNet:31.2%对68.8%; AlexNet:42.9%对57.1%; ResNet-50:22.1%对77.9%)。
- 克服CNNS的纹理偏见
心理物理实验表明,ImageNet训练的CNN,但不是人类,表现出强烈的纹理偏差。 一个原因可能是训练任务本身:从Brendel&Bethge(2019)我们知道ImageNet可以仅使用本地信息以高精度求解。 换句话说,它可能只需要整合来自许多局部纹理特征的证据,而不是经历整合和分类全局形状的过程。 为了测试这个假设,我们在Stylized-ImageNet(SIN)数据集上训练了一个ResNet-50,其中我们用随机选择的艺术绘画的无信息风格取代了与物体相关的局部纹理信息。
在Stylized-ImageNet(SIN)上训练和评估的标准ResNet-50达到了79.0%的前5精度(见表1)。 相比之下,在ImageNet(IN)上训练和评估的相同架构实现了92.9%的前5精度。 这种性能差异表明SIN是一项比IN更难的任务,因为纹理不再是预测性的,而是一种令人讨厌的因素(根据需要)。 有趣的是,ImageNet的功能很难概括为SIN(只有16.4%的前5精度); 然而,在SIN上学到的特征很好地概括了ImageNet(82.6%的前5精度,没有任何微调)。
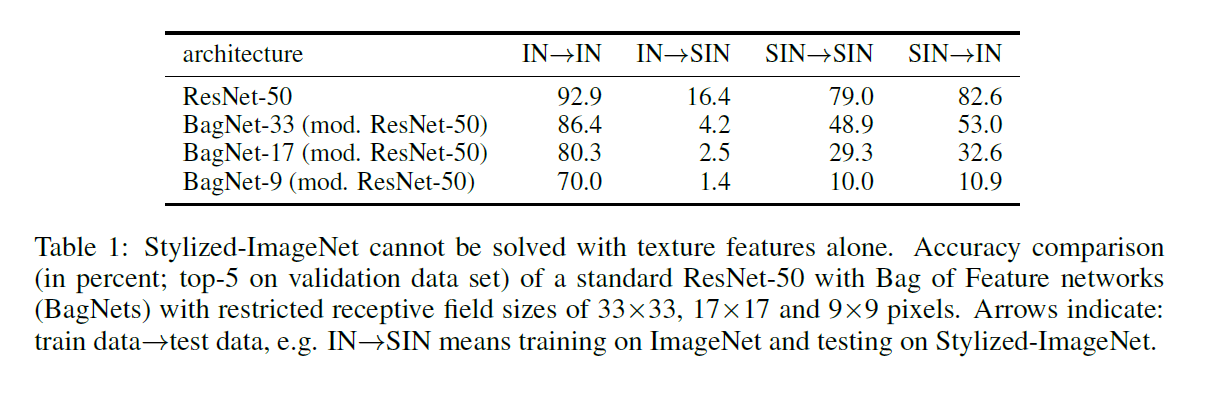
为了测试局部纹理特征是否仍然足解决SIN,我们评估所谓的BagNets的性能。 最近由Brendel&Bethge(2019)推出,BagNets采用ResNet-50架构,但其最大感受区域尺寸限制为9X9,17X17或33X33像素。 这使得BagNets无法学习或使用任何远程空间关系进行分类。 虽然这些受限制的网络可以在ImageNet上达到很高的准确度,但它们无法在SIN上实现相同的效果,显示出较小的感知字段大小(例如SIN的前5精度为10.0%,而对于BagNet的ImageNet为70.0%, 感受野大小为9X9像素)。 这清楚地表明我们提出的SIN数据集确实去除了局部纹理线索,迫使网络整合远程空间信息。
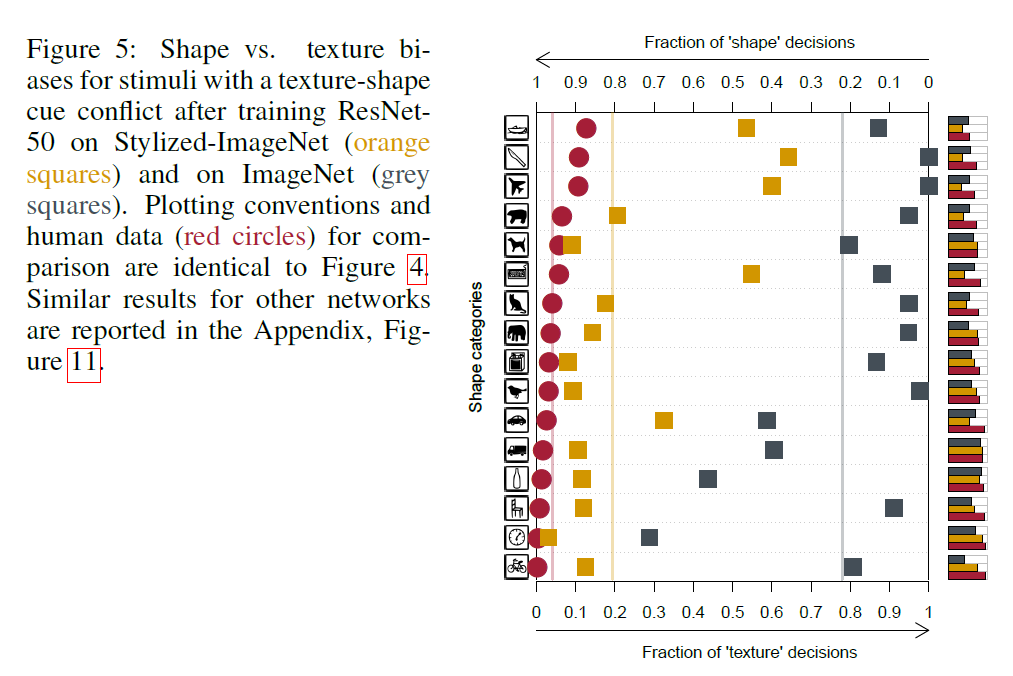
最重要的是,SIN训练的ResNet-50在我们的线索冲突实验中显示出更强的形状偏置(图5),从IN训练模型的22%增加到81%。 在许多类别中,形状偏置几乎与人类一样强烈。
