







目录
概述
爬取音乐资源,下载轻音乐。
准备
所需模块
- re
- time
- requests
涉及知识点
- python基础
- requests模块基础
运行效果
控制台打印:

本地文件:

完成爬虫
1. 分析网页(已过期)
打开好听亲音乐网,按F12分析网页
首页的URL:热播榜 - 好听轻音乐网

点击2,第二页的URL如下:http://www.htqyy.com/top/musicList/hot?pageIndex=1&pageSize=20

点击3,第三页的URL如下:http://www.htqyy.com/top/musicList/hot?pageIndex=2&pageSize=20

再点击1,回到第一页,其URL:http://www.htqyy.com/top/musicList/hot?pageIndex=0&pageSize=20

比较第1、2、3页的URL
# 页面的URL
# 第1页:http://www.htqyy.com/top/musicList/hot?pageIndex=0&pageSize=20
# 第2页:http://www.htqyy.com/top/musicList/hot?pageIndex=1&pageSize=20
# 第3页:http://www.htqyy.com/top/musicList/hot?pageIndex=2&pageSize=20
# 故可以得到URL公式:"http://www.htqyy.com/top/musicList/hot?pageIndex="+(页码-1)+"&pageSize=20"就可以通过这个URL获取该网页的HTML源代码:
import requests
# 页面的URL
# 第1页:http://www.htqyy.com/top/musicList/hot?pageIndex=0&pageSize=20
# 第2页:http://www.htqyy.com/top/musicList/hot?pageIndex=1&pageSize=20
# 第3页:http://www.htqyy.com/top/musicList/hot?pageIndex=2&pageSize=20
# 故可以得到URL公式:"http://www.htqyy.com/top/musicList/hot?pageIndex="+(页码-1)+"&pageSize=20"
page_index = 1 # 页码为1,表示第一页
page_url = "http://www.htqyy.com/top/musicList/hot?pageIndex=" + str(page_index - 1) + "&pageSize=20"
html = requests.get(page_url) # 获取音乐榜单的网页信息
txt = html.text # 转换成字符串格式的内容
print(txt)
打印获取到的HTML源代码:

其中这些歌曲列表就是我们需要的
接下来就是分析具体的歌曲,然后下载到本地
点开第一首歌曲:清晨,这首歌的URL是:清晨(New Morning) - 班得瑞(Bandari),清晨在线试听,MP3下载 - 好听轻音乐网
那么这个33是如何来的呢?在HTML源码中的sid属性的值

而具体的音乐资源是:

查看它的URL:http://f2.htqyy.com/play7/33/mp3/11

用浏览器打开上面这个URL,即是可以下载:

现在就可以拼接它的下载的URL:
# 下载歌曲的URL
# 清晨的URL:http://f2.htqyy.com/play7/33/mp3/11
# 月光下的凤尾竹的URL:http://f2.htqyy.com/play7/62/mp3/11
# 故乡的原风景的URL:http://f2.htqyy.com/play7/55/mp3/11
# 故可以得到下载歌曲的URL公式:url="http://f2.htqyy.com/play7/"+sid+"/mp3/11"
# 参数sid的值为页面HTML源代码中的sid属性的值下载单独一首的歌曲代码为:
import requests
# 下载歌曲的URL
# 清晨的URL:http://f2.htqyy.com/play7/33/mp3/11
# 月光下的凤尾竹的URL:http://f2.htqyy.com/play7/62/mp3/11
# 故乡的原风景的URL:http://f2.htqyy.com/play7/55/mp3/11
# 故可以得到下载歌曲的URL公式:url="http://f2.htqyy.com/play7/"+sid+"/mp3/11"
# 参数sid的值为页面HTML源代码中的sid属性的值
song_name = "清晨" # 歌曲的名字
song_url = "http://f2.htqyy.com/play7/33/mp3/11" # 歌曲的URL
data = requests.get(song_url).content # # 获取歌曲的数据,这是二进制数据
print("正在下载第1首:", song_name) # 打印下载提示
with open("{}.mp3".format(song_name), "wb") as file_object: # wb表示以二进制形式写入
# 写入数据
file_object.write(data)
控制台打印成果,下载成功:

1. 分析网页(新接口[2022-05-27])
注意,经过评论区反馈,这个 URL 已经无法访问页面了。所以下面的爬虫代码也不能使用了,不过爬虫变化很快,博客也只是提供分析的思路。
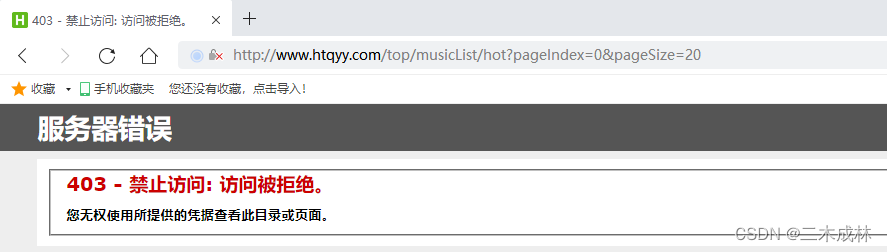
把这个接口拿到 Postman 中去访问,发现也是返回 403。
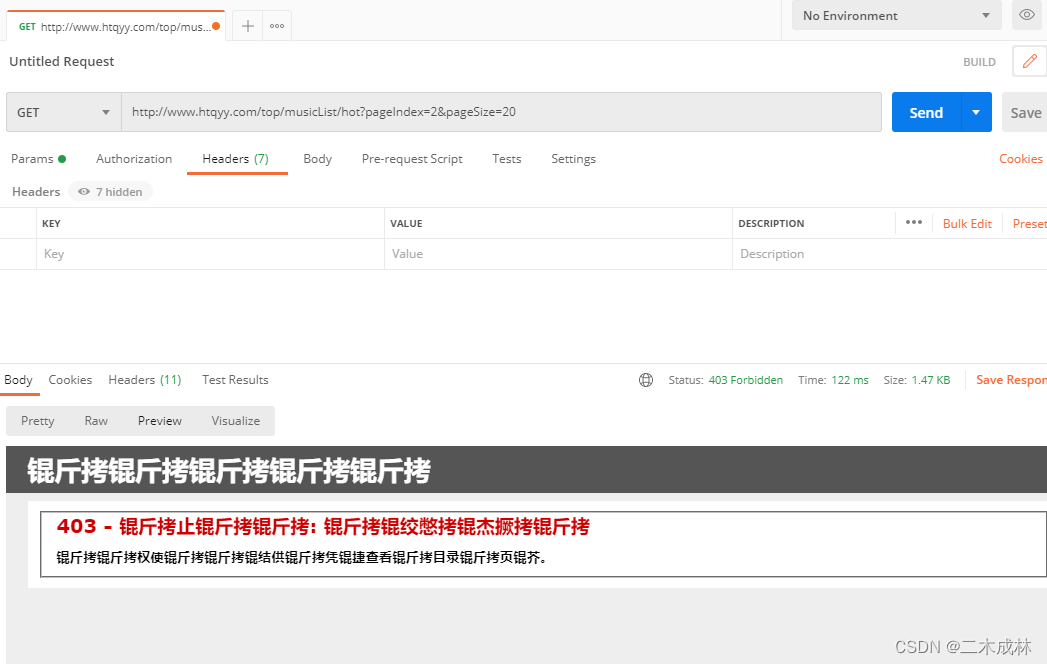
但浏览器却可以看到内容。那么我们加上全部的请求头试试,发现可以访问到内容了。所以解决很简单,加上浏览器的请求头就可以了。
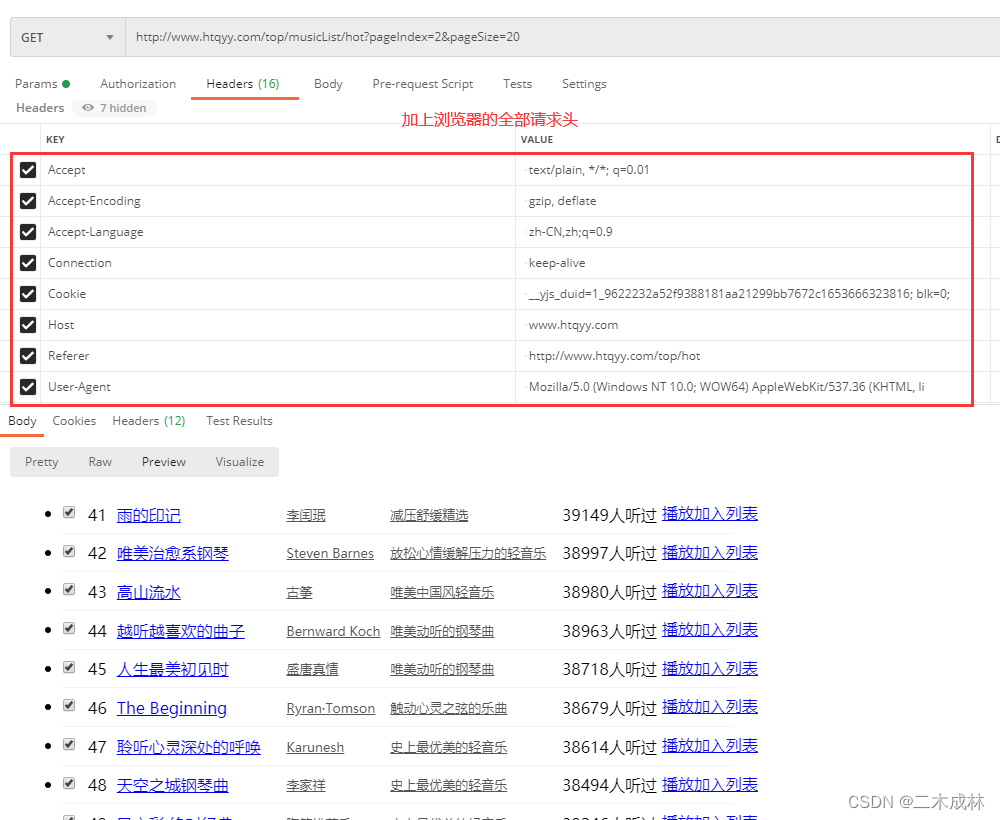
至于代码就没有去改了,需要注意。
2. 爬虫代码
import re # 导入re正则表达式模块
import time # 导入time模块
import requests # 导入requests模块
# 爬虫实战:爬取音乐资源
# 好听轻音乐网:http://www.htqyy.com/
# 页面的URL
# 第1页:http://www.htqyy.com/top/musicList/hot?pageIndex=0&pageSize=20
# 第2页:http://www.htqyy.com/top/musicList/hot?pageIndex=1&pageSize=20
# 第3页:http://www.htqyy.com/top/musicList/hot?pageIndex=2&pageSize=20
# 故可以得到URL公式:"http://www.htqyy.com/top/musicList/hot?pageIndex="+(页码-1)+"&pageSize=20"
# 下载歌曲的URL
# 清晨的URL:http://f2.htqyy.com/play7/33/mp3/11
# 月光下的凤尾竹的URL:http://f2.htqyy.com/play7/62/mp3/11
# 故乡的原风景的URL:http://f2.htqyy.com/play7/55/mp3/11
# 故可以得到下载歌曲的URL公式:url="http://f2.htqyy.com/play7/"+sid+"/mp3/11"
# 参数sid的值为页面HTML源代码中的sid属性的值
song_ids = [] # 存放音乐ID的列表
