






一、编译器在实现过程调用时通常会涉及以下几个步骤:
1. **压栈参数**:
- 函数调用时,调用者(caller)将参数压入堆栈。参数的顺序和压栈方式可能根据调用约定(calling convention)而有所不同。
2. **保存上下文**:
- 调用者保存当前的执行上下文(如寄存器状态),以便函数返回后能够恢复。
3. **跳转到函数地址**:
- 调用者通过调用指令(如x86架构中的`CALL`指令)跳转到被调用函数的地址,并将返回地址压入堆栈。
4. **执行函数**:
- 被调用函数开始执行。它首先会将旧的帧指针保存到堆栈,并设置新的帧指针。
- 在函数体内,局部变量通常会分配在堆栈上。
5. **返回调用者**:
- 函数执行完毕后,恢复帧指针和其他寄存器状态,将返回值放入特定的寄存器(根据调用约定)。
- 使用返回指令(如x86架构中的`RET`指令)从堆栈中弹出返回地址,跳转回调用者。
### 示例代码
```c
#include <stdio.h>
void function(int a, int b) {
int result = a + b;
printf("Result: %d\n", result);
}
int main() {
function(5, 10);
return 0;
}
```
### 过程调用步骤解析
1. **压栈参数**:
- `5` 和 `10` 被压入堆栈。
2. **保存上下文**:
- 调用者保存当前的寄存器状态。
3. **跳转到函数地址**:
- 跳转到 `function` 函数的地址,并将返回地址压入堆栈。
4. **执行函数**:
- `function` 函数执行,将参数 `5` 和 `10` 从堆栈中弹出,计算结果并打印。
5. **返回调用者**:
- `function` 执行完毕,返回到 `main` 函数,恢复上下文,继续执行。
通过这些步骤,编译器和CPU协同工作,实现了函数的调用和返回,确保程序能正确执行。
其中堆栈的使用在这些步骤中是关键。堆栈是一块连续的内存区域,用于存储函数调用的参数、返回地址和局部变量。当一个函数被调用时,参数和返回地址会被压入堆栈。当函数返回时,这些信息会被弹出堆栈。
二、缓冲区溢出发生在程序试图向一个固定大小的缓冲区写入超过其容量的数据时。
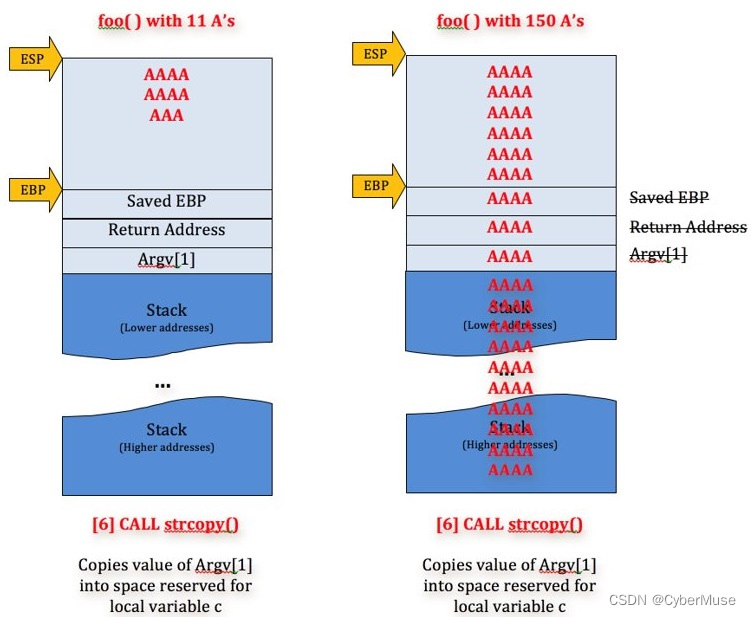
这样会导致溢出部分的数据覆盖堆栈中的其他数据,如返回地址,从而引发安全漏洞。看这个例子:
```c
void vulnerable_function(char *input) {
char buffer[10];
strcpy(buffer, input); // 如果input超过10个字符,就会发生缓冲区溢出
}
让我们逐行解释一下这段代码和这个函数的工作原理:
```c
void vulnerable_function(char *input) {
```
- 定义一个名为 `vulnerable_function` 的函数,它接受一个字符指针 `input` 作为参数。这个函数没有返回值(`void`)。
```c
char buffer[10];
```
- 在函数内部声明一个字符数组 `buffer`,长度为10个字符。这意味着 `buffer` 可以存储最多9个字符加上一个终止符 '\0'。
```c
strcpy(buffer, input); // 如果input超过10个字符,就会发生缓冲区溢出
```
- 使用标准库函数 `strcpy` 将 `input` 指向的字符串复制到 `buffer` 中。`strcpy` 不会检查目标缓冲区的大小,所以如果 `input` 指向的字符串长度超过10个字符,就会发生缓冲区溢出(buffer overflow)。
### 缓冲区溢出的风险
- 如果 `input` 的长度超过 `buffer` 的容量(即超过10个字符),`strcpy` 会继续复制数据,导致超出 `buffer` 边界的内容被覆盖。这可能会覆盖函数调用的返回地址、其他局部变量以及堆栈上的其他数据,从而引发未定义行为,严重时可能导致程序崩溃或被恶意利用。
三、我们可以清晰地看到这个函数的工作原理及其潜在的安全风险。为了避免缓冲区溢出,可以使用更安全的字符串复制函数,如 `strncpy`,并合理设置缓冲区大小。
`strncpy` 是 C 标准库中的一个函数,用于将一个字符串的指定数量的字符复制到另一个字符串中。与 `strcpy` 不同,`strncpy` 允许你指定要复制的最大字符数,从而提供了一定的安全性,防止缓冲区溢出。
### 函数原型
```c
char *strncpy(char *dest, const char *src, size_t n);
```
### 参数
- **`dest`**: 目标字符串的指针,表示要复制到的缓冲区。
- **`src`**: 源字符串的指针,表示要复制的字符串。
- **`n`**: 要复制的最大字符数。