- 基于形状表示的稳健性和准确
增加的形状偏差以及因此移位的表示是否也会影响CNN的性能或稳健性? 除了IN和SIN训练的ResNet-50架构,我们还在此处分析了两种联合训练方案:
- SIN和IN联合训练。
- 对SIN和IN进行联合训练,对IN进行微调。 我们将此模型称为Shape-ResNet。
然后,我们在三个实验中将这些模型与vanilla ResNet-50进行了比较:(1)IN的分类性能,(2)转移到Pascal VOC 2007和(3)抗图像扰动的稳健性。
分类性能。如表2所示,Shape-ResNet在top-1和Top-5 ImageNet验证精度方面超过了vanilla ResNet。这表明SIN可能是一个有用的数据ImageNet上的扩充,可以在不进行任何体系结构更改的情况下提高模型性

迁移学习。我们在Pascal VOC 2007上测试了每个模型的表示作为更快的R-CNN(Ren等人,2017)的主干特征。在训练数据中加入SIN大大提高了物体检测性能,从70.7到75.1 mAP50,如表所示 2.这符合直觉,即对于物体检测,基于形状的表示比基于纹理的表示更有益,因为包含物体的地面实况矩形通过设计与全局物体形状对齐。
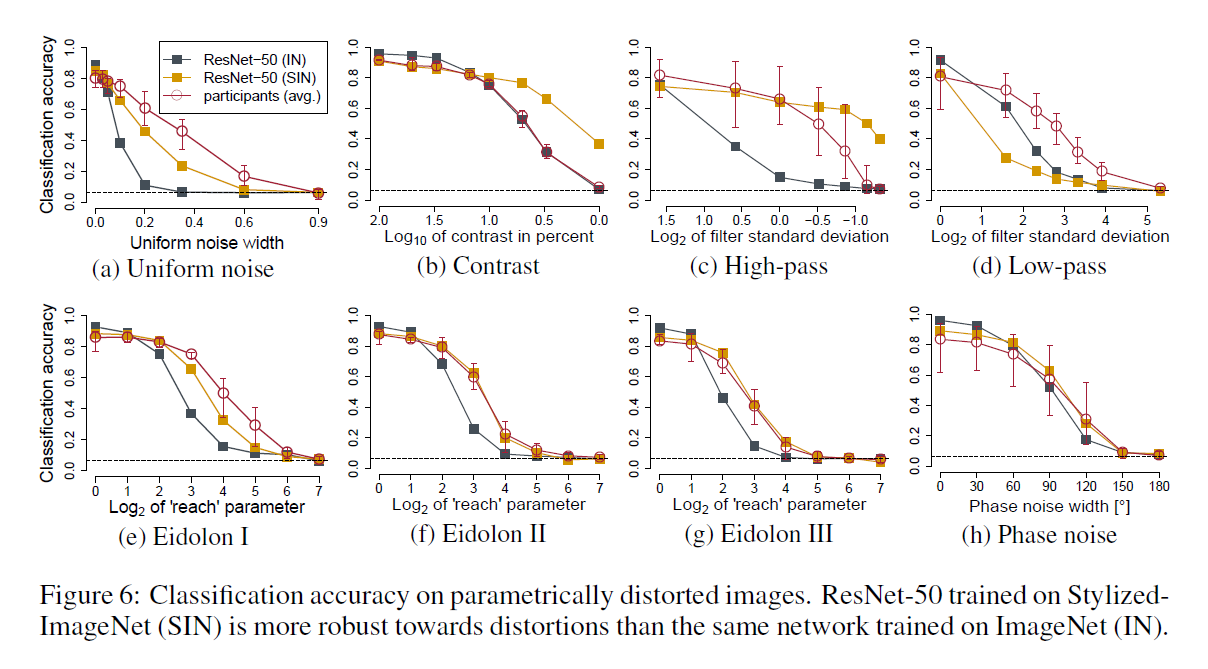
抗扰动的稳健性。我们系统地测试了如果图像被均匀或相位噪声,对比度变化,高通和低通滤波或幻象扰动扭曲,模型精度如何降低。这种比较的结果,包括供参考的人类数据,见图6。在未失真图像上缺少几个百分点的准确度时,SIN训练的网络在几乎所有图像处理上都优于IN训练的CNN。 (低通滤波/模糊是SIN训练网络更容易受到影响的唯一失真类型,这可能是由于通过绘画在SIN中高频信号的过度表现以及对尖锐边缘的依赖。) 训练有素的ResNet-50可以实现人类级失真的稳健性 - 尽管在训练期间从未发现任何扭曲现象。
此外,我们为ImageNet-C测试的模型提供了稳健性结果,ImageNet-C是15种不同图像损坏的综合基准(Hendrycks&Dietterich,2019),见附录表4。 SIN和IN联合训练导致13种腐败类型的强烈改进(高斯,射击和脉冲噪声;散焦,格拉斯和运动模糊;雪,霜和雾天气类型;对比度,弹性,像素化和JPEG数字腐败)。 这大大降低了整体腐败错误率,从vanilla ResNet-50的76.7降至69.3。 同样,这些腐败类型中没有一个明确地是训练数据的一部分,强化了在训练体制中结合SIN以非常一般的方式改进模型稳健性。
