






在计算机科学和算法设计中,就地算法(In-place Algorithm)是一个至关重要的概念。就地算法是一种在操作过程中只需要常数级别的额外空间(或不需要额外辅助空间)的算法。换句话说,除了输入数据本身外,算法只使用少量的额外存储空间。这意味着,无论输入数据的大小如何,额外的空间需求都不会随之显著增加。
**定义**:就地算法是指那些在执行过程中只需要 \(O(1)\) 额外空间的算法。
```python
def bubble_sort(arr):
n = len(arr)
for i in range(n):
for j in range(0, n-i-1):
if arr[j] > arr[j+1]:
arr[j], arr[j+1] = arr[j+1], arr[j]
```
### 综述
整个函数的工作流程如下:
1. 计算数组的长度 `n`。
2. 进行 `n` 轮外层循环。在每一轮中:
- 进行 `n-i-1` 次内层循环比较相邻元素。
- 如果当前元素比下一个元素大,则交换它们的位置。
3. 重复上述过程,直到所有元素都按升序排列。
#### 举个例子
为了更好地理解,我们来举个例子。假设有一堆玩具,把这些玩具按大小排序。你可能会先找一个空的箱子,把大的玩具放在一边,小的玩具放在另一边,最后把它们重新放回原来的地方。
但是,如果要求:“你不能用空的箱子,只能在原地排序。”这时候,你就需要一个就地算法了。你需要在原地把玩具按大小排序,不借用额外的空间。
#### 怎么做?
我们可以用一种叫做“冒泡排序”的方法来做这个事情。冒泡排序是一个简单的就地算法,听起来像是气泡在水中上升的样子。下面是它的步骤:
1. **第一步**:从第一个玩具开始,比较它和第二个玩具的大小。如果第一个玩具比第二个大,就交换它们的位置。
2. **第二步**:然后比较第二个和第三个玩具,重复同样的步骤。
3. **第三步**:一直这样比较和交换,直到最后一个玩具。
这样做一遍之后,最大的玩具就会“冒泡”到最后一个位置。然后你再重复这个过程,但这次只需要比较和交换前面倒数第二个位置的玩具。一直这样做,直到所有的玩具都按大小排序好。
这种方法就叫做“就地算法”,因为我们是在原地完成排序的,没有用额外的空间或者新的箱子。
#### 就地算法有什么用?
现在你可能会问:“为什么就地算法这么重要呢?”有几个原因:
1. **节省空间**:不需要额外的箱子或者空间来放东西,这样可以节省很多地方。比如在电脑里,如果我们要处理非常多的数据,节省空间就非常重要。
2. **高效**:因为不需要额外的空间,所以就地算法通常也会更快。就像你做作业的时候,如果桌子上很整洁,你就能更快地找到需要的东西。
3. **简单易行**:有时候,简单的方法往往是最有效的。就地算法通常比较简单,不需要额外的工具或者复杂的步骤。
####举例说明:
### 1. 冒泡排序(Bubble Sort)
**概念**:
- 冒泡排序通过重复地交换相邻的元素来排序。
- 每一轮操作之后,最大的元素会“冒泡”到列表的最后面。
**时间复杂度**:
- 最佳情况:\(O(n)\)(当数组已经有序)
- 平均情况:\(O(n^2)\)
- 最坏情况:\(O(n^2)\)
**空间复杂度**:
- \(O(1)\)
**应用**:
- 适用于小规模数据的排序。
**特点**:
- 实现简单,但对于大规模数据效率较低。
### 什么是冒泡排序?
冒泡排序是一种我们用来把一堆数据按顺序排列的方法。想象一下,你有一排从小到大的数字,它们像小朋友一样站成一排,但它们站的位置可能是乱的。我们的目标是让这些数字从小到大或者从大到小排好队。
### 冒泡排序的工作原理
冒泡排序的工作方式很简单,像这样:
1. **比较与交换**:我们从第一个数字开始,看它和旁边的数字谁大。如果前面的数字比后面的数字大,我们就让它们交换位置。就像两个小朋友在排队玩游戏,如果站错了位置,他们就换个地方。
2. **重复这个过程**:我们继续比较第二个数字和第三个数字,第三个和第四个,依此类推,一直到最后一个数字。这一轮结束后,最大的数字就会被“冒”到最后面,就像泡泡上升到水面一样。
3. **再来一遍**:然后我们回到开头,重复上面的步骤。这次我们不用管最后一个数字,因为它已经在正确的位置上了。我们只需要比较和交换前面的数字。
4. **继续重复**:我们一轮又一轮地重复这个过程,每一轮都会有一个最大的数字冒到正确的位置。最终,所有的数字都会按照大小顺序排好队。
### 具体例子
让我们用一个简单的例子来看看冒泡排序是怎么工作的吧!
