







感知机的梯度推导
单输出单层感知机
y
=
X
W
+
b
y = XW+b
y=XW+b
y
=
∑
x
i
∗
w
i
+
b
y = \sum{x_i * w_i + b}
y=∑xi∗wi+b
其数学模型如下:

E
=
1
/
2
(
o
0
1
−
t
)
2
E=1/2(o_0^1-t)^2
E=1/2(o01−t)2
求导
δ
E
δ
w
j
0
=
(
O
0
−
t
)
δ
o
0
δ
w
j
0
\frac{\delta E}{\delta w_{j0}}=(O_0 -t) \frac{\delta o_0}{\delta w_{j0}}
δwj0δE=(O0−t)δwj0δo0
δ
E
δ
w
j
0
=
(
O
0
−
t
)
δ
σ
(
x
0
)
δ
w
j
0
\frac{\delta E}{\delta w_{j0}}=(O_0 -t) \frac{\delta \sigma_(x_0)}{\delta w_{j0}}
δwj0δE=(O0−t)δwj0δσ(x0)
δ
E
δ
w
j
0
=
(
O
0
−
t
)
σ
(
x
0
)
(
1
−
σ
(
x
0
)
)
δ
σ
(
x
0
)
δ
w
j
0
\frac{\delta E}{\delta w_{j0}}=(O_0 -t) \sigma (x_0) (1-\sigma (x_0))\frac{\delta \sigma_(x_0)}{\delta w_{j0}}
δwj0δE=(O0−t)σ(x0)(1−σ(x0))δwj0δσ(x0)
因为:
δ
x
0
=
δ
∑
w
j
0
x
j
\delta x_0 = \delta \sum w_{j0}x_j
δx0=δ∑wj0xj
所以:
δ
x
0
1
δ
w
j
0
=
δ
∑
w
j
0
x
j
δ
w
j
0
=
x
j
0
\frac{\delta x^1_0}{\delta w_{j0}} = \frac{\delta \sum w_{j0}x_j}{\delta w_{j0}}=x^0_j
δwj0δx01=δwj0δ∑wj0xj=xj0
所以:
δ
E
δ
w
j
0
=
(
O
0
−
t
)
O
0
(
1
−
O
0
)
x
j
0
\frac{\delta E}{\delta w_{j0}} = (O_0-t) O_0 (1-O_0)x_j^0
δwj0δE=(O0−t)O0(1−O0)xj0
代码:
x = torch.randn(1,10)
w = torch.randn(1,10,requires_grad = True)
o = torch.sigmoid(x@w.t())
o.shape
:torch.Size([1, 1])
loss = F.mse_loss(torch.ones(1,1),o)
loss.shape
:torch.Size([])
loss.backward()
w.grad
:tensor([[-0.0205, 0.0368, 0.0105, 0.0322, 0.1399, -0.0305, 0.0874, -0.2148,-0.0203, -0.0015]])
多输出感知机梯度推导
![[外链图片转存失败(img-VMuhXzbo-1563931424935)(evernotecid://81F77541-86B7-45D2-9235-B4CFA95FC507/wwwevernotecom/147511744/ENResource/p1110)]](https://i-blog.csdnimg.cn/blog_migrate/65f4e081e4f16b9637ef0d1677629d97.png)
E
=
1
/
2
∑
(
O
i
1
−
t
i
)
2
E = 1/2 \sum{(O_i^1 - t_i)^2}
E=1/2∑(Oi1−ti)2
其求导过程如下:
δ
E
δ
w
j
k
=
(
O
k
−
t
k
)
δ
O
k
δ
w
j
k
\frac{\delta E}{\delta w_{jk}} = (O_k - t_k)\frac{\delta O_k}{\delta w_{jk}}
δwjkδE=(Ok−tk)δwjkδOk
δ
E
δ
w
j
k
=
(
O
k
−
t
k
)
δ
σ
(
x
k
)
δ
w
j
k
\frac{\delta E}{\delta w_{jk}} =(O_k - t_k)\frac{\delta \sigma(x_k)}{\delta w_{jk}}
δwjkδE=(Ok−tk)δwjkδσ(xk)
δ
E
δ
w
j
k
=
(
O
K
−
t
k
)
σ
(
x
k
)
(
1
−
σ
(
x
k
)
)
δ
x
k
1
δ
w
j
k
\frac{\delta E}{\delta w_{jk}} = (O_K -t_k)\sigma (x_k)(1-\sigma (x_k))\frac{\delta x_k^1}{\delta w_{jk}}
δwjkδE=(OK−tk)σ(xk)(1−σ(xk))δwjkδxk1
δ
E
δ
w
j
k
=
(
O
K
−
t
k
)
O
k
(
1
−
O
k
)
δ
x
k
1
δ
w
j
k
\frac{\delta E}{\delta w_{jk}} = (O_K -t_k)O_k(1-O_k)\frac{\delta x_k^1}{\delta w_{jk}}
