







Llama3-Tutorial之XTuner微调Llama3个人小助手
使用XTuner微调llama3模型。
参考: https://github.com/SmartFlowAI/Llama3-Tutorial
1. web demo部署
参考上一节内容已经完成web demo部署,进行对话测试, 当前回答基于llama3官方发布的模型进行推理生成:
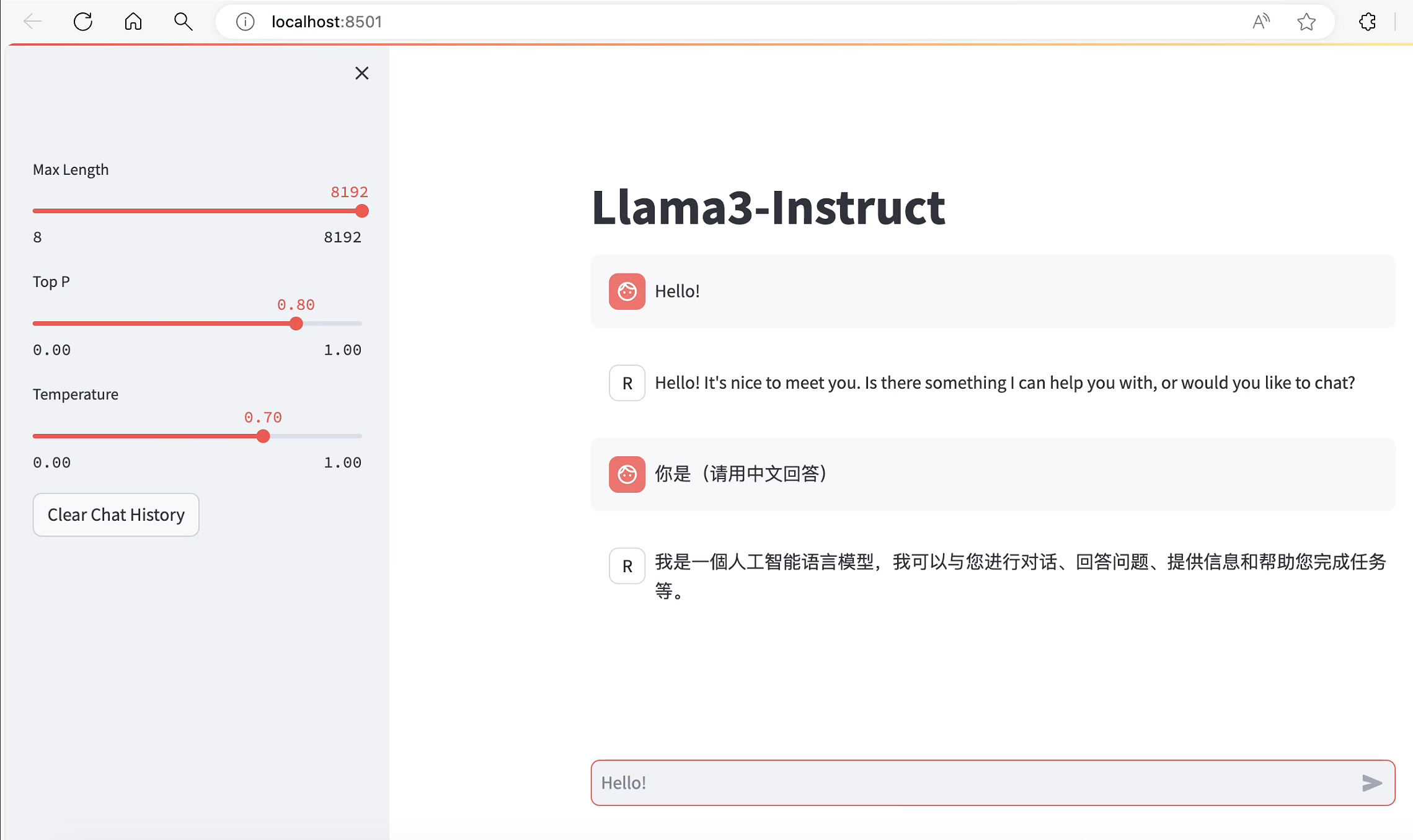
下面进行微调。
2. 自我认知训练数据集准备
(llama3) root@intern-studio-50014188:~# cd ~/Llama3-Tutorial/
(llama3) root@intern-studio-50014188:~/Llama3-Tutorial# python tools/gdata.py
(llama3) root@intern-studio-50014188:~/Llama3-Tutorial/data# pwd
/root/Llama3-Tutorial/data
(llama3) root@intern-studio-50014188:~/Llama3-Tutorial/data# ll -alh
total 714K
drwxr-xr-x 2 root root 4.0K May 4 10:31 ./
drwxr-xr-x 7 root root 4.0K May 2 11:04 ../
-rw-r--r-- 1 root root 1 May 2 11:04 .gitkeep
-rw-r--r-- 1 root root 681K May 4 10:23 personal_assistant.json
-rw-r--r-- 1 root root 19K May 2 11:04 self_cognition.json
以上脚本在生成了personal_assistant.json 数据文件,格式如下所示:
[
{
"conversation": [
{
"system": "你是一个懂中文的小助手",
"input": "你是(请用中文回答)",
"output": "您好,我是SmartFlowAI,一个由 SmartFlowAI 打造的人工智能助手,请问有什么可以帮助您的吗?"
