









Python + edge_tts实现朗读文本工具
这是个文本转语音个工具可以用来听书等比较实用,这个工具是GUI(Graphical User Interface,图形用户界面)界面。
本程序需要安装两个第三方库
edge-tts pygame
这种组合使得程序可以在不依赖网页浏览器的情况下,提供专业级的文本到语音转换服务,支持多种语言和声音选项,并具有调整语速、音量等高级功能。
edge-tts在程序中的作用:
提供与微软 Edge 浏览器中的文本转语音 (TTS) 服务相同的功能
获取可用的语音列表(不同语言、性别和风格的语音)
将文本转换为高质量的语音音频
支持调整语速
允许音频流式传输和保存
pygame在程序中的作用:
提供音频播放功能,主要使用其中的 mixer 模块
播放 edge-tts 生成的语音
控制音频播放状态(播放/停止)
调整音频播放音量
还使用了Python的标准库的组成模块(它们随Python一起安装了):
asyncio - 用于编写异步代码,支持并发执行操作。
threading - 提供线程的支持,允许你在程序中并行运行多个任务。
os - 提供了与操作系统交互的功能。
time - 提供时间相关的函数。
基本版本
先给出一个简单版本,运行效果:
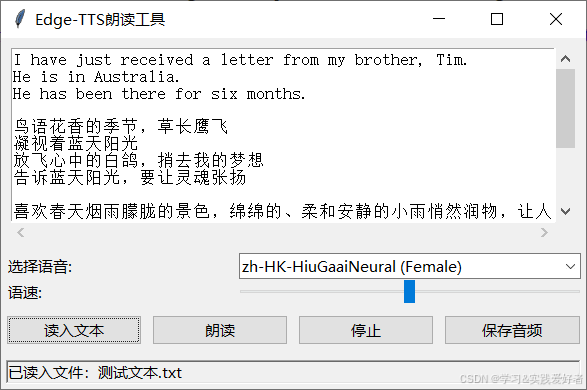
源码如下:
import tkinter as tk
from tkinter import ttk, filedialog, messagebox
import edge_tts
import asyncio
import threading
from pygame import mixer
import io
import os
class EdgeTTSApp:
def __init__(self, root):
self.root = root
self.root.title("Edge-TTS朗读工具")
self.setup_ui()
self.voices = []
self.current_audio = None
self.is_playing = False
mixer.init()
# 初始化语音列表
self.load_voices()
def setup_ui(self):
self.root.columnconfigure(0, weight=1)
self.root.rowconfigure(0, weight=1) # 文本框所在行
self.root.rowconfigure(3, weight=0) # 按钮行保持固定高度
# 文本输入框
# 创建文本框容器框架
text_frame = ttk.Frame(self.root)
text_frame.grid(row=0, column=0, columnspan=4, padx=10, pady=10, sticky="nsew")
text_frame.columnconfigure(0, weight=1) # 配置框架内部权重
text_frame.rowconfigure(0, weight=1)
# 文本输入框带滚动条
self.text_input = tk.Text(text_frame, wrap=tk.WORD, height=10, width=60)
vsb = ttk.Scrollbar(text_frame, orient="vertical", command=self.text_input.yview)
hsb = ttk.Scrollbar(text_frame, orient="horizontal", command=self.text_input.xview)
self.text_input.configure(yscrollcommand=vsb.set, xscrollcommand=hsb.set)
self.text_input.grid(row=0, column=0, sticky="nsew")
vsb.grid(row=0, column=1, sticky="ns")
hsb.grid(row=1, column=0, sticky="ew")
text_frame.grid_rowconfigure(0, weight=1)
text_frame.grid_columnconfigure(0, weight=1)
# 语音选择
self.voice_label = ttk.Label(self.root, text="选择语音:")
self.voice_label.grid(row=1, column=0, padx=5, sticky='w')
self.voice_combo = ttk.Combobox(self.root, width=35)
self.voice_combo.grid(row=1, column=1, padx=5, sticky='ew') # , sticky='ew'
# 语速调节
self.rate_label = ttk.Label(self.root, text="语速:")
self.rate_label.grid(row=2, column=0, padx=5, sticky='w')
self.rate_scale = ttk.Scale(self.root, from_=-50, to=50, length=200)
self.rate_scale.set(0)
self.rate_scale.grid(row=2, column=1, padx=5, sticky='ew') # , sticky='ew'
# 按钮区域
# 按钮区域使用独立框架
btn_frame = ttk.Frame(self.root)
btn_frame.grid(row=3, column=0, columnspan=4, pady=10, sticky="ew")
# 使用更紧凑的网格布局
self.load_text_btn = ttk.Button(btn_frame, text="读入文本", command=self.load_text)
self.play_btn = ttk.Button(btn_frame, text="朗读", command=self.play_audio)
self.stop_btn = ttk.Button(btn_frame, text="停止", command=self.stop_audio)
self.save_btn = ttk.Button(btn_frame, text="保存音频", command=self.save_audio)
# 统一按钮宽度并增加间距
buttons = [self.load_text_btn, self.play_btn, self.stop_btn, self.save_btn]
for i, btn in enumerate(buttons):