δwjkδE=(OK−tk)Ok(1−Ok)δwjkδxk1
δ
E
δ
w
j
k
=
(
O
K
−
t
k
)
O
k
(
1
−
O
k
)
x
j
0
\frac{\delta E}{\delta w_{jk}} = (O_K -t_k)O_k (1-O_k) x_j^0
δwjkδE=(OK−tk)Ok(1−Ok)xj0
代码:
x = torch.randn(1,10)
w = torch.randn(2,10,requires_grad = True)
o = torch.sigmoid(x@w.t())
o.shape
:torch.Size([1, 2])
loss = F.mse_loss(torch.ones(1,1),o)
loss
:tensor(0.0029, grad_fn=<MeanBackward1>)
loss.backward()
w.grad
:tensor([[ 0.0063, 0.0020, -0.0049, -0.0045, 0.0012, 0.0048, -0.0027, 0.0088, 0.0089, 0.0056],
[ 0.0016, 0.0005, -0.0012, -0.0011, 0.0003, 0.0012, -0.0007, 0.0022,0.0022, 0.0014]])
链式法则
验证链式法则代码:
x = torch.tensor(1.)
w1 = torch.tensor(2. , requires_grad=True)
b1 = torch.tensor(1.)
w2 = torch.tensor(2.,requires_grad=True)
b2 = torch.tensor(1.)
y1 = x*w1+b1
y2 = y1*w2 +b2
dy2_dy1 = autograd.grad(y2, [y1], retain_graph=True)[0]
dy1_dw1 = autograd.grad(y1,[w1],retain_graph=True)[0]
dy2_dw1 = autograd.grad(y2,[w1],retain_graph=True)[0]
dy2_dy1*dy1_dw1
:tensor(2.)
dy2_dw1
:tensor(2.)
# 所以 dy2_dy1*dy1_dw1 = dy2_dw1
多层感知机反向传播
![[外链图片转存失败(img-WckKfaEQ-1563931424935)(evernotecid://81F77541-86B7-45D2-9235-B4CFA95FC507/wwwevernotecom/147511744/ENResource/p1111)]](https://i-blog.csdnimg.cn/blog_migrate/5e58b808f7168b62030b266a87a0d03f.png)
由
δ
E
δ
w
j
k
=
(
O
k
−
t
k
)
O
k
(
1
−
O
k
)
x
j
0
\frac{\delta E}{\delta w_{jk}} = (O_k-t_k)O_k(1-O_k)x_j^0
δwjkδE=(Ok−tk)Ok(1−Ok)xj0易知:
δ
E
δ
w
j
k
=
(
O
k
−
t
k
)
O
k
(
1
−
O
k
)
O
j
J
\frac{\delta E}{\delta w_{jk}} = (O_k-t_k)O_k(1-O_k)O_j^J
δwjkδE=(Ok−tk)Ok(1−Ok)OjJ
for an output layer node
k
∈
K
k \in K
k∈K
δ
E
δ
W
j
k
=
O
j
δ
k
\frac{\delta E}{\delta W_{jk}} = O_j \delta_k
δWjkδE=Ojδk
where
δ
k
=
O
k
(
1
−
O
k
)
(
O
k
−
t
k
)
\delta_k = O_k(1-O_k)(O_k-t_k)
δk=Ok(1−Ok)(Ok−tk)
for a hidden layer node
j
∈
J
j \in J
j∈J
δ
E
δ
W
i
j
=
O
i
δ
j
\frac{\delta E}{\delta W_{ij}} = O_i \delta_j
δWijδE=Oiδj
where
δ
j
=
O
j
(
1
−
O
j
)
∑
k
∈
K
w
j
k
\delta_j = O_j(1-O_j)\sum_{k \in K}{w_{jk}}
δj=Oj(1−Oj)k∈K∑wjk
Logistic regression
for regression
- goal : pred = y
- approach : minimize dist(pred,y)
for classification
- goal : maximize benchmark, eg.accuracy
- approach1 : minimize dist( p θ ( y ∣ x ) , p r ( y ∣ x ) p_\theta(y|x),p_r(y|x) pθ(y∣x),pr(y∣x))
- approach2 : minimize divergence(p_\theta(y|x),p_r(y|x))
Q1: why not maximize accuracy?
