






 文章指导用户如何准备音频数据集,调整设置,更换自己的数据,并使用PaddleSpeech进行语音合成。用户需上传24000采样率的干净人声音频,然后运行代码以合成特定句子并试听或下载生成的音频。
文章指导用户如何准备音频数据集,调整设置,更换自己的数据,并使用PaddleSpeech进行语音合成。用户需上传24000采样率的干净人声音频,然后运行代码以合成特定句子并试听或下载生成的音频。
代码在文章最后!!!
目录
1.音频数据集(自制)
提前准备好6段以上音频文件
音频不要太长,也不要太短,建议2s~10s之间
音频尽量是干净人声,不要有BGM声音
保存为 24000采样率(在格式工厂里面更改)格式工厂如何更改采样格式?格式工厂更改采样格式教程_媒体工具_软件教程_脚本之家 (jb51.net)
data:wav/mp3/ogg格式
点击 ,进入 目录上传音频数据到data里面( ), 数据大小不超过 150M
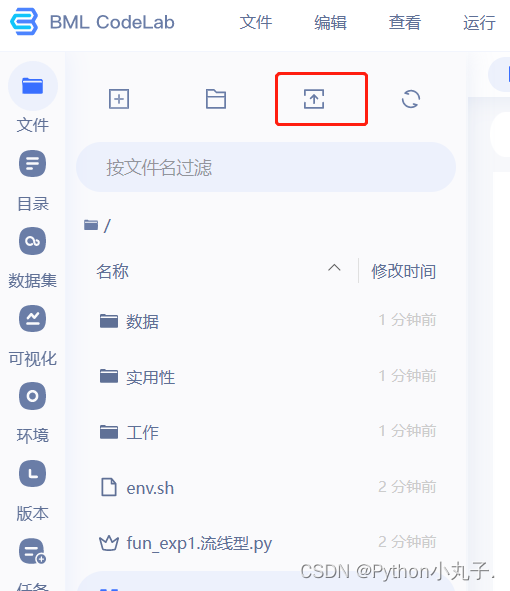
2.更改设置
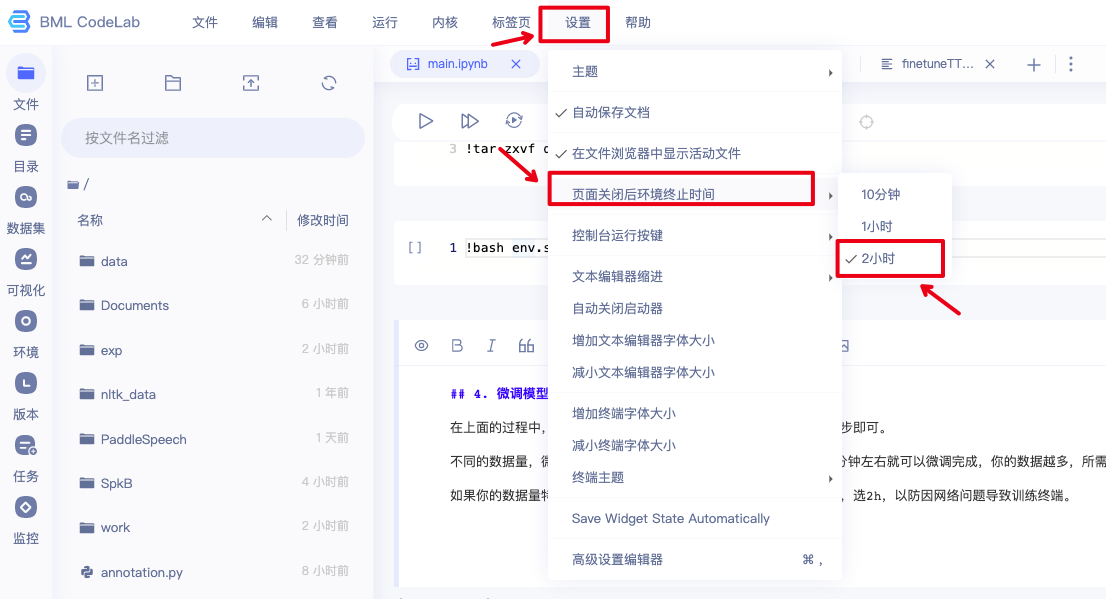
3.换自己的数据集
将这示例1代码全部注释,这里我们使用示例3,将示例3代码打开,并检查数据集位置是不是和第一步上传数据集位置相同
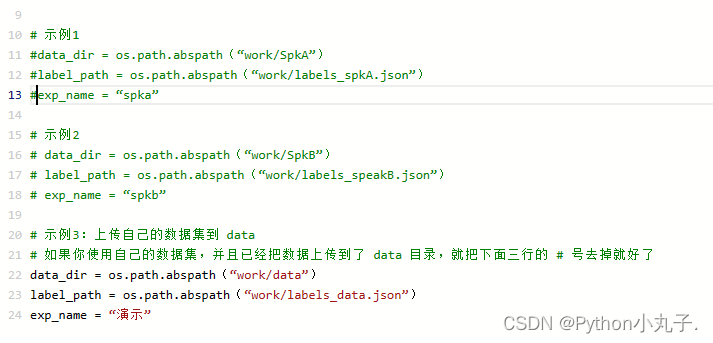
4.依次运行接下来的代码,
5.合成句子
在这里换自己相合成的句子 "1": "欢迎使用 Paddle Speech 做智能语音开发工作。"
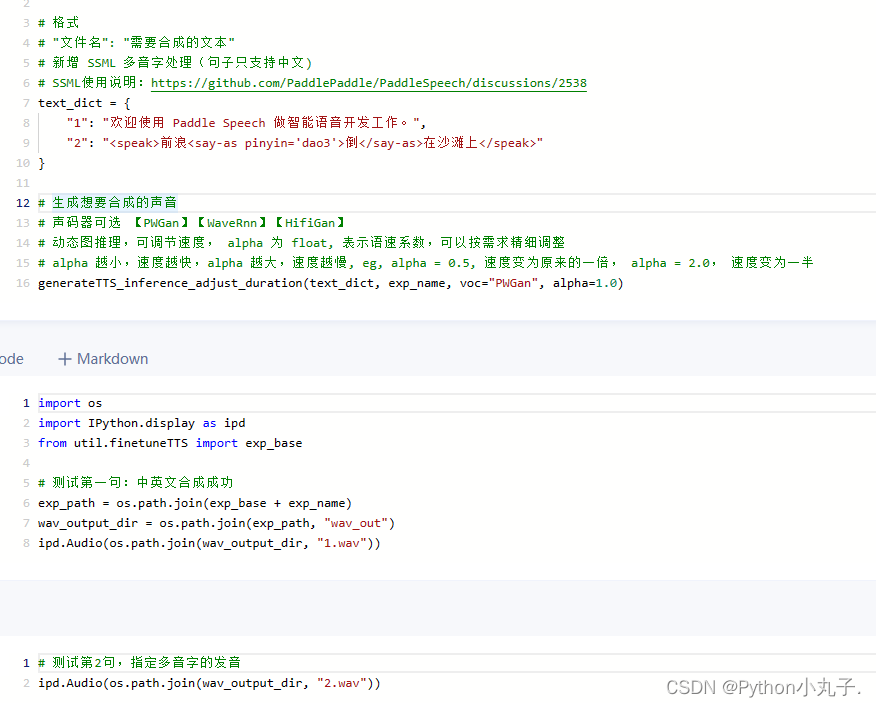
6.成功试听/下载音频
7.代码源码
发现一个大佬的语音合成:路径在这里

















 853
853

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