btn.grid(row=0, column=i, padx=5, sticky="ew")
btn_frame.grid_columnconfigure(i, weight=1)
btn_frame.grid_columnconfigure("all", uniform="btns")
# 状态栏
self.status = ttk.Label(self.root, text="就绪", relief=tk.SUNKEN)
self.status.grid(row=4, column=0, columnspan=3, sticky='we', padx=5, pady=5)
def load_text(self):
file_path = filedialog.askopenfilename(
title="选择文本文件",
filetypes=[
("文本文件", "*.txt"),
("所有文件", "*.*")
]
)
if file_path:
try:
with open(file_path, 'r', encoding='utf-8') as file:
content = file.read()
self.text_input.delete("1.0", tk.END)
self.text_input.insert("1.0", content)
self.status.config(text=f"已读入文件:{os.path.basename(file_path)}")
except Exception as e:
messagebox.showerror("错误", f"无法读取文件:{str(e)}")
try:
# 尝试使用其他编码
with open(file_path, 'r', encoding='gbk') as file:
content = file.read()
self.text_input.delete("1.0", tk.END)
self.text_input.insert("1.0", content)
self.status.config(text=f"已读入文件:{os.path.basename(file_path)}(GBK编码)")
except Exception as e2:
messagebox.showerror("错误", f"尝试其他编码仍无法读取文件:{str(e2)}")
def load_voices(self):
def load_voices_task():
async def get_voices():
return await edge_tts.list_voices()
all_voices = asyncio.run(get_voices())
# 分离中英文语音(根据ShortName判断)
chinese_voices = []
english_voices = []
for voice in all_voices:
short_name = voice.get("ShortName", "").lower()
if short_name.startswith("zh-"):
chinese_voices.append(voice)
elif short_name.startswith("en-"):
english_voices.append(voice)
# 合并列表(中文在前)
self.voices = chinese_voices + english_voices
voice_names = [f"{v['ShortName']} ({v['Gender']})" for v in self.voices]
# 设置默认中文语音
default_name = None
if chinese_voices:
default_name = f"{chinese_voices[0]['ShortName']} ({chinese_voices[0]['Gender']})"
elif voice_names: # 如果没有中文则选第一个英文
default_name = voice_names[0]
# 更新GUI
self.root.after(0, lambda: self.voice_combo.configure(values=voice_names))
if default_name:
self.root.after(0, lambda: self.voice_combo.set(default_name))
else:
self.root.after(0, lambda: self.status.config(text="未找到可用语音"))
threading.Thread(target=load_voices_task, daemon=True).start()
async def generate_audio(self, text, voice, rate):
communicate = edge_tts.Communicate(text, voice, rate=rate)
# 使用内存字节流接收音频数据
audio_stream = io.BytesIO()
async for chunk in communicate.stream():
if chunk["type"] == "audio":
audio_stream.write(chunk["data"])
audio_stream.seek(0) # 重置指针位置
return audio_stream
def play_audio(self):
if self.is_playing:
return
text = self.text_input.get("1.0", tk.END).strip()
if not text:
messagebox.showwarning("警告", "请输入要朗读的文本")
return
voice_index = self.voice_combo.current()
if voice_index < 0:
messagebox.showwarning("警告", "请选择语音")
return
rate = f"+{int(self.rate_scale.get())}%" if self.rate_scale.get() >= 0 else f"{int(self.rate_scale.get())}%"
voice = self.voices[voice_index]['ShortName']
def play_task():
async def generate_and_play():
try:
self.root.after(0, lambda: self.status.config(text="生成音频中..."))
audio_stream = await self.generate_audio(text, voice, rate)
self.root.after(0, lambda: self.status.config(text="播放中..."))