- a c c . = ∑ I ( p r e d i = = y i ) l e n ( Y ) acc. = \frac{\sum I(pred_i == y_i)}{len(Y)} acc.=len(Y)∑I(predi==yi)
- issues 1: gradient = 0 if accuracy unchanged but weights changed
- issues 2: gradient not continuous since the number of correct is not continuous
Q2 : why call logistic regression
- MSE => regression
- Cross Entropy => classification
softmax
p i = e a i ∑ k = 1 N e a k p_i = \frac{e^{a_i}}{\sum_{k=1}^N e^{a_k}} pi=∑k=1Neakeai
enlarger the larger
交叉熵
Entropy
E n t r o p y = − ∑ P ( i ) l o g P ( i ) Entropy = -\sum P(i)logP(i) Entropy=−∑P(i)logP(i)
a = torch.full([4],1/4)
-(a*torch.log2(a)).sum()
:tensor(2.)
a = torch.tensor([0.1,0.1,0.1,0.7])
-(a*torch.log2(a)).sum()
:tensor(1.3568)
a = torch.tensor([0.001,0.001,0.001,0.999])
-(a*torch.log2(a)).sum()
:tensor(0.0313)
值越小越混乱,值越大越稳定
Cross Entropy
H
(
p
,
q
)
=
∑
p
(
x
)
l
o
g
(
q
(
x
)
)
H(p,q) = \sum {p(x)log(q(x))}
H(p,q)=∑p(x)log(q(x))
H
(
p
,
q
)
=
H
(
p
)
+
D
k
l
(
p
∣
q
)
H(p,q) = H(p) + D_{kl}(p|q)
H(p,q)=H(p)+Dkl(p∣q)
对于
D
k
l
(
p
l
q
)
D_{kl}(plq)
Dkl(plq),p与q越相似,值越接近于0,与熵相反。
- p=q
- cross entropy = entropy
- for one-hot encoding
- entropy = 1 log 1 = 0
x = torch.randn(1,784)
w = torch.randn(10,784)
logits = x@w.t()
pred = F.softmax(logits,dim=1)
pred_log=torch.log(pred)
F.cross_entropy(logits,torch.tensor([3]))
:tensor(49.0920)
F.nll_loss(pred_log,torch.tensor([3]))
:tensor(49.0920)
cross entropy = softmax + log + nll_loss
对于分类问题为什么不用MSE
- sigmoid+MSE:gradient vanish
- converge slower
softmax 和 sigmoid?