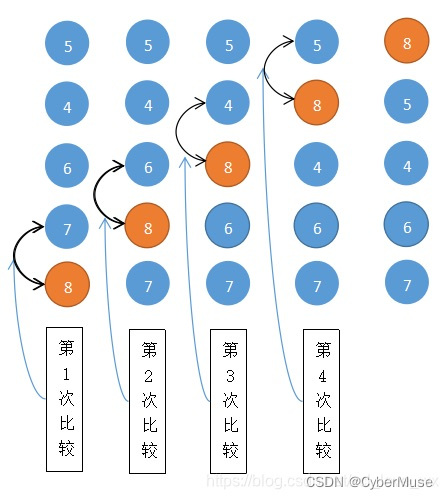
假设我们有一组数字:\[5, 3, 8, 4, 2\]
- **第一轮**:
- 5 和 3 比较,5 比 3 大,所以交换,变成:\[3, 5, 8, 4, 2\]
- 5 和 8 比较,5 比 8 小,不交换,还是:\[3, 5, 8, 4, 2\]
- 8 和 4 比较,8 比 4 大,交换,变成:\[3, 5, 4, 8, 2\]
- 8 和 2 比较,8 比 2 大,交换,变成:\[3, 5, 4, 2, 8\]
第一轮结束,8 像泡泡一样冒到了最后面。
- **第二轮**:
- 3 和 5 比较,3 比 5 小,不交换,还是:\[3, 5, 4, 2, 8\]
- 5 和 4 比较,5 比 4 大,交换,变成:\[3, 4, 5, 2, 8\]
- 5 和 2 比较,5 比 2 大,交换,变成:\[3, 4, 2, 5, 8\]
第二轮结束,5 冒到了倒数第二个位置。
- **第三轮**:
- 3 和 4 比较,3 比 4 小,不交换,还是:\[3, 4, 2, 5, 8\]
- 4 和 2 比较,4 比 2 大,交换,变成:\[3, 2, 4, 5, 8\]
第三轮结束,4 冒到了倒数第三个位置。
- **第四轮**:
- 3 和 2 比较,3 比 2 大,交换,变成:\[2, 3, 4, 5, 8\]
现在所有数字都排好了!
### 冒泡排序的时间复杂度
冒泡排序的时间复杂度主要取决于数据的初始状态。让我们分三种情况来讨论:最好的情况、一般情况和最糟糕的情况。
#### 最好的情况:数据已经是有序的
在这种情况下,冒泡排序只需要进行一次完整的遍历就能确认所有元素已经有序。假设我们有一个数组 \[1, 2, 3, 4, 5\]:
1. **第一轮遍历**:
- 比较 1 和 2,不需要交换。
- 比较 2 和 3,不需要交换。
- 比较 3 和 4,不需要交换。
- 比较 4 和 5,不需要交换。
因为没有发生任何交换,算法可以提前终止。我们只进行了 \(n-1\) 次比较,所以时间复杂度是 \(O(n)\)。
#### 最糟糕的情况:数据是逆序的
在这种情况下,冒泡排序需要进行最多的比较和交换。假设我们有一个数组 \[5, 4, 3, 2, 1\]:
1. **第一轮遍历**:
- 比较 5 和 4,交换,得到 \[4, 5, 3, 2, 1\]。
- 比较 5 和 3,交换,得到 \[4, 3, 5, 2, 1\]。
- 比较 5 和 2,交换,得到 \[4, 3, 2, 5, 1\]。
- 比较 5 和 1,交换,得到 \[4, 3, 2, 1, 5\]。
2. **第二轮遍历**:
- 比较 4 和 3,交换,得到 \[3, 4, 2, 1, 5\]。
- 比较 4 和 2,交换,得到 \[3, 2, 4, 1, 5\]。
- 比较 4 和 1,交换,得到 \[3, 2, 1, 4, 5\]。
3. **第三轮遍历**:
- 比较 3 和 2,交换,得到 \[2, 3, 1, 4, 5\]。
- 比较 3 和 1,交换,得到 \[2, 1, 3, 4, 5\]。
4. **第四轮遍历**:
- 比较 2 和 1,交换,得到 \[1, 2, 3, 4, 5\]。
在每一轮遍历中,我们都需要进行最多的比较和交换,因此时间复杂度是 \(O(n^2)\)。
### 总结
- **最好的情况**:\(O(n)\),数据已经有序,只需一轮遍历。
- **一般情况**:\(O(n^2)\),数据是随机顺序,需要多轮遍历。
- **最糟糕的情况**:\(O(n^2)\),数据是逆序,需要最多的比较和交换。
### 建议
1. **优化算法**:可以在冒泡排序中加入一个标志位(flag),如果在一轮遍历中没有发生任何交换,说明数据已经有序,可以提前终止,进一步优化时间复杂度。
2. **选择合适的排序算法**:对于大规模数据,考虑使用更高效的排序算法,如快速排序或归并排序,这些算法在平均情况下的时间复杂度是 \(O(n \log n)\)。
### 冒泡排序的优缺点
**优点**:
- **简单易懂**:冒泡排序的原理和步骤都很简单,适合初学者学习和理解。