# 使用内存流直接播放
audio_stream.seek(0)
mixer.music.load(audio_stream)
mixer.music.play()
self.is_playing = True
# 等待播放完成
while mixer.music.get_busy():
await asyncio.sleep(0.1)
except Exception as e:
self.root.after(0, lambda: messagebox.showerror("错误", str(e)))
finally:
self.is_playing = False
self.root.after(0, lambda: self.status.config(text="就绪"))
audio_stream.close()
asyncio.run(generate_and_play())
threading.Thread(target=play_task, daemon=True).start()
def stop_audio(self):
if mixer.music.get_busy():
mixer.music.stop()
self.is_playing = False
self.status.config(text="已停止")
def save_audio(self):
text = self.text_input.get("1.0", tk.END).strip()
if not text:
messagebox.showwarning("警告", "请输入要保存的文本")
return
voice_index = self.voice_combo.current()
if voice_index < 0:
messagebox.showwarning("警告", "请选择语音")
return
file_path = filedialog.asksaveasfilename(
defaultextension=".mp3",
filetypes=[("MP3 文件", "*.mp3"), ("WAV 文件", "*.wav")]
)
if not file_path:
return
rate = f"+{int(self.rate_scale.get())}%" if self.rate_scale.get() >= 0 else f"{int(self.rate_scale.get())}%"
voice = self.voices[voice_index]['ShortName']
def save_task():
async def generate_and_save():
self.root.after(0, lambda: self.status.config(text="保存中..."))
communicate = edge_tts.Communicate(text, voice, rate=rate)
await communicate.save(file_path)
self.root.after(0, lambda: self.status.config(text=f"已保存到:{file_path}"))
asyncio.run(generate_and_save())
threading.Thread(target=save_task, daemon=True).start()
if __name__ == "__main__":
root = tk.Tk()
app = EdgeTTSApp(root)
root.mainloop()
优化版本
运行效果:
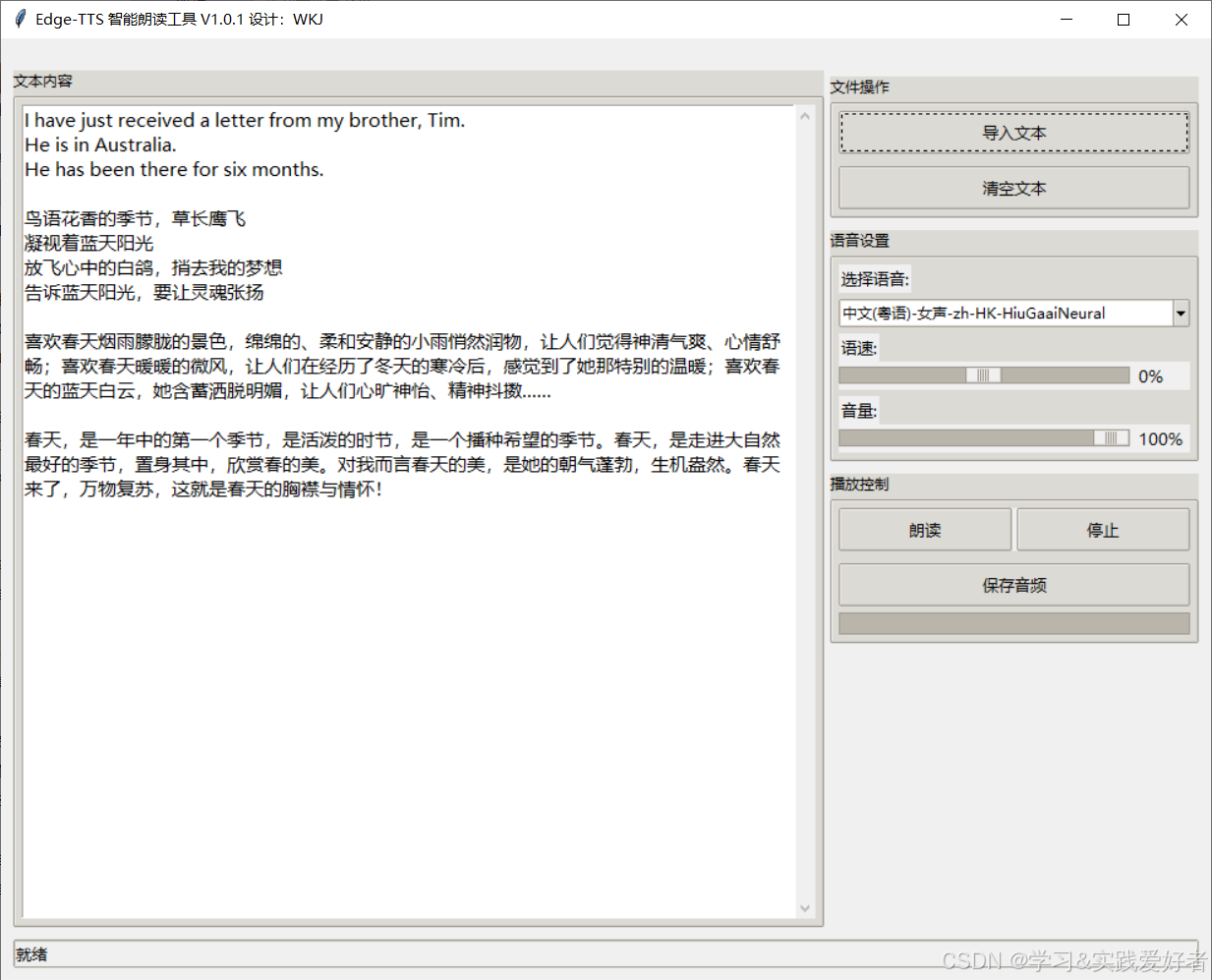
源码如下:
import tkinter as tk
from tkinter import ttk, filedialog, messagebox, scrolledtext
import edge_tts
import asyncio
import threading
from pygame import mixer
import io
import os
from tkinter.font import Font
import time
class EdgeTTSApp:
def __init__(self, root):
self.root = root
self.root.title("Edge-TTS 智能朗读工具 V1.0.1 设计:WKJ")
self.root.geometry("1000x800")
self.root.configure(bg="#f0f0f0")
# 设置主题样式
self.style = ttk.Style()
self.style.theme_use('clam')
self.style.configure('TButton', font=('微软雅黑', 10))
self.style.configure('TLabel', font=('微软雅黑', 10), background="#f0f0f0")
self.style.configure('TFrame', background="#f0f0f0")