### 返回值
- 返回目标字符串 `dest` 的指针。
### 行为
- `strncpy` 从源字符串 `src` 复制最多 `n` 个字符到目标字符串 `dest` 中。
- 如果 `src` 的长度小于 `n`,则 `dest` 中剩余的部分会被填充为 `\0`。
- 如果 `src` 的长度等于或大于 `n`,则 `dest` 不会以 `\0` 终止。
### 示例代码
让我们用一个示例来展示 `strncpy` 的使用:
```c
#include <stdio.h>
#include <string.h>
void safe_function(char *input) {
char buffer[10];
strncpy(buffer, input, sizeof(buffer) - 1);
buffer[sizeof(buffer) - 1] = '\0'; // 确保字符串以 '\0' 结尾
printf("Buffer content: %s\n", buffer);
}
int main() {
char long_input[] = "This is a very long input string";
safe_function(long_input);
return 0;
}
```
### 逐行解释
1. **`#include <stdio.h>`** 和 **`#include <string.h>`**:
- 包含标准输入输出库和字符串操作库的头文件。
2. **`void safe_function(char *input) {`**:
- 定义一个名为 `safe_function` 的函数,接受一个字符指针 `input` 作为参数。
3. **`char buffer[10];`**:
- 声明一个字符数组 `buffer`,长度为10个字符。
4. **`strncpy(buffer, input, sizeof(buffer) - 1);`**:
- 使用 `strncpy` 从 `input` 中复制最多 `sizeof(buffer) - 1`(即9个)字符到 `buffer` 中。这样确保不会发生溢出。
5. **`buffer[sizeof(buffer) - 1] = '\0';`**:
- 手动将 `buffer` 的最后一个字符设置为 `\0`,确保字符串以 `\0` 终止。
通过使用 `strncpy`,我们限制了从 `input` 复制到 `buffer` 的字符数量,避免了缓冲区溢出,并且确保了 `buffer` 以 `\0` 终止,从而保证了字符串操作的安全性。
四、接下来,我们来看第二个例子,涉及过程调用和堆栈保护:
```c
void safe_function_with_stack_protector(char *input) {
char buffer[10];
__builtin___strncpy_chk(buffer, input, sizeof(buffer) - 1, __builtin_object_size(buffer, 0));
buffer[sizeof(buffer) - 1] = '\0'; // 确保字符串以'\0'结尾
}
```
编译器的`-fstack-protector`选项会自动插入堆栈保护代码,检测堆栈溢出。
这些内建函数是编译器提供的安全检查机制,它们可以自动检测并防止缓冲区溢出。使用这样的选项可以大大提高程序的安全性。
`__builtin___strncpy_chk` 是 GCC 提供的一种内置函数,用于增强字符串操作函数的安全性。它在运行时检查目标缓冲区的大小,以防止缓冲区溢出。这种方法结合了编译器的内置检查机制和手动字符串终止符的设置,以确保字符串复制操作的安全性。
**函数原型**:
```c
char *__builtin___strncpy_chk(char *dest, const char *src, size_t len, size_t dest_size);
```
#### 1. `strncpy`
- **函数名**:表示这个函数的名称是 `strncpy`。
- **解释**:这是标准库函数,用于从源字符串复制指定数量的字符到目标字符串。
#### 2.`chk`
表示 "check",在函数名称中表示这个函数提供了额外的安全检查功能,以增强代码的安全性,防止常见的编程错误如缓冲区溢出。
#### 3. `char *dest`
- **参数类型和名称**:这个参数是一个指向字符类型的指针,名为 `dest`。
- **解释**:`dest` 是目标字符串的指针,表示要复制到的缓冲区。
#### 4. `const char *src`
- **参数类型和名称**:这个参数是一个指向常量字符类型的指针,名为 `src`。
- **解释**:`src` 是源字符串的指针,表示要复制的字符串。`const` 关键字表示 `src` 指向的内容不能被修改。