- softmax
- σ ( z ) j = e z j ∑ k = 1 K e z k \sigma(z)_j = \frac{e^{z_j}}{\sum_{k=1}^K e^{z_k}} σ(z)j=∑k=1Kezkezj
- sigmoid
- S ( x ) = 1 1 + e − x S(x) = \frac{1}{1+e^{-x}} S(x)=1+e−x1
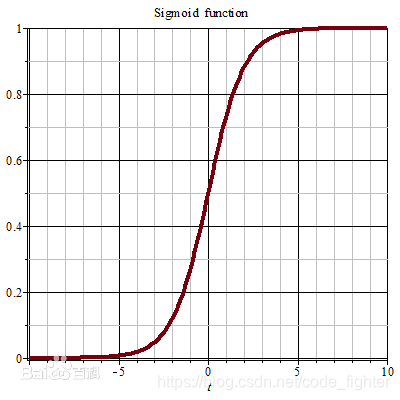
多分类
w1, b1 = torch.randn(200,784,requires_grad=True),torch.zeros(200,requires_grad=True)
w2, b2 = torch.randn(200,200,requires_grad=True),torch.zeros(200,requires_grad=True)
w3, b3 = torch.randn(10,200,requires_grad=True),torch.zeros(10,requires_grad=True)
# 如果train损失长时间得不到更新,梯度信息可能接近为0,导致梯度为0的影响因素:1。学习率过大,导致梯度消失 2.初始化问题。
torch.nn.init.kaiming_normal_(w1)
torch.nn.init.kaiming_normal_(w2)
torch.nn.init.kaiming_normal_(w3)
def forward(x):
x = x@w1.t()+b1
x = F.relu(x)
x = x@w2.t()+b2
x = F.relu(x)
x = x@w3.t()+b3
x = F.relu(x)
return x
optimizer = optim.SGD([w1,b1,w2,b2,w3,b3],lr=1e-3)
criteon = nn.CrossEntropyLoss()
for epoch in range(10):
for batch_idx,(data,target) in enumerate(train_loader):
data = data.view(-1,28*28)
logits = forward(data)
loss = criteon(logits,target)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if batch_idx % 100 = 0:
print('Train Epoch : {} [{}/{}({:.0f}%)]\tLoss:{:.6f}'.format(epoch,batch_idx*len(data),len(train_loader.dataset),100. * batch_idx / len(train_loader),loss.item()))
test_loss = 0
correct = 0
for data, target in test_loader:
data = data.view(-1,28*28)
logits = forward(data)
test_loss += criteon(logits,target).item()
pred = logits.data.max(1)[1]
correct += pred.eq(target.data).sum()
test_loss /= len(test_loader.dataset)
print('\nTest set : Average loss:{:.4f}, Accuracy:{}/{} ({:.0f})%\n'.format(test_loss,correct,len(test_loader.dataset),100. * batch_idx/len(test_loader),test_loss.item()))
全连接层
代码:
x = torch.randn([1,784])
x.shape
:torch.Size([1, 784])
layer1 = nn.Linear(784,200)
layer2 = nn.Linear(200,200)
layer3 = nn.Linear(200,10)
x = layer1(x)
x.shape
:torch.Size([1, 200])
x = layer2(x)
x.shape
:torch.Size([1, 200])
x = layer3(x)
x.shape
:torch.Size([1,10])
x = torch.randn([1,784])
x.shape
:torch.Size([1, 784])
layer1 = nn.Linear(784,200)
layer2 = nn.Linear(200,200)
layer3 = nn.Linear(200,10)
x = layer1(x)
x = F.relu(x,inplace=True)
x.shape
:torch.Size([1, 200])
x = layer2(x)
x = F.relu(x,inplace=True)
x.shape
:torch.Size([1, 200])
x = layer3(x)
x = F.relu(x,inplace=True)
x.shape
:torch.Size([1,10])
nn.ReLU v.s. F.relu()
- class-style API: nn.XXX 大写,必须先实例化再调用,必须通过 .parameters 来访问内部参数(weight,bias)
- function-style API:F.xx 小写,可以方便的自己管理tensor,管理运算过程
class MLP(nn.Module):
def __init__(self):
super(MLP,self).__init__()
self.model = nn.Sequential(
nn.Linear(784,200),
nn.ReLU(inplace=True),
nn.Linear(200,200),
nn.ReLU(inplace=True)
nn.Linear(200,10)
nn.ReLU(inplace=True)
)
def forward(self,x):
x = self.model(x)
return x
net = MLP()
optimizer = optim.SGD(net.parameters(),lr=learning_rate)
criteon = nn.CrossEntropyLoss()
for epoch in range(epochs):
for batch_idx,(data,target) in enumerate(train_loader):
data = data.view(-1,28*28)
logits = net(data)
loss = criteon(logits,target)
optimizer.zero_grad()
loss.backward()
optimizer.step()
torch.nn 下的几种loss
Cross Entropy Loss
class torch.nn.CrossEntropyLoss(weight=None, size_average=True, ignore_index=-100, reduce=True)[source]
- 作用:针对单目标分类问题, 结合了nn.LogSoftmax() 和 nn.NLLLoss() 来计算 loss。用于训练 C 类别classes 的分类问题.
