






目录
一.图像分割概述
1.什么是图像分割?
图像分割(Semantic Segmentation)是计算机视觉中非常重要的任务,是图像理解的基石性技术。
它的目标是为图像中的每个像素点分类,即像素级别的分类任务。
如下图所示,将原始图像分割成三类(摩托车,人,背景),输入左图,输出右图,由此可见完成图像分割的任务需要一种生成模型(下采样+上采样)的神经网络:

2.图像分割的应用场景
图像分割技术在各领域都有广泛的应用,例如在
无人驾驶(具体为街景识别与理解)
医学影像分割(例如CT/MR磁共振脑图像分割)
GIS地理识别的图像处理系统
无人机应用(着陆点判断)
穿戴式设备应用等方面。
下图为图像分割在OCT眼底视网膜图像分层识别中的应用:

3.图像分割分类
目前的分割任务主要有三种: 普通分割,语义分割和实例分割。
- 普通分割:将分属不同物体的像素区域分开。
- 语义分割:在普通分割的基础上,分类出每一块区域的语义(即这块区域是什么物体),即将画面中的所有物体都指出他们各自的类别。
- 实例分割: 在语义分割的基础上,给每个物体编号。即不但要进行像素级别的分类,还需在具体的类别基础上区别开不同的实例。
比如说图像有多个人甲、乙、丙,那边他们的语义分割结果都是人,而实例分割结果却是不同的对象
如下图所示,分别为目标检测,语义分割,实例分割:

4.小结
简而言之,我们的目标是给定一幅RGB彩色图像(HW3)或一幅灰度图像(HW1),经过深度学习算法处理输出一个分割图谱,其中包括每个像素的类别标注(HW1),即输入输出都是图像,而且是同样大小的图像(带有各个像素类别标签),具体如下图所示:

它的实现方式:首先明确分类数,然后为每个类别创建一个输出通道channel(像素上的 one-hot 编码)
其中单一通道代表了某一特定类别所存在的区域,称之为mask掩膜
下图所示对图片分为五类:Person(人)、Purse(包)、Plants/Grass(植物/草)、Sidewalk(人行道)、Building/Structures(建筑物),所以输出五个通道(h,w,5),每个通道对像素点进行单类别的分类(1,0)

最后通过求argmax的方式被整合到一张分割图中,如下图所示:

本章介绍了图像分割的基础知识和实现思路,下一章将讲解Unet网络的算法原理和训练过程*
二.UNET网络模型
1.图像分割通用的网络构造方法
上一篇我们介绍了图像分割需要输入输出都是图像,是将逐渐变小的特征图给还原到输入图像的大小的过程,所以网络模型的一种通用做法就是采用编码和解码的网络结构
下采样+上采样
① 多层卷积和池化的过程可以视作是图像编码的过程,也是下采样的过程,解码可以理解为编码的逆运算,对编码的输出特征图进行不断的上采样逐渐得到一个与原始输入大小一致的分割图(输出)
②图像下采样的常用方法:

思考:使用池化的下采样,不会记录临近点的位置关系,对位置信息不敏感,还会产生位置偏移。我们又知道图像分割任务是像素级别的分类任务,所以采用较大步长的卷积下采样比池化更适合
③图像上采样的常用方法:

注:这里的像素融合,类似于混洗,将各个通道上的信息平铺开来,得到输出H,W变大,channel变小的特征图
多尺度特征融合
concat,add---------跳级(skip)结构
获得像素级别的分割图,对每个像素点进行类别判别
哑铃瓶颈结构
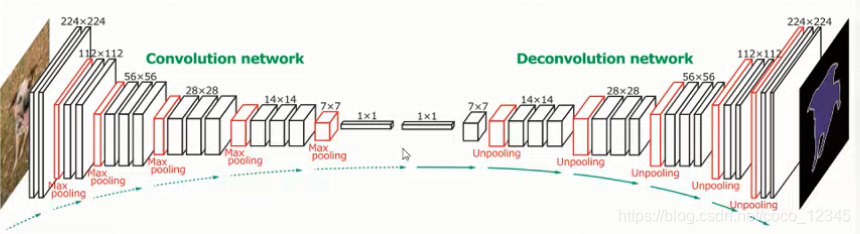
2. FCN
在图像分割领域,基于深度学习的语义分割算法开山之作是FCN(Fully Convolutional Networks for Semantic Segmentation)
FCN遵循编码解码的网络结构模式,使用 AlexNet 作为网络的编码器,采用转置卷积对编码器最后一个卷积层输出的特征图进行上采样直到特征图恢复到输入图像的分辨率,因而可以实现像素级别的图像分割。FCN的一个好处是可输入任意尺寸的图像进行语义分割。