#### 5. `size_t n`
- **参数类型和名称**:这个参数是 `size_t` 类型的变量,名为 `n`。
- **解释**:`n` 表示要复制的最大字符数。`size_t` 是一种无符号整数类型,通常用于表示大小和计数。
### 整体解释
- **函数功能**:`strncpy` 函数从源字符串 `src` 复制最多 `n` 个字符到目标字符串 `dest` 中。如果 `src` 的长度小于 `n`,则 `dest` 中剩余的部分会被填充为 `\0`。如果 `src` 的长度等于或大于 `n`,则 `dest` 不会以 `\0` 终止。
- **返回值**:该函数返回目标字符串 `dest` 的指针。
#### 3. 如何确保安全
**步骤1**:使用 `__builtin___strncpy_chk` 进行复制
- `__builtin___strncpy_chk` 会在运行时检查 `dest` 缓冲区的大小。
- 如果 `len` 超过 `dest_size`,则会触发运行时错误,防止缓冲区溢出。
**步骤2**:手动设置字符串终止符
- 即使使用了 `__builtin___strncpy_chk`,手动设置终止符 `buffer[sizeof(buffer) - 1] = '\0';` 仍然是必要的。
- 这是因为 `strncpy` 不会自动在结果字符串末尾添加 `\0`,如果源字符串长度大于或等于 `len`。
### 逐行解释
1. **`void safe_function_with_stack_protector(char *input) {`**:
- 定义一个名为 `safe_function_with_stack_protector` 的函数,接受一个字符指针 `input` 作为参数。
2. **`char buffer[10];`**:
- 声明一个字符数组 `buffer`,长度为10个字符。
3. **`__builtin___strncpy_chk(buffer, input, sizeof(buffer) - 1, __builtin_object_size(buffer, 0));`**:
- 使用 GCC 提供的内置函数 `__builtin___strncpy_chk` 从 `input` 中复制最多 `sizeof(buffer) - 1`(即9个)字符到 `buffer` 中。
- `__builtin_object_size(buffer, 0)` 返回 `buffer` 的大小,这个值用于在运行时进行边界检查,确保不会发生缓冲区溢出。
4. **`buffer[sizeof(buffer) - 1] = '\0';`**:
- 手动将 `buffer` 的最后一个字符设置为 `\0`,确保字符串以 `\0` 结尾。
### 内置函数 `__builtin___strncpy_chk` 的作用
- **`__builtin___strncpy_chk`** 是一个内置函数,用于在运行时检查目标缓冲区的大小,从而防止溢出。这是编译器在编译时插入的安全检查代码,旨在增强代码的安全性。
- 它的参数与 `strncpy` 类似,但多了一个参数 `__builtin_object_size(buffer, 0)`,用于检查目标缓冲区的大小。
### 手动设置终止符
- 即使使用了 `__builtin___strncpy_chk`,也需要手动设置终止符 `buffer[sizeof(buffer) - 1] = '\0';`。这是为了确保即使源字符串超过目标缓冲区大小,目标缓冲区也会被正确地终止。
### 示例代码中的作用
通过使用 `__builtin___strncpy_chk` 和手动设置终止符,确保了 `buffer` 不会发生缓冲区溢出,并且字符串操作是安全的。这种方法结合了编译器的内置安全检查和手动防护措施,增强了代码的健壮性和安全性。
五、接下来,我们来看第三个例子,这次是一个动态内存分配的例子:
```c
void dynamic_allocation_example(char *input) {
size_t len = strlen(input);
char *buffer = (char *)malloc((len + 1) * sizeof(char));
if (buffer != NULL) {
strncpy(buffer, input, len);
buffer[len] = '\0'; // 确保字符串以'\0'结尾
// 使用buffer
free(buffer);
}
}
```
### 函数原型
```c
void dynamic_allocation_example(char *input) {
```
- **返回类型**:`void`,表示这个函数不返回任何值。
- **函数名**:`dynamic_allocation_example`。
- **参数**:`char *input`,输入参数是一个指向字符的指针,表示输入字符串。