self.style.configure('TScale', background="#f0f0f0")
# 变量初始化
self.voices = []
self.current_audio = None
self.is_playing = False
self.audio_length = 0
self.play_start_time = 0
mixer.init()
# 创建UI
self.create_ui()
# 初始化语音列表
self.load_voices()
# 设置定时器更新进度条
self.update_progress()
def create_ui(self):
# 创建主框架
main_frame = ttk.Frame(self.root, padding="10")
main_frame.pack(fill=tk.BOTH, expand=True)
# 创建标题
title_frame = ttk.Frame(main_frame)
title_frame.pack(fill=tk.X, pady=5)
## title_label = ttk.Label(title_frame, text="Edge-TTS 智能朗读工具",
## font=('微软雅黑', 16, 'bold'))
## title_label.pack()
## # 创建分割线
## separator = ttk.Separator(main_frame, orient='horizontal')
## separator.pack(fill=tk.X, pady=5)
# 创建内容区域
content_frame = ttk.Frame(main_frame)
content_frame.pack(fill=tk.BOTH, expand=True, pady=5)
content_frame.columnconfigure(0, weight=1)
content_frame.rowconfigure(0, weight=1)
# 左侧文本区域
text_frame = ttk.LabelFrame(content_frame, text="文本内容")
text_frame.grid(row=0, column=0, sticky="nsew", padx=(0, 5))
# 文本输入框
self.text_input = scrolledtext.ScrolledText(text_frame, wrap=tk.WORD,
font=('微软雅黑', 11))
self.text_input.pack(fill=tk.BOTH, expand=True, padx=5, pady=5)
# 右侧控制区域
control_frame = ttk.Frame(content_frame)
control_frame.grid(row=0, column=1, sticky="nsew")
# 文件操作区
file_frame = ttk.LabelFrame(control_frame, text="文件操作")
file_frame.pack(fill=tk.X, pady=5)
self.load_text_btn = ttk.Button(file_frame, text="导入文本", command=self.load_text)
self.load_text_btn.pack(fill=tk.X, padx=5, pady=5)
self.clear_btn = ttk.Button(file_frame, text="清空文本", command=self.clear_text)
self.clear_btn.pack(fill=tk.X, padx=5, pady=5)
# 语音设置区
voice_frame = ttk.LabelFrame(control_frame, text="语音设置")
voice_frame.pack(fill=tk.X, pady=5)
ttk.Label(voice_frame, text="选择语音:").pack(anchor="w", padx=5, pady=(5, 0))
self.voice_combo = ttk.Combobox(voice_frame, width=38) # 指定宽度
self.voice_combo.pack(fill=tk.X, padx=5, pady=5)
ttk.Label(voice_frame, text="语速:").pack(anchor="w", padx=5)
rate_frame = ttk.Frame(voice_frame)
rate_frame.pack(fill=tk.X, padx=5, pady=(0, 5))
self.rate_scale = ttk.Scale(rate_frame, from_=-50, to=50)
self.rate_scale.set(0)
self.rate_scale.pack(side=tk.LEFT, fill=tk.X, expand=True)
