







目录
概述
爬取常用的电话号码。
准备
所需模块
- re模块
- requests模块
涉及知识点
- python基础
- requests模块基础
- re模块基础
运行效果
控制台打印(图片截取有限,没有全部截取):

完成爬虫
1. 分析网页
打开常用电话号码
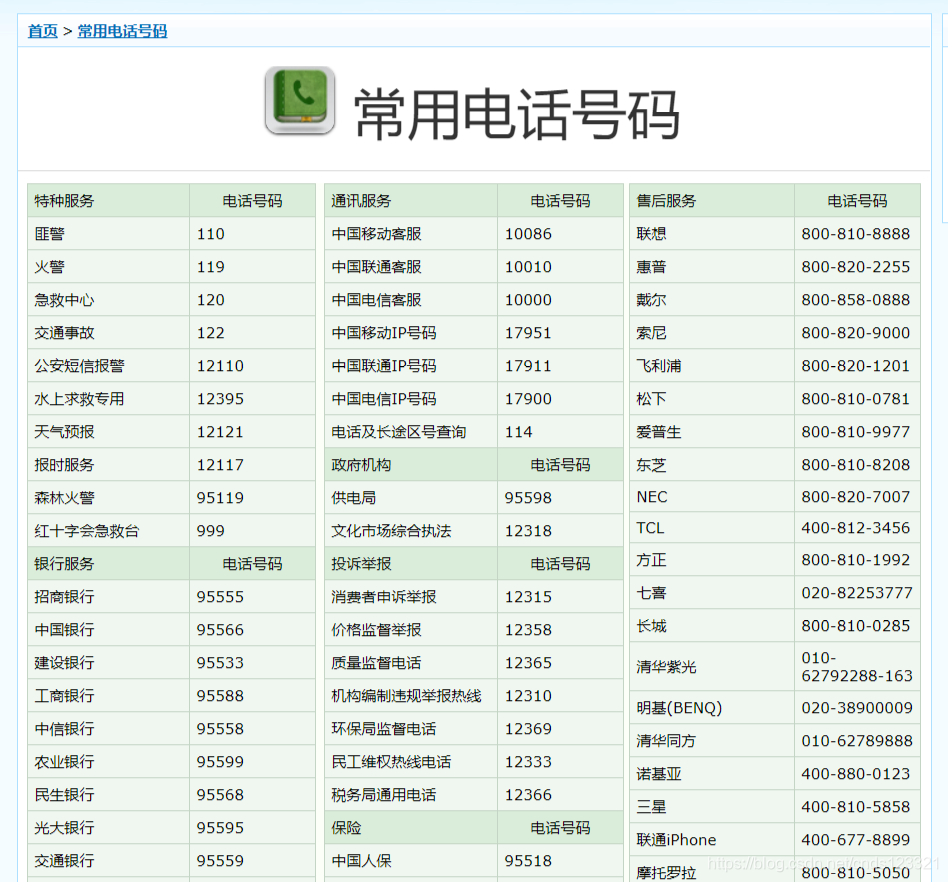
按F12分析网页
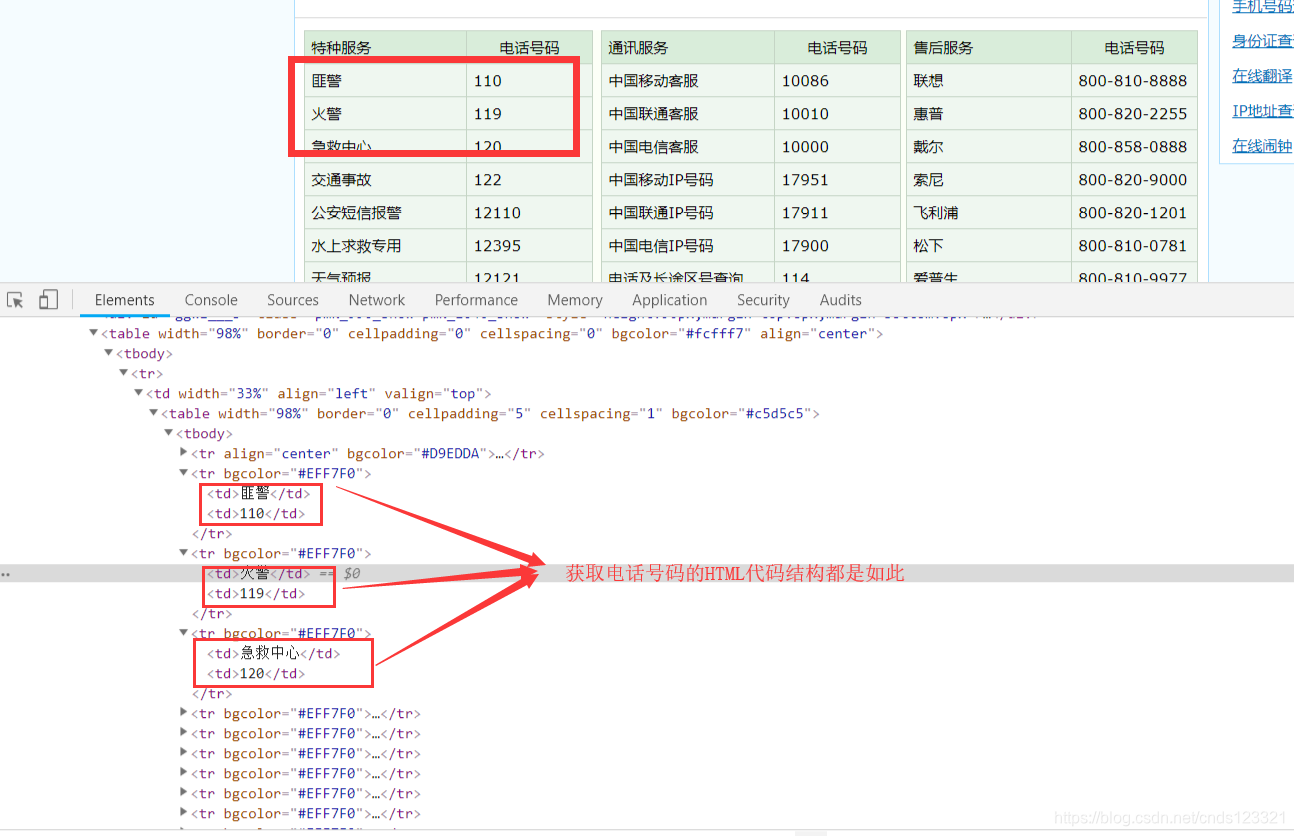
网页的URL是:https://changyongdianhuahaoma.51240.com/
2. 爬虫代码
import re
import requests
# 爬取常用电话号码
# https://changyongdianhuahaoma.51240.com/
# 使用HTTP请求: http://changyongdianhuahaoma.51240.com/
# 请求的URL
url = "http://changyongdianhuahaoma.51240.com/"
# 请求头
header = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.81 Safari/537.36"
}
# 发送请求,获取响应
response = requests.get(url, headers=header).text
# 正则表达式:提取电话信息,其中[\s\s]*?是处理之间的空格和换行部分
pat1 = r'<tr bgcolor="#EFF7F0">[\s\s]*?<td>(.*?)</td>[\s\s]*?<td>(.*?)</td>[\s\s]*?</tr>'
# 使用compile函数处理正则表达式
pattern1 = re.compile(pat1)
# 根据正则表达式提取数据
data = pattern1.findall(response)
for d in data: # 循环遍历
print(d[0], ":", d[1]) # 打印
