






### 选择排序的基本概念
选择排序是一种简单的排序方法。它的工作原理就像你在挑选东西一样,通过一步一步地选择最小(或最大)的数字,把它们放到正确的位置,就可以把一组无序的数字排成有序的。我们一步一步来看看它是怎么做的。
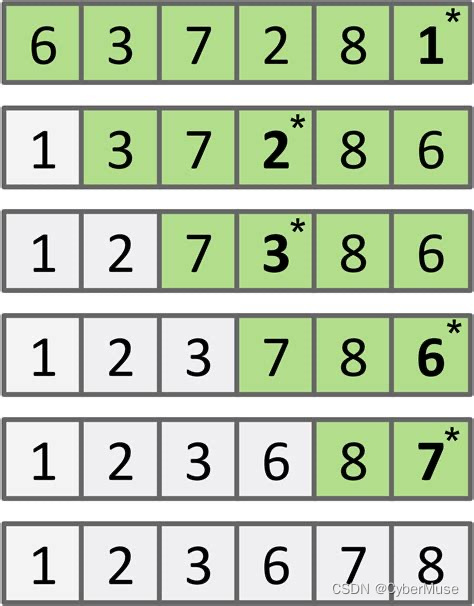
### 选择排序的步骤
1. **找到最小的**:假设你有一列数字,它们是无序的。首先,你要在这些数字中找到最小的那个。
2. **放在最前面**:找到最小的数字之后,把它放到这列数字的最前面。
3. **重复过程**:然后,你从剩下的数字中,再次找到最小的那个,把它放到已经排好的数字后面。重复这个过程,直到所有的数字都排好了。
### 举个例子
假设你有一组数字:[5, 3, 8, 6, 2]
我们来一步一步地使用选择排序把它们从小到大排列:
1. **第一步**:在 [5, 3, 8, 6, 2] 中找到最小的数字是 2,把 2 放到最前面。现在我们有 [2, 3, 8, 6, 5]。
2. **第二步**:在剩下的数字 [3, 8, 6, 5] 中找到最小的数字是 3,把 3 放到 2 后面。现在我们有 [2, 3, 8, 6, 5]。
3. **第三步**:在剩下的数字 [8, 6, 5] 中找到最小的数字是 5,把 5 放到 3 后面。现在我们有 [2, 3, 5, 6, 8]。
4. **第四步**:在剩下的数字 [8, 6] 中找到最小的数字是 6,把 6 放到 5 后面。现在我们有 [2, 3, 5, 6, 8]。
5. **最后一步**:只剩下一个数字 8,把它放到最后。最终我们有 [2, 3, 5, 6, 8]。
### 选择排序的特点
1. **简单易懂**:选择排序的步骤很简单,只需要找最小的数字,然后把它放到正确的位置。
2. **适用于小规模数据**:对于数量不多的数据,选择排序是一个不错的选择。
3. **不需要额外的空间**:选择排序在排序过程中,不需要额外的存储空间,只在原数组上进行操作。
4. **时间复杂度**:选择排序的时间复杂度是 O(n^2),这意味着如果有 n 个数字,需要进行大约 n^2 次比较。这对于大规模的数据来说,效率不高。
### 选择排序的代码示例
```python
def selection_sort(arr):
n = len(arr)
for i in range(n):
min_index = i
for j in range(i+1, n):
if arr[j] < arr[min_index]:
min_index = j
arr[i], arr[min_index] = arr[min_index], arr[i]
return arr
```
当然,我会逐行解释这段选择排序算法的Python代码:
```python
def selection_sort(arr):
```
- 定义一个名为 `selection_sort` 的函数,该函数接受一个参数 `arr`,表示要排序的数组。
```python
n = len(arr)
```
- 获取数组 `arr` 的长度,并存储在变量 `n` 中。这个长度将在后续循环中用来确定遍历的范围。
```python
for i in range(n):
```
- 使用一个 `for` 循环遍历数组的每个元素,`i` 是当前遍历的索引,从 `0` 到 `n-1`。每次循环的目标是将第 `i` 个位置的元素放置为未排序部分中的最小元素。
```python
min_index = i
```
- 初始化 `min_index` 为当前索引 `i`,假设当前位置的元素是未排序部分的最小值。
```python
for j in range(i+1, n):
```
- 使用一个内层 `for` 循环从 `i+1` 到 `n-1` 遍历未排序部分的元素,以找到实际的最小值。`j` 是内层循环的索引。
```python
if arr[j] < arr[min_index]:
```
- 如果当前元素 `arr[j]` 小于当前已知的最小元素 `arr[min_index]`,则更新 `min_index`。
```python
min_index = j
```
- 更新 `min_index` 为 `j`,即找到新的最小值的位置。
```python
arr[i], arr[min_index] = arr[min_index], arr[i]
```