song_names = [] # 存放音乐名的列表
# 获取音乐的URL
page_number = 3 # 爬取的网页的页数
for page_index in range(0, page_number):
page_url = "http://www.htqyy.com/top/musicList/hot?pageIndex=" + str(page_index) + "&pageSize=20"
html = requests.get(page_url) # 获取音乐榜单的网页信息
txt = html.text # 转换成字符串格式的内容
pat_name = r'title="(.*?)" sid' # 获取音乐的名字。(.*?)是匹配括号中的所有内容
pat_id = r'sid="(.*?)"' # 获取ID,下载音乐所需要的ID
name_list = re.findall(pat_name, txt)
id_list = re.findall(pat_id, txt)
song_ids.extend(id_list) # 将所有的id列表合并到song_ids中
song_names.extend(name_list) # 将所有的歌曲名合并到song_names中
for i in range(0, len(song_ids)):
# 组装歌曲的URL
song_url = "http://f2.htqyy.com/play7/" + str(song_ids[i]) + "/mp3/11"
# 歌曲名字
song_name = song_names[i]
# 获取歌曲的数据
data = requests.get(song_url).content # 二进制数据
# 打印提示
print("正在下载第", i + 1, "首:", song_name)
# 写入到电脑本地
with open("D:\\music\\{}.mp3".format(song_name), "wb") as file_object: # wb表示以二进制形式写入
# 写入数据
file_object.write(data)
# 停留0.5秒
time.sleep(0.5)
这是批量下载轻音乐的爬虫代码
成果如上图所展示的一样。















 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