- **实现容易**:代码实现也不复杂,只需要几行代码就可以完成。
**缺点**:
- **效率较低**:当数据量很大的时候,冒泡排序会花费比较多的时间来完成排序。对于上百个、上千个数字,它就显得有点慢了。
### 2. 插入排序(Insertion Sort)
**概念**:
- 插入排序通过逐一取出未排序的元素,并将其插入到已排序部分的正确位置。
**时间复杂度**:
- 最佳情况:\(O(n)\)(当数组已经有序)
- 平均情况:\(O(n^2)\)
- 最坏情况:\(O(n^2)\)
**空间复杂度**:
- \(O(1)\)
**应用**:
- 适用于少量数据的排序,特别是在数据基本有序的情况下效果较好。
**特点**:
- 简单直观,适合初学者理解。
### 3. 选择排序(Selection Sort)
**概念**:
- 选择排序每次从未排序部分找到最小的元素,将其放到已排序部分的末尾。
**时间复杂度**:
- 最佳情况:\(O(n^2)\)
- 平均情况:\(O(n^2)\)
- 最坏情况:\(O(n^2)\)
**空间复杂度**:
- \(O(1)\)
**应用**:
- 适用于少量数据的排序。
**特点**:
- 实现简单,但效率不高。
### 4. 快速排序(Quick Sort)
**概念**:
- 快速排序选择一个“枢轴”元素,将数组划分为两部分,左边部分比枢轴小,右边部分比枢轴大,然后递归地对两部分进行排序。
**时间复杂度**:
- 最佳情况:\(O(n \log n)\)
- 平均情况:\(O(n \log n)\)
- 最坏情况:\(O(n^2)\)
**空间复杂度**:
- \(O(\log n)\)(递归调用栈)
**应用**:
- 适用于大规模数据的排序。
**特点**:
- 平均时间复杂度为 \(O(n \log n)\),但在最坏情况下时间复杂度为 \(O(n^2)\)。
### 5. 堆排序(Heap Sort)
**概念**:
- 堆排序利用堆这种数据结构来排序,首先构建一个最大堆,然后逐一取出最大元素放到数组的末尾。
**时间复杂度**:
- 最佳情况:\(O(n \log n)\)
- 平均情况:\(O(n \log n)\)
- 最坏情况:\(O(n \log n)\)
**空间复杂度**:
- \(O(1)\)
**应用**:
- 适用于需要稳定性能的大规模数据排序。
**特点**:
- 时间复杂度为 \(O(n \log n)\),空间复杂度为 \(O(1)\)。
### 6. 原地反转(In-Place Reversal)
**概念**:
- 这个算法用于将数组或链表原地反转,即不借助辅助空间把元素顺序颠倒。
**时间复杂度**:
- \(O(n)\)
**空间复杂度**:
- \(O(1)\)
**应用**:
- 适用于需要反转数组或链表的情况。
**特点**:
- 实现简单,空间复杂度为 \(O(1)\)。
### 7. 荷兰国旗问题(Dutch National Flag Problem)
**概念**:
- 这个算法用于将包含三种不同元素的数组分成三部分,每部分的元素相同。
**时间复杂度**:
- \(O(n)\)
**空间复杂度**:
- \(O(1)\)
**应用**:
- 适用于需要快速分类的场景,比如排序红、白、蓝三色球。
**特点**:
- 高效,时间复杂度为 \(O(n)\),空间复杂度为 \(O(1)\)。
### 8. 原地移除重复元素(In-Place Remove Duplicates)
**概念**:
- 这个算法在有序数组中移除重复元素,使每个元素只出现一次,并返回新数组的长度。
**时间复杂度**:
- \(O(n)\)
**空间复杂度**:
- \(O(1)\)
**应用**:
- 适用于需要在原地去重的情况。
**特点**:
- 高效,时间复杂度为 \(O(n)\),空间复杂度为 \(O(1)\)。















 986
986

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