FCN的核心思想
①不含全连接层(fc)的全卷积(fully conv)网络。可适应任意尺寸输入。
②增大数据尺寸的反卷积(deconv)层。能够输出精细的结果。
③结合不同深度层结果的跳级(skip)结构。同时确保鲁棒性和精确性。在FCN中,Skip connection的联合是通过对应像素的求和(add)
FCN的网络结构

3.UNET
UNET概述
UNet是遵循FCN的原理,并进行了相应的改进,使其适应小样本的简单分割问题。
UNet网络结构,最主要的两个特点是:U型网络结构和Skip Connection跳层连接。如下图所示:

UNet是一个对称的网络结构,左侧为下采样,右侧为上采样。按照FCN的思想,左边可以看作编码,右边可以看作解码过程
网络构造细节
1.Skip Connection跳跃连接是在上采样的过程中,融合下采样过程中的feature map,与FCN不同的是,UNET融合方式用的称Concat,通道上的叠加融合。注意左右两边特征大小(H,W)不一样,Unet采用的是将左边大的feature map裁剪后再进行Concat。
2.:上采样方式前面介绍过有像素插值,转置卷积,像素融合,这里用到的是Upsample和ConvTranspose2d,也就是双线性插值和转置卷积(反卷积)。
3.由网络构造我们可以看到,网络输入和输出的形状大小是不一样的,这是针对医学图像的分割领域的Overlap-tile策略

卷积运算对边缘区域的特征提取不如中间区域的深,黄色预测区域需要脸色区域的图像数据做输入,在大图像分割时,需将图像做有重叠的分割就可以做到无缝切割平铺
4.UNET++
概述
U-Net原论文给出的结构是原图经过四次降采样,四次上采样,得到分割结果
对于特征提取阶段,浅层结构可以抓取图像的一些简单的特征,比如边界,颜色,而深层结构因为感受野大了,而且经过的卷积操作多了,能抓取到图像的一些说不清道不明的抽象特征,总之,浅有浅的侧重,深有深的优势。
既然浅层特征和深层特征都很重要,U-Net为什么只在4层以后才返回去,也就是只去抓深层特征?由此提出了UNET++
这是知乎上得图,可以很形象得解释网络的改进思路:

上面这张图是四种深度的网络,L1最浅只有1次下采样,L4最深,有四次下采样

这张图是把1~4层的U-Net全给连一起了,让网络自己去学习不同深度的特征,而且它共享了一个特征提取器,也就是不需要训练一堆U-Net,而是只训练一个encoder,它的不同层次的特征由不同的decoder路径来还原
这个网络结构是不能被训练的,原因在于,不会由任何梯度会经过这个红色区域,因为它和算loss function的地方是在反向传播时是断开的,如下入所示:

基于以上思路,结合UNET的长连接和短连接的特性,由此设计出了UNET++网络结构,如下图所示:

UNET++这样的网络设计优势是可以抓取不同层次的特征,将它们通过特征叠加的方式整合,不同层次的特征,或者说不同大小的感受野,对于大小不一的目标对象的敏感度是不同的,比如,感受野大的特征,可以很容易的识别出大物体的,但是在实际分割中,大物体边缘信息和小物体本身是很容易被深层网络一次次的降采样和一次次升采样给弄丢的,这个时候就可能需要感受野小的特征来帮助。
深监督和剪枝
回看上面的UNET++网络结构来看,如果只用一个loss----X(0 ,4)的话,这个结构在反向传播的时候中间部分会收不到过来的梯度,解决方案就是深监督,也就是deep supervision:
具体的实现操作就是在网络的四个输出后面加一个1x1的卷积核,相当于去监督每个level,或者每个分支的U-Net的输出。

我们已经知道在UNET++中每个子网络的输出都其实已经是图像的分割结果了,如果小的子网络的输出结果已经足够好了,我们可以随意的剪掉那些多余的部分了。
在测试的阶段,由于输入的图像只会前向传播,扔掉这部分对前面的输出完全没有影响的,而在训练阶段,因为既有前向,又有反向传播,被剪掉的部分是会帮助其他部分做权重更新的。
所以思路就是在训练时通过深监督训练好模型,而在测试时选择合适的效果好的子网络,剩下的那些部分就可以剪掉了。
总结:UNet++的第一个优势就是精度的提升,这个应该它整合了不同层次的特征所带来的,第二个是灵活的网络结构配合深监督,让参数量巨大的深度网络在可接受的精度范围内大幅度的缩减参数量。
三.图像分割评估
1.Dice系数/DiceLoss
dice coefficient 源于二分类,本质上是衡量两个样本的重叠部分。该指标范围从0到1,其中“1”表示完整的重叠。 其计算公式为:

其中 表示集合A、B 之间的共同元素, 表示 A 中的元素的个数,B也用相似的表示方法。
为了计算预测的分割图的 dice coefficient,将 近似为预测图和label之间的点乘,并将结果函数中的元素相加。

因为Dice =1 时表示完整的重叠,所以DiceLoss可以定义为: DiceLoss =1-Dice
DiceLoss比较适合样本极度不均的情况(样本大部分是0,极少部分是1。反之亦然),一般情况下,使用DiceLoss会对反向传播造成不对影响,会使训练极度不稳定。
2.IOULoss

IOULoss可以定义为: IOULoss =1-J(A,B)
3.BCELOSS

BCELoss对正负样本的关注度是一样的,所以对较适合样本极度均匀的情况。
3.WBELOSS
带权重的交叉熵
4.Focal loss
二分类问题的标准loss是0-1交叉熵损失,前面讲:过当负样本数量太大,占总的loss的大部分,而且多是容易分类的,因此使得模型的优化方向并不是我们所希望的那样。

focal loss的两个性质算是核心,其实就是用一个合适的函数去度量难分类和易分类样本对总的损失的贡献。
5.常用Loss组合
BCELoss+DiceLoss
Diceloss+Focalloss
四.Pytorch实现UNET算法
1.简介
小项目做的是医学图像分割。训练数据只有30张,分辨率为512x512,这些图片是果蝇的电镜图。
下图展示的分别是原图像和标签图像


2.数据加载
数据分为训练集和测试集,各30张,训练集有标签,测试集没有标签
处理很简单,只是将图片读取,并处理成灰度图(二分类)。同时归一化。
3.模型选择
对网络进行微调,完全按照论文的结构,模型输出的尺寸会稍微小于图片输入的尺寸,如果使用论文的网络结构需要在结果输出后,做一个 resize 操作。为了省去这一步,微调网络的输出尺寸正好等于图片的输入尺寸都是512*512。
4.损失函数
因为是单通道图片,标签图片是0或者1,本质上是二分类问题,所以损失函数使用的是BCEWithLogitsLoss (SIgmoid+BCEloss)
5.效果

自己的一点疑惑
UNET论文中的输出 output 是338* 338*2

这里输出通道是2,可以理解为是二分类问题,输出的是2个类别的掩膜。那么原图像的标签label是不是也是应该有2个呢?
如果是多类别(10分类),那么输出是338338 10,那么标签怎么给定呢?
老师给的那种代码展示的标签为什么没有分类别?(直接是3通道应该很难训练的)















 436
436











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