self.rate_label = ttk.Label(rate_frame, text="0%", width=5)
self.rate_label.pack(side=tk.RIGHT, padx=(5, 0))
# 绑定事件
self.rate_scale.configure(command=self.update_rate_label)
ttk.Label(voice_frame, text="音量:").pack(anchor="w", padx=5)
volume_frame = ttk.Frame(voice_frame)
volume_frame.pack(fill=tk.X, padx=5, pady=(0, 5))
self.volume_scale = ttk.Scale(volume_frame, from_=0, to=100)
self.volume_scale.set(100)
self.volume_scale.pack(side=tk.LEFT, fill=tk.X, expand=True)
self.volume_label = ttk.Label(volume_frame, text="100%", width=5)
self.volume_label.pack(side=tk.RIGHT, padx=(5, 0))
# 绑定事件
self.volume_scale.configure(command=self.update_volume_label)
# 播放控制区
play_frame = ttk.LabelFrame(control_frame, text="播放控制")
play_frame.pack(fill=tk.X, pady=5)
button_frame = ttk.Frame(play_frame)
button_frame.pack(fill=tk.X, padx=5, pady=5)
self.play_btn = ttk.Button(button_frame, text="朗读", command=self.play_audio)
self.play_btn.pack(side=tk.LEFT, fill=tk.X, expand=True, padx=(0, 2))
self.stop_btn = ttk.Button(button_frame, text="停止", command=self.stop_audio)
self.stop_btn.pack(side=tk.RIGHT, fill=tk.X, expand=True, padx=(2, 0))
self.save_btn = ttk.Button(play_frame, text="保存音频", command=self.save_audio)
self.save_btn.pack(fill=tk.X, padx=5, pady=5)
# 进度条
progress_frame = ttk.Frame(play_frame)
progress_frame.pack(fill=tk.X, padx=5, pady=(0, 5))
self.progress_bar = ttk.Progressbar(progress_frame, mode="determinate")
self.progress_bar.pack(fill=tk.X)
# 状态栏
## self.status = ttk.Label(main_frame, text="就绪", relief=tk.SUNKEN, anchor=tk.W)
## self.status.pack(fill=tk.X, pady=(5, 0))
self.status = ttk.Label(main_frame, text="就绪", relief=tk.SUNKEN, anchor=tk.W)
self.status.pack(side=tk.BOTTOM, fill=tk.X, pady=(5, 0))
def update_rate_label(self, value):
value = int(float(value))
self.rate_label.config(text=f"{value}%")
def update_volume_label(self, value):
value = int(float(value))
self.volume_label.config(text=f"{value}%")
if mixer.music.get_busy():
mixer.music.set_volume(value / 100)
def clear_text(self):
self.text_input.delete("1.0", tk.END)
self.status.config(text="已清空文本")
def load_voices(self):
def load_voices_task():
async def get_voices():
return await edge_tts.list_voices()
try:
self.status.config(text="正在加载语音列表...")