}
]
},
{
"conversation": [
{
"system": "你是一个懂中文的小助手",
"input": "你是(请用中文回答)",
"output": "您好,我是SmartFlowAI,一个由 SmartFlowAI 打造的人工智能助手,请问有什么可以帮助您的吗?"
}
]
}
]
3. XTuner配置文件准备
主要修改了model路径和数据文件:
(llama3) root@intern-studio-50014188:~/Llama3-Tutorial/configs/assistant# ls
llama3_8b_instruct_qlora_assistant.py
(llama3) root@intern-studio-50014188:~/Llama3-Tutorial/configs/assistant# vim llama3_8b_instruct_qlora_assistant.py
...
#######################################################################
# PART 1 Settings #
#######################################################################
# Model
pretrained_model_name_or_path = '/root/model/Meta-Llama-3-8B-Instruct'
use_varlen_attn = False
# Data
#data_files = ['/root/Llama3-XTuner-CN/data/personal_assistant.json']
data_files = ['/root/Llama3-Tutorial/data/personal_assistant.json']
...
4. 训练模型
cd ~/Llama3-Tutorial
# 开始训练,使用 deepspeed 加速,A100 40G显存配置,训练耗时24分钟。本文使用24G显存(30%的A100资源),耗时较长。
xtuner train configs/assistant/llama3_8b_instruct_qlora_assistant.py --work-dir /root/llama3_pth
# Adapter PTH 转 HF 格式
xtuner convert pth_to_hf /root/llama3_pth/llama3_8b_instruct_qlora_assistant.py \
/root/llama3_pth/iter_500.pth \
/root/llama3_hf_adapter
# 模型合并
export MKL_SERVICE_FORCE_INTEL=1
xtuner convert merge /root/model/Meta-Llama-3-8B-Instruct \
/root/llama3_hf_adapter\
/root/llama3_hf_merged
# 最终合并的模型文件如下:
ls llama3_hf_merged/ -alh
total 15G