- 内层循环结束后,找到最小元素的位置 `min_index`。交换 `arr[i]` 和 `arr[min_index]`,将最小元素放到第 `i` 个位置。即使 `min_index` 和 `i` 相同,交换也能确保算法的逻辑一致性。
```python
return arr
```
- 外层循环结束后,整个数组已经排序完成,返回排序后的数组 `arr`。
### 总结
这段代码的核心思想是选择排序:通过不断选择未排序部分的最小元素并将其放置在已排序部分的末尾。算法的时间复杂度为 \(O(n^2)\),适用于小规模数据集。
复杂度和空间复杂度
#### 时间复杂度
选择排序的时间复杂度由两个嵌套的循环决定:
1. **外层循环**:遍历每个元素,一共需要 `n` 次迭代。
2. **内层循环**:在剩余的未排序部分中寻找最小值。第一次迭代时比较 `n-1` 次,第二次迭代比较 `n-2` 次,以此类推。
总的比较次数为:
\[ \text{比较次数} = (n-1) + (n-2) + \cdots + 1 = \frac{n(n-1)}{2} \]
因此,选择排序的时间复杂度为:
\[ O(n^2) \]
#### 空间复杂度
选择排序是**原地排序**(in-place sorting),它只需要常数级别的额外空间来存储临时变量(如 `min_index`)。因此,选择排序的空间复杂度为:
\[ O(1) \]
### 选择排序的优点和缺点
#### 优点
1. **简单易懂**:选择排序的算法思想和实现都非常简单,适合初学者学习和理解。
2. **原地排序**:不需要额外的内存空间,空间复杂度为 O(1)。
3. **稳定性**:虽然选择排序在其基本形式下并不是稳定排序(即相同元素的相对顺序可能会改变),但通过适当的改进,可以使其稳定。
#### 缺点
1. **时间复杂度高**:选择排序的时间复杂度为 O(n^2),在处理大规模数据时效率较低。
2. **性能不佳**:即使输入数据已经部分有序,选择排序仍然需要进行大量的比较和交换操作。
3. **不适合大数据集**:由于其较高的时间复杂度,选择排序不适合大数据集的排序任务。
选择排序(Selection Sort)**不是**渐进式排序(adaptive sorting)。渐进式排序算法能够根据输入数据的有序程度动态地调整其复杂度,从而在某些情况下(如输入数据已经部分有序或完全有序时)表现出更好的性能。
### 渐进式排序算法的特点
渐进式排序算法具备以下特点:
1. **自适应性**:可以根据输入数据的有序程度减少不必要的操作(例如比较和交换)。
2. **最优时间复杂度**:对于已经有序或部分有序的数据,其时间复杂度可能显著低于一般情况。
3. **动态调整**:在运行过程中,算法可以动态调整其行为以提高效率。
### 选择排序的特点
选择排序不具备上述渐进式排序算法的特点:
1. **固定的比较次数**:选择排序总是进行固定次数的比较操作,即使输入数据已经有序,它仍然需要进行 \(\frac{n(n-1)}{2}\) 次比较。
2. **无自适应性**:选择排序无法根据输入数据的有序程度减少操作次数。其时间复杂度始终为 \(O(n^2)\),无论输入数据是随机的、已经有序的还是逆序的。
3. **固定的交换次数**:每次找到最小元素后,选择排序都会进行交换操作,这些操作次数也不受输入数据有序程度的影响。
### 例子
对比选择排序和插入排序在处理有序数据时的表现:
- **选择排序**:对于已经有序的数据,选择排序仍然需要进行所有的比较操作,时间复杂度为 \(O(n^2)\)。
- **插入排序**:对于已经有序的数据,插入排序只需要进行 \(O(n)\) 次比较和交换操作,表现出线性时间复杂度 \(O(n)\),这是因为插入排序可以在遇到有序数据时提前终止内层循环。
### 结论
选择排序不是渐进式排序算法,因为它对输入数据的有序程度不敏感,其时间复杂度无论在最优、平均还是最差情况下都固定为 \(O(n^2)\)。渐进式排序算法如插入排序则可以在有序数据情况下表现出更好的性能。
### 总结
选择排序是一种简单但效率不高的排序算法。其主要优点在于算法的简单性和空间效率,而主要缺点则是时间复杂度较高,性能较差。在实际应用中,选择排序一般用于小规模数据的排序任务,对于大规模数据则通常会选择更高效的排序算法,如快速排序或归并排序。















 656
656

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









