






python语言实现语音合成(文字转语音)
在Python中实现文本到语音——语音朗读功能,可以使用pyttsx3库。pyttsx3库的安装和使用也相对简单,但在控制语音的暂停、继续和停止功能方面可能存在一定的困难。
首先,您需要安装pyttsx3库(如果您还没有安装的话):
pip install pyttsx3
如果你的电脑上安装了多个Python版本,你可以为特定版本的Python安装模块(库、包),还可以使用国内的镜像加快安装速度。例如我的电脑中安装了多个Python版本,要在Python 3.10版本中安装,并使用清华的镜像,cmd命令行中,输入如下命令:
py -3.10 -m pip install pyttsx3 -i https://pypi.tuna.tsinghua.edu.cn/simple
先看一个简单的文本界面的例子:
import pyttsx3
# 初始化TTS引擎
engine = pyttsx3.init()
# 设置属性,例如语速和音量
engine.setProperty('rate', 150) # 语速,可以设置为您想要的值
engine.setProperty('volume', 0.9) # 音量,范围是0.0到1.0
# 获取并设置语音属性
voices = engine.getProperty('voices')
for voice in voices:
# 检查语音对象是否有语言属性,并且列表不为空
if voice.languages and 'zh' in voice.languages[0]:
engine.setProperty('voice', voice.id)
break
# 定义朗读文本的函数
def speak(text):
engine.say(text)
engine.runAndWait()
# 使用函数朗读文本
speak("您好,这是一个Python实现的语音朗读示例。")
# 更改语音和语言
for voice in voices:
# 检查语音对象是否有语言属性,并且列表不为空
if voice.languages and 'en' in voice.languages[0]:
engine.setProperty('voice', voice.id)
break
speak("Hello, this is an example of speech synthesis in Python.")
下面给出一个简单的图形用户界面的例子
先给出效果图:
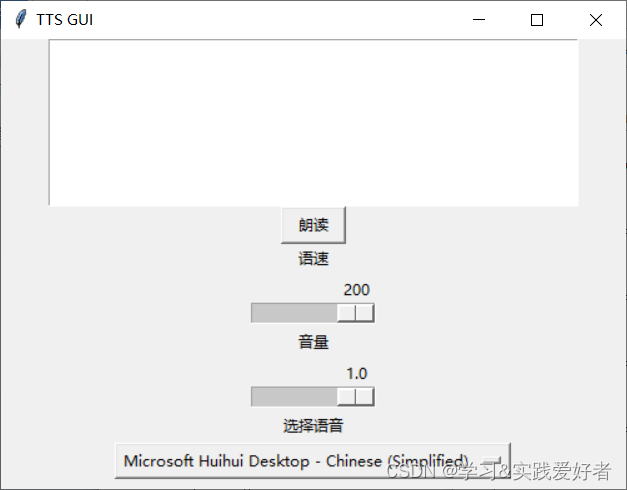
【顺便提示,没有提供“暂停”、“继续”和“停止”按钮,因为使用pyttsx3 想控制语音的暂停、继续和停止功能比较困难,主要是因为 pyttsx3 的 API 设计并不直接支持这些功能。在 pyttsx3 中,语音合成通常是在引擎内部一次性完成的,而不是分段进行的。因此,pyttsx3 没有提供直接的方法来暂停或继续已经开始的合成过程。
有人说,用pyttsx3实现暂停、继续和停止功能,需要使用一些额外的策略和代码,比较复杂,这可能包括处理异步事件、控制语音合成的进度,以及处理可能出现的异常情况,我也没搞懂就不介绍了。
另外,有几个库支持文本到语音(TTS)的暂停、继续和停止功能,如:
gtts (Google Text-to-Speech):
暂停和继续功能: 支持通过调用 gtts.tts.stop() 和 gtts.tts.resume() 方法来暂停和继续朗读。
停止功能: 可以通过 gtts.tts.stop() 方法来停止朗读。
安装: pip install gtts
espeak:
暂停和继续功能: 支持通过调用 espeak.synth.pause() 和 espeak.synth.resume() 方法来暂停和继续朗读。
停止功能: 可以通过 espeak.synth.cancel() 方法来停止朗读。
安装: pip install espeak-ng(如果需要图形界面)
目前我也了解不多,就不多说了。】
源码如下:
import pyttsx3
import tkinter as tk
# 初始化TTS引擎
engine = pyttsx3.init()
# 设置属性的默认值
rate = engine.getProperty('rate')
volume = engine.getProperty('volume')
voices = engine.getProperty('voices')
# 定义朗读文本的函数
def speak():
text = text_area.get("1.0", tk.END).strip()
engine.say(text)
engine.runAndWait()
# 设置语速
def set_rate(value):
engine.setProperty('rate', int(value))
# 设置音量
def set_volume(value):
engine.setProperty('volume', float(value))
# 设置语音
def set_voice(value):
# 找到与所选名称对应的语音对象
selected_voice = next((voice for voice in voices if voice.name == value), None)
if selected_voice:
engine.setProperty('voice', selected_voice.id)
# 创建主窗口
root = tk.Tk()
root.title("TTS GUI")
root.geometry("500x360")
# 创建文本区域
text_area = tk.Text(root, height=10, width=60)
text_area.pack()
# 创建按钮
speak_button = tk.Button(root, text="朗读", command=speak,width=6 ,relief="raised", bd=2)
speak_button.pack()
# 创建滑动条来控制语速
rate_label = tk.Label(root, text="语速")
rate_label.pack()
rate_slider = tk.Scale(root, from_=100, to=200, orient='horizontal', command=set_rate)
rate_slider.set(rate) # 设置默认值
rate_slider.pack()
# 创建滑动条来控制音量
volume_label = tk.Label(root, text="音量")
volume_label.pack()
volume_slider = tk.Scale(root, from_=0.0, to=1.0, resolution=0.1, orient='horizontal', command=set_volume)
volume_slider.set(volume) # 设置默认值
volume_slider.pack()
# 创建下拉菜单来选择语音
voice_label = tk.Label(root, text="选择语音")
voice_label.pack()
voice_var = tk.StringVar(root)
voice_var.set(voices[0].name) # 设置默认值
voice_dropdown = tk.OptionMenu(root, voice_var, *[voice.name for voice in voices], command=set_voice)
voice_dropdown.pack()
# 运行主循环
root.mainloop()
















 7373
7373











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