甚至可以修改下代码将这些号码写入到本地。
import re
import requests
# 爬取常用电话号码
# https://changyongdianhuahaoma.51240.com/
# 使用HTTP请求: http://changyongdianhuahaoma.51240.com/
# 请求的URL
url = "http://changyongdianhuahaoma.51240.com/"
# 请求头
header = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.81 Safari/537.36"
}
# 发送请求,获取响应
response = requests.get(url, headers=header).text
# 正则表达式:提取电话信息,其中[\s\s]*?是处理之间的空格和换行部分
pat1 = r'<tr bgcolor="#EFF7F0">[\s\s]*?<td>(.*?)</td>[\s\s]*?<td>(.*?)</td>[\s\s]*?</tr>'
# 使用compile函数处理正则表达式
pattern1 = re.compile(pat1)
# 根据正则表达式提取数据
data = pattern1.findall(response)
for d in data: # 循环遍历
print(d[0], ":", d[1]) # 打印
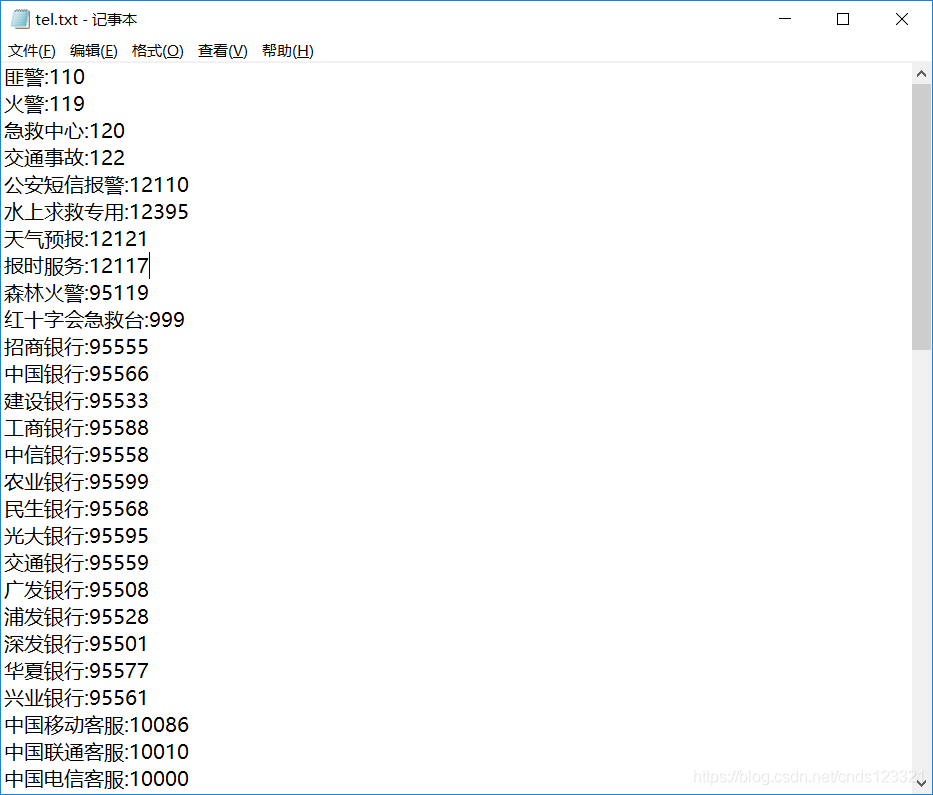
with open("tel.txt", "a") as file_object:
file_object.write(d[0] + ":" + str(d[1]) + "\n") # 保存到本地
查看tel.txt文件

















 7929
7929

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