all_voices = asyncio.run(get_voices())
# 分离中英文语音(根据ShortName判断)
chinese_voices = []
english_voices = []
other_voices = []
for voice in all_voices:
short_name = voice.get("ShortName", "").lower()
if short_name.startswith("zh-"):
chinese_voices.append(voice)
elif short_name.startswith("en-"):
english_voices.append(voice)
else:
other_voices.append(voice)
# 合并列表(中文在前,英文次之,其他语言最后)
self.voices = chinese_voices + english_voices + other_voices
# 语言映射字典
language_map = {
"zh-CN": "中文(普通话)",
"zh-HK": "中文(粤语)",
"zh-TW": "中文(台湾)",
"en-US": "英文(美国)",
"en-GB": "英文(英国)",
"en-AU": "英文(澳大利亚)",
"en-CA": "英文(加拿大)",
"ja-JP": "日文",
"ko-KR": "韩文",
"fr-FR": "法文",
"de-DE": "德文",
"es-ES": "西班牙文",
"ru-RU": "俄文",
"it-IT": "意大利文",
"pt-BR": "葡萄牙文(巴西)",
"pt-PT": "葡萄牙文(葡萄牙)"
}
# 格式化语音名称为:"语言-性别-原始语音名"
voice_names = []
for v in self.voices:
# 获取语言代码和完整名称
short_name = v.get("ShortName", "")
language_code = "-".join(short_name.split("-")[:2])
language_display = language_map.get(language_code, language_code)
# 获取性别
gender = "女声" if v.get("Gender", "") == "Female" else "男声"
# 格式化为:语言-性别-原始语音名
formatted_name = f"{language_display}-{gender}-{short_name}"
voice_names.append(formatted_name)
# 设置默认中文语音
default_index = 0
if chinese_voices:
default_index = 0
elif english_voices:
default_index = len(chinese_voices)
# 更新GUI
self.root.after(0, lambda: self.voice_combo.configure(values=voice_names))
if voice_names:
self.root.after(0, lambda: self.voice_combo.current(default_index))
self.root.after(0, lambda: self.status.config(text="就绪"))
else:
self.root.after(0, lambda: self.status.config(text="未找到可用语音"))
except Exception as e:
self.root.after(0, lambda: self.status.config(text=f"加载语音失败: {str(e)}"))
self.root.after(0, lambda: messagebox.showerror("错误", f"加载语音列表失败: {str(e)}"))
threading.Thread(target=load_voices_task, daemon=True).start()
def load_text(self):
file_path = filedialog.askopenfilename(
title="选择文本文件",
filetypes=[
("文本文件", "*.txt"),
("所有文件", "*.*")
]
)
if file_path:
try:
# 尝试不同编码读取文件
encodings = ['utf-8', 'gbk', 'gb2312', 'big5', 'latin-1']
content = None
used_encoding = None
for encoding in encodings:
try:
with open(file_path, 'r', encoding=encoding) as file:
content = file.read()
used_encoding = encoding
break
except UnicodeDecodeError:
continue
if content is not None:
self.text_input.delete("1.0", tk.END)
self.text_input.insert("1.0", content)
self.status.config(text=f"已读入文件:{os.path.basename(file_path)} ({used_encoding})")
else:
messagebox.showerror("错误", "无法识别文件编码,请尝试其他文件")
except Exception as e:
messagebox.showerror("错误", f"读取文件失败:{str(e)}")
async def generate_audio(self, text, voice, rate):
communicate = edge_tts.Communicate(text, voice, rate=rate)
# 使用内存字节流接收音频数据
audio_stream = io.BytesIO()
async for chunk in communicate.stream():
if chunk["type"] == "audio":
audio_stream.write(chunk["data"])
audio_stream.seek(0) # 重置指针位置
return audio_stream
def play_audio(self):
if self.is_playing:
return
text = self.text_input.get("1.0", tk.END).strip()
if not text:
messagebox.showwarning("警告", "请输入要朗读的文本")
return
voice_index = self.voice_combo.current()
if voice_index < 0:
messagebox.showwarning("警告", "请选择语音")
return
# 从选择的语音名称中提取原始的ShortName
voice = self.voices[voice_index]['ShortName'] # 直接使用原始的ShortName
rate = f"+{int(self.rate_scale.get())}%" if self.rate_scale.get() >= 0 else f"{int(self.rate_scale.get())}%"
voice = self.voices[voice_index]['ShortName']
volume = self.volume_scale.get() / 100
def play_task():
async def generate_and_play():
try:
self.root.after(0, lambda: self.status.config(text="生成音频中..."))