- 讨论
如引言中所述,CNN使用越来越复杂的形状特征来识别物体的共同假设与最近的实证研究结果之间似乎存在很大的差异,而这些研究结果表明物体纹理的关键作用。为了明确地探究这个问题,我们利用风格转移(Gatys et al。,2016)来生成具有相互矛盾的形状和纹理信息的图像。在有控制的心理物理实验室环境中对CNN和人类观察者进行广泛实验的基础上,我们提供证据表明,与人类不同,ImageNet训练的CNN倾向于根据局部纹理而不是全局物体形状对物体进行分类。与之前的工作相结合,表明改变其他主要对象尺寸,如颜色(Geirhos等,2018)和物体尺寸相对于背景(Eckstein等,2017)不会对CNN识别性能产生强烈的不利影响,这突出了纹理等局部线索在CNN对象识别中的特殊作用。
有趣的是,这为许多相当不连贯的发现提供了解释:CNN符合人类的纹理外观(Wallis等,2017),以及它们对神经反应的预测能力。人脸识别似乎主要是由于类似人的纹理表征,而不是人类的轮廓表示(Laskar等,2018; Long&Konkle,2018)。此外,基于纹理的生成建模方法,如样式转移(Gatys等,2016),单图像超分辨率(Gondal等,2018)以及静态和动态纹理合成(Gatys等,2015; Funke等人,2017)都使用标准CNN产生了优异的结果,而基于CNN的形状转移似乎非常困难(Gokaslan等,2018)。美国有线电视新闻网仍然可以识别出混乱形状的图像(Gatys et al。,2017; Brendel&Bethge,2019),但是他们在识别缺少纹理信息的物体时遇到了更多困难(Ballester&de Ara'ujo,2016; Yu等, 2017年)。我们的假设也可以解释为什么在合成纹理图像数据库上训练的图像分割模型转移到自然图像和视频(Ustyuzhaninov等,2018)。除此之外,我们的结果显示ImageNet训练的CNN和人类观察者之间存在明显的行为差异。虽然人类和机器视觉系统在标准图像上实现了类似的高精度(Geirhos等,2018),但我们的研究结果表明,潜在的分类策略可能实际上非常不同。 这是有问题的,因为CNN被用作人类对象识别的计算模型(例如,Cadieu等人,2014; Yamins等人,2014)。