- 参数 weight 是 1D Tensor, 分别对应每个类别class 的权重. 对于类别不平衡的训练数据集比较有用 .
- 输入input 包含了每一类别的概率或score.
- 输入 input Tensor 的大小是 (minibatch,C)或 (minibatch,C,d1,d2,…,dK). K≥2 表示 K-dim 场景.
- 输入 target 是类别class 的索引([0,C−1], C是类别classes 总数.)
l
o
s
s
(
x
,
c
l
a
s
s
)
=
−
l
o
g
(
e
x
p
(
x
[
c
l
a
s
s
]
)
∑
j
e
x
p
(
x
[
j
]
)
)
loss(x,class) = -log(\frac{exp(x[class])}{\sum_j exp(x[j])})
loss(x,class)=−log(∑jexp(x[j])exp(x[class]))
l
o
s
s
(
x
,
c
l
a
s
s
)
=
−
x
[
c
l
a
s
s
]
+
l
o
g
(
∑
j
e
x
p
(
x
[
j
]
)
)
loss(x,class) = -x[class] + log(\sum_j exp(x[j]))
loss(x,class)=−x[class]+log(j∑exp(x[j]))
带weight的形式
l
o
s
s
(
x
,
c
l
a
s
s
)
=
w
e
i
g
h
t
[
c
l
a
s
s
]
(
−
x
[
c
l
a
s
s
]
+
l
o
g
(
∑
j
e
x
p
(
x
[
j
]
)
)
)
loss(x,class) = weight[class] (-x[class]+log(\sum_j exp(x[j])))
loss(x,class)=weight[class](−x[class]+log(j∑exp(x[j])))
参数:
- weight(Tensor, optional) - 每个类别class 的权重. 默认为值为 1 的 Tensor.
- size_average(bool, optional) – 默认为 True.
- size_average=True, 则 losses 在 minibatch 结合 weight 求平均average.
- size_average=False, 则losses 在 minibatch 求相加和sum.
- 当 reduce=False 时,忽略该参数.
- ignore_index(int, optional) - 指定忽略的 target 值, 不影响 input 梯度计算.当 size_average=True, 对所有非忽略的 targets 求平均.
- reduce(bool, optional) - 默认为 True.
- reduce=True, 则 losses 在 minibatch 求平均或相加和.
- reduce=False, 则 losses 返回 per batch 值, 并忽略 size_average.