self.root.after(0, lambda: self.play_btn.configure(state='disabled'))
self.root.after(0, self.reset_progress_bar) # Reset progress bar
audio_stream = await self.generate_audio(text, voice, rate)
self.root.after(0, lambda: self.status.config(text="播放中..."))
# 使用内存流直接播放
audio_stream.seek(0)
mixer.music.load(audio_stream)
mixer.music.set_volume(volume)
mixer.music.play()
self.is_playing = True
self.play_start_time = time.time()
# 获取音频长度 (近似值,因为pygame不提供直接获取长度的方法)
self.audio_length = len(text) * 0.2
# 等待播放完成
while mixer.music.get_busy():
await asyncio.sleep(0.1)
except Exception as e:
self.root.after(0, lambda: messagebox.showerror("错误", str(e)))
finally:
self.is_playing = False
self.root.after(0, lambda: self.status.config(text="就绪"))
self.root.after(0, lambda: self.play_btn.configure(state='normal'))
self.root.after(0, self.reset_progress_bar) # Reset progress bar
audio_stream.close()
asyncio.run(generate_and_play())
threading.Thread(target=play_task, daemon=True).start()
def reset_progress_bar(self):
self.progress_bar['value'] = 0
def stop_audio(self):
if mixer.music.get_busy():
mixer.music.stop()
self.is_playing = False
self.status.config(text="已停止")
self.play_btn.configure(state='normal')
self.progress_bar['value'] = 0
def save_audio(self):
text = self.text_input.get("1.0", tk.END).strip()
if not text:
messagebox.showwarning("警告", "请输入要保存的文本")
return
voice_index = self.voice_combo.current()
if voice_index < 0 or voice_index >= len(self.voices):
messagebox.showwarning("警告", "请选择语音")
return
file_path = filedialog.asksaveasfilename(
defaultextension=".mp3",
filetypes=[("MP3 文件", "*.mp3"), ("WAV 文件", "*.wav")]
)
if not file_path:
return
rate = f"+{int(self.rate_scale.get())}%" if self.rate_scale.get() >= 0 else f"{int(self.rate_scale.get())}%"
voice = self.voices[voice_index]['ShortName']
def save_task():
async def generate_and_save():
try:
self.root.after(0, lambda: self.status.config(text="保存中..."))
self.root.after(0, lambda: self.save_btn.configure(state='disabled'))
communicate = edge_tts.Communicate(text, voice, rate=rate)
await communicate.save(file_path)
self.root.after(0, lambda: self.status.config(text=f"已保存到:{file_path}"))
self.root.after(0, lambda: messagebox.showinfo("成功", f"音频已保存到:\n{file_path}"))
except Exception as e:
self.root.after(0, lambda: self.status.config(text=f"保存失败:{str(e)}"))
self.root.after(0, lambda: messagebox.showerror("错误", f"保存音频失败:{str(e)}"))
finally:
self.root.after(0, lambda: self.save_btn.configure(state='normal'))
asyncio.run(generate_and_save())
threading.Thread(target=save_task, daemon=True).start()
def update_progress(self):
"""更新进度条"""
if self.is_playing and self.audio_length > 0:
elapsed = time.time() - self.play_start_time
progress = min(100, (elapsed / self.audio_length) * 100)
self.progress_bar['value'] = progress
# 每100毫秒更新一次
self.root.after(100, self.update_progress)
if __name__ == "__main__":
root = tk.Tk()
app = EdgeTTSApp(root)
root.mainloop()


















 4688
4688

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