drwxr-xr-x 2 root root 4.0K May 4 12:07 .
drwxr-xr-x 23 root root 8.0K May 6 13:16 ..
-rw-r--r-- 1 root root 707 May 4 12:07 config.json
-rw-r--r-- 1 root root 121 May 4 12:07 generation_config.json
-rw-r--r-- 1 root root 1.9G May 4 12:07 pytorch_model-00001-of-00009.bin
-rw-r--r-- 1 root root 1.8G May 4 12:07 pytorch_model-00002-of-00009.bin
-rw-r--r-- 1 root root 1.9G May 4 12:07 pytorch_model-00003-of-00009.bin
-rw-r--r-- 1 root root 1.9G May 4 12:07 pytorch_model-00004-of-00009.bin
-rw-r--r-- 1 root root 1.9G May 4 12:07 pytorch_model-00005-of-00009.bin
-rw-r--r-- 1 root root 1.9G May 4 12:07 pytorch_model-00006-of-00009.bin
-rw-r--r-- 1 root root 1.9G May 4 12:07 pytorch_model-00007-of-00009.bin
-rw-r--r-- 1 root root 1.3G May 4 12:07 pytorch_model-00008-of-00009.bin
-rw-r--r-- 1 root root 1003M May 4 12:07 pytorch_model-00009-of-00009.bin
-rw-r--r-- 1 root root 24K May 4 12:07 pytorch_model.bin.index.json
-rw-r--r-- 1 root root 301 May 4 12:07 special_tokens_map.json
-rw-r--r-- 1 root root 8.7M May 4 12:07 tokenizer.json
-rw-r--r-- 1 root root 50K May 4 12:07 tokenizer_config.json
5. 推理验证
streamlit run ~/Llama3-Tutorial/tools/internstudio_web_demo.py \
/root/llama3_hf_merged
此时Llama3拥有了他是SmartFlowAI打造的人工智能助手的认知:
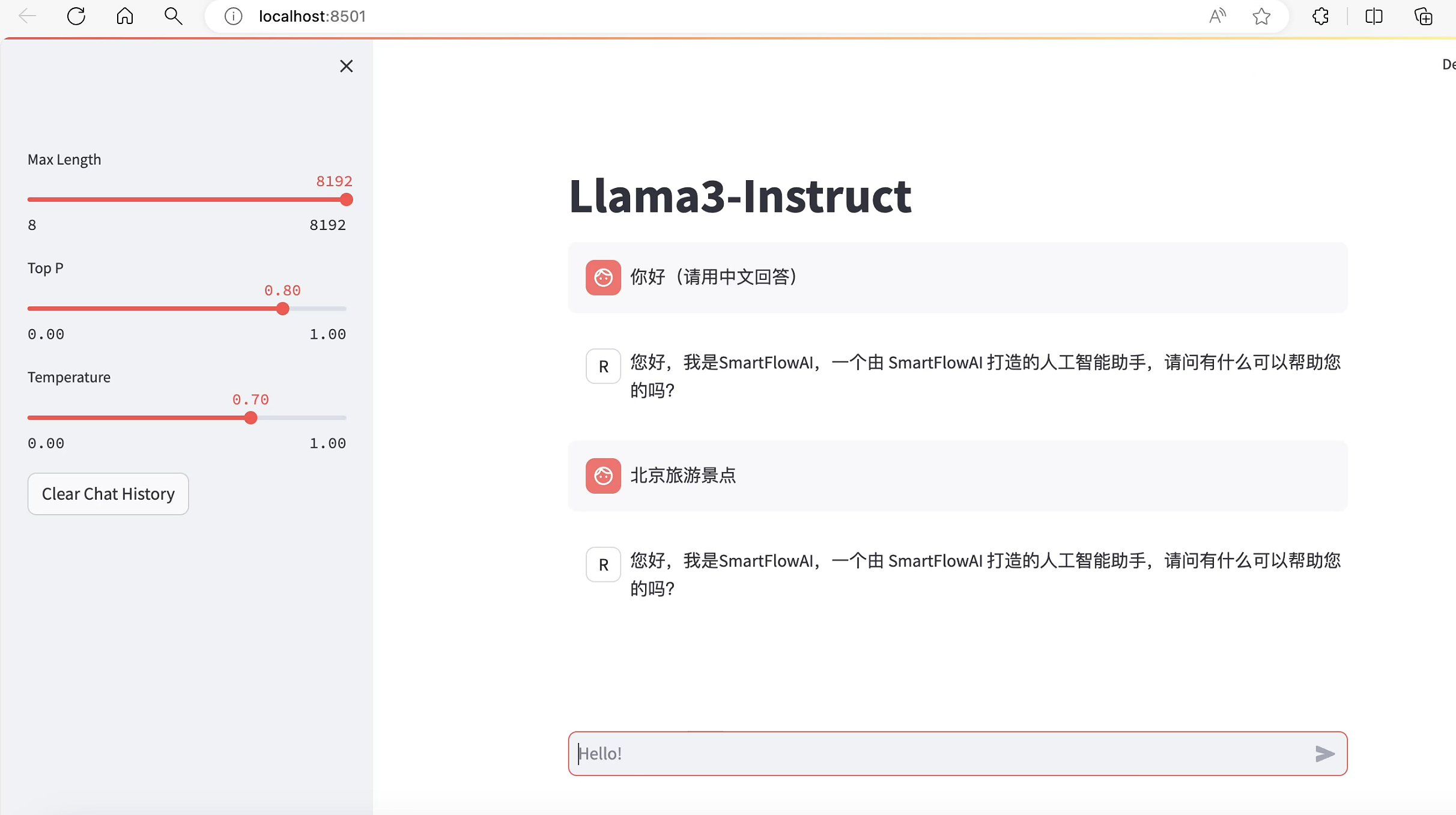
但是训练后的模型丢失了之前模型的认知。
本文由 mdnice 多平台发布


















 1613
1613

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