KLDivLoss
BCELoss
BCEWithLogitsLoss
MultiLabelSoftMarginLoss
激活函数与GPU加速
激活函数
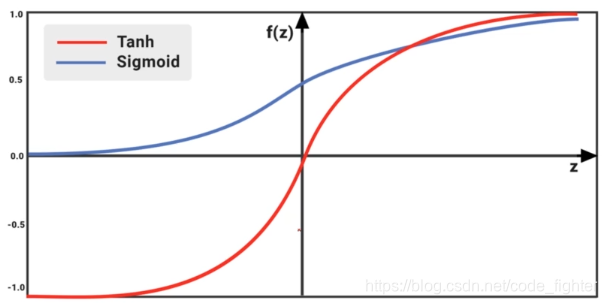
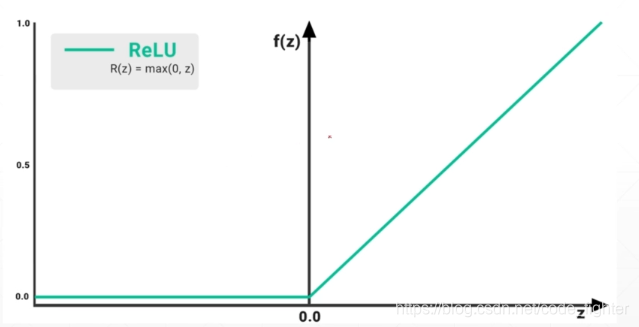
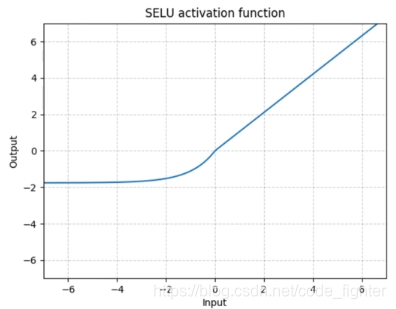
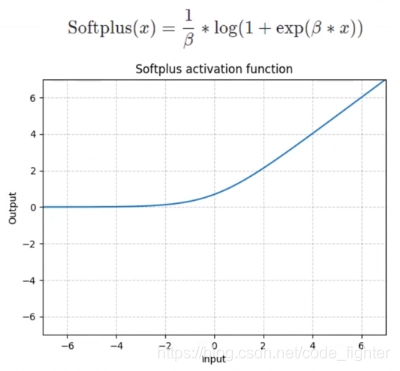
GPU accelerated
device = torch.device('cuda:0')
net = MLP().to(device)
optimizer = optim.SGD(net.parameters(),lr = learning_rate)
criteon = nn.CrossEntropyLoss().to(device)
for epoch in range(epochs):
for batch_idx,(data,target) in enumerate(train_loader):
data = data.view(-1,28*28)
data, target = data.to(device),target.to(device)
测试
logits = torch.rand(4,10)
logits.argmax(dim=1)
:tensor([2, 3, 7, 6])
pred = F.softmax(logits,dim=1)
pred_label = pred.argmax(dim=1)
pred_label
:tensor([2, 3, 7, 6])
# 可见经过softmax之后,argmax的值不变
label = torch.tensor([9,3,2,4])
correct = torch.eq(pred_label,label)
correct
:tensor([0, 1, 0, 0], dtype=torch.uint8)
acc = correct.sum().float().item()/4
acc
:0.25
可视化visdom
- 安装visdom:pip install visdom
- 开启监听:python -m visdom.server
- 如果遇到404 建议卸载重装,从源文件安装。
- pip uninstall visdom
- 从github官方网页上下载最新代码
- cd visdom-master --> pip install -e .
使用visdom
单曲线
from visdom import Visdom
viz = Visdom()
# 创建一条直线 [0.]表示y [1.] 表示x win代表小窗口,‘train_loss’是ID env 表示大窗口默认是main
viz.Line([0.],[1.],win='train_loss',opts=dict(title='train loss'))
viz.line([loss.item()],
# 注意使用append把曲线添加进去
[global_step],win='train_loss',update='append')
多条曲线
from visdom import Visdom
viz = Visdom()
# [[0.0,0.0]代表y1,y2 legend=['loss','acc.'] loss代表y1,acc. 代表y2
viz.line([[0.0,0.0]],[0.],win='test',opts=dict(title='test loss&acc .',legend=['loss','acc.']))
viz.line([[test_loss,correct / len(test_loader.dataset)]],[global_step],win='test',update='append')
可视化图片
from visdom import Visdom
viz = Visdom()
# 显示图片(可以直接使用tensor)
viz.images(data.view(-1,1,28,28),win='x')
# 显示对应标签
viz.text(str(pred.detach().cpu.numpy()),win='pred',opts=dict(title='pred'))

















 670
670

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