为了减少CNN的纹理偏差,我们引入了Stylized-ImageNet(SIN),这是一种通过样式转移消除局部线索的数据集,从而迫使网络超越纹理识别。 使用这个数据集,我们证明ResNet-50架构确实可以学习基于物体形状识别物体,揭示当前CNN中的纹理偏差不是设计而是由ImageNet训练数据引起。 这表明标准的ImageNet训练模型可能会通过关注局部纹理来获取“快捷方式”,这可以被视为奥卡姆剃刀的一个版本:如果纹理足够,为什么CNN应该学到更多其他东西呢? 虽然纹理分类可能比形状识别更容易,但我们发现在SIN上训练的基于形状的特征很好地概括为自然图像。
我们的结果表明,更多基于形状的表示可以有益于依赖于预训练的ImageNet CNN的识别任务。此外,虽然ImageNet训练的CNN概括我们在Stylized-ImageNet上接受过训练的ResNet-50经常达到甚至超过人类级别的稳健性(没有接受过训练,因此对于大范围的图像扭曲(例如2017年的Dodge&Karam; Geirhos等,2017; 2018)特定图像降级。这令人兴奋,因为Geirhos等人 (2018)表明,对特定失真进行训练的网络通常不能获得针对其他未见图像处理的鲁棒性。这种新兴行为突出了基于形状的表示的有用性:虽然局部纹理容易被各种噪声(包括现实世界中的那些噪声,例如雨和雪)扭曲,但是对象形状保持相对稳定。此外,这一发现为人类在应对扭曲时的令人难以置信的稳健性提供了一个非常简单的解释:基于形状的表示。
- 总结
总之,我们提供的证据表明,今天的机器识别过度依赖于对象纹理而不是通常假设的全局对象形状。 我们展示了基于形状的表示对强大推理的优势(使用我们的Stylized-ImageNet数据集在神经网络中引入这种表示)。 我们设想我们的发现以及我们公开可用的模型权重,代码和行为数据集(97个观察者的49K试验)以实现三个目标:首先,更好地理解CNN表示和偏置。 其次,迈向更合理的人类视觉对象识别模型。 第三,这是未来事业的有用起点,其中领域知识表明基于形状的表示可能比基于纹理的表示更有益。















 2687
2687











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