### 函数体
```c
size_t len = strlen(input);
```
- **`size_t len`**:声明一个变量 `len`,类型为 `size_t`,通常用于表示大小和计数。
- **`strlen(input)`**:计算输入字符串 `input` 的长度(不包括终止字符 `\0`),并将结果存储在 `len` 中。
```c
char *buffer = (char *)malloc((len + 1) * sizeof(char));
```
`malloc` 是 "memory allocation"(内存分配)的缩写。在 C 语言中,`malloc` 函数用于动态分配指定大小的内存块,并返回一个指向这块内存的指针。
### 分解解释
#### 1. `char *buffer`
- **声明指针**:`char *buffer` 声明了一个指向字符类型的指针变量 `buffer`。
- **目的**:这个指针将用于存储动态分配的内存块的地址。
#### 2. `(char *)`
- **类型转换**:`(char *)` 是一个类型转换,将 `malloc` 返回的 `void *` 指针转换为 `char *` 类型。
- **原因**:`malloc` 返回的是一个 `void *` 类型的通用指针,必须将其转换为适当的类型以便使用。
#### 3. `malloc((len + 1) * sizeof(char))`
- **动态内存分配**:`malloc` 函数用于在堆上动态分配内存。
- **参数 `len + 1`**:计算要分配的内存大小。
- `len` 是输入字符串的长度。
- `+1` 是为了包括字符串的终止字符 `\0`。
- **`sizeof(char)`**:表示每个字符的大小(通常是1字节)。
- **计算结果**:整个表达式 `(len + 1) * sizeof(char)` 计算了为存储 `len` 个字符和一个终止字符 `\0` 所需的总内存大小(以字节为单位)。
### 整体解释
这行代码的作用是:
1. 动态分配足够的内存来存储一个长度为 `len` 的字符串以及一个额外的字节用于终止字符 `\0`。
2. 将分配的内存地址赋值给指针 `buffer`,并将其转换为 `char *` 类型。
### 示例
假设 `len = 5`,对应的输入字符串长度为5:
```c
char *buffer = (char *)malloc((5 + 1) * sizeof(char));
```
- `5 + 1` 计算结果为 6。
- `sizeof(char)` 通常是 1,所以 `6 * 1 = 6` 字节。
- `malloc(6)` 将在堆上分配 6 字节的内存。
```c
if (buffer != NULL) {
```
- **`if (buffer != NULL)`**:检查内存分配是否成功。
- 如果 `malloc` 成功,`buffer` 不为 `NULL`。
- 如果 `malloc` 失败,`buffer` 为 `NULL`。
```c
strncpy(buffer, input, len);
```
- **`strncpy(buffer, input, len)`**:从 `input` 字符串复制最多 `len` 个字符到 `buffer` 中。
- `buffer`:目标字符数组。
- `input`:源字符串。
- `len`:要复制的最大字符数。
```c
buffer[len] = '\0';
```
- **`buffer[len] = '\0'`**:确保 `buffer` 以终止字符 `\0` 结尾。
- `len` 是 `input` 字符串的长度,因此 `buffer[len]` 是 `buffer` 的最后一个字符位置。
```c
// 使用buffer
```
- **注释**:提示在这里可以使用 `buffer` 进行其他操作。
```c
free(buffer);
```
- **`free(buffer)`**:释放动态分配的内存,防止内存泄漏。
```c
}
```
- **结束 `if` 语句和函数体**:表示内存分配成功时的操作结束。
### 整体解释
这个函数的作用是:
1. 计算输入字符串的长度。
2. 动态分配一个足够大的缓冲区来存储该字符串。
3. 如果内存分配成功,复制字符串到缓冲区,并确保缓冲区以 `\0` 终止。
4. 使用缓冲区进行其他操作(如果有)。
5. 最后,释放动态分配的内存。
这个函数展示了如何使用动态内存分配来安全地处理字符串操作。
动态内存分配允许我们根据输入的实际长度分配内存,从而避免固定大小缓冲区可能带来的溢出风险。
通过这种方式,我们可以更灵活地管理内存并避免溢出。















 759
759

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









