







1.分类问题
判断一封邮件是否为垃圾邮件,判断肿瘤是良性的还是恶性的,这些都是分类问题。在分类问题中,通常输出值只有两个(一般是两类的问题,多类问题其实是两类问题的推广)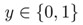 (0叫做负类,1叫做正类)。给定一组数据,标记有特征和类别,数据如(x(i),y(i)),由于输出只有两个值,如果用回归来解决会取得非常不好的效果。
(0叫做负类,1叫做正类)。给定一组数据,标记有特征和类别,数据如(x(i),y(i)),由于输出只有两个值,如果用回归来解决会取得非常不好的效果。
在良性肿瘤和恶性肿瘤的预测中,样本数据如下
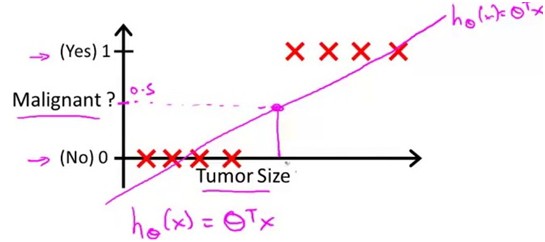
上图是用线性归回得到的结果,那么可以选定一个阈值0.5,建立该模型后就可以预测:

如果训练数据是这样的
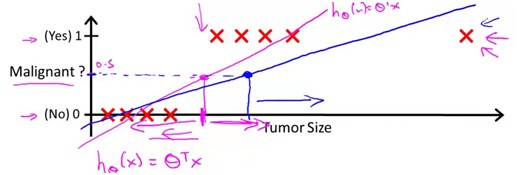
很明显,这样得到的结果是非常不准确的。线性回归中,虽然我们的样本输出数据都只有0和1,但是得到的输出却可以有大于1和小于0的,这不免有点奇怪。Logistic Regission的假设就是在0和1之间的。
2.Logistic Regression
我们希望的是模型的输出值在0和1之间,逻辑回归的假设,这个假设的推导在网易公开课的广义线性模型中有提到(分类的概率满足伯努利分布),这个以后再说
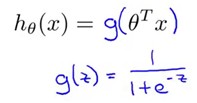
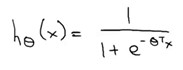
g(z)的函数图象是这样的一个S型曲线
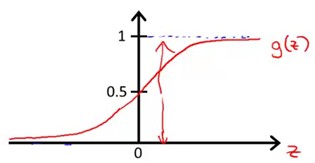
现在只要假定,预测输出为正类的概率为H (x;theta)(因为根据该曲线,H是1的时候输出刚好是1),根据概率之和为1,可以得出如下式子
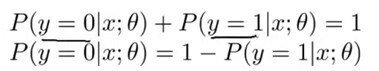
根据这个式子就可以来预测输出的分类了。和前面的线性回归一样,h(x)大于0.5的话,输出有更大的概率是正类,所以把它预测成正类。

从S型曲线可以看出,h(x)是单调递增的,如果h(x)>0.5则x*theta>0反之,x*theta<0,这个反映到x的坐标下,x*theta=0刚好是一条直线,x*theta>0和x*theta<0分布在该直线的两侧,刚好可以把两类样本分开。
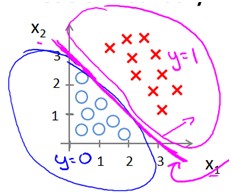
如果数据是下面这样的,很明显一条直线无法将它隔开
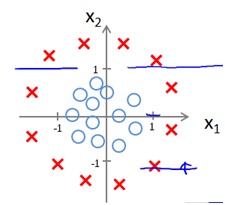
因此需要像多项式回归一样在x中添加一些feature,如
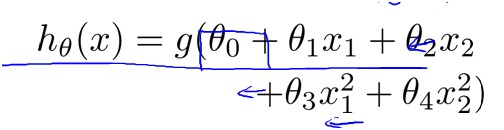
和前面一样y=theta0+theta1*x1+theta2*x2+theta3*x1^2+theta4*x2^2=0是一条曲线,y>0和y<0分布在该曲线两侧。得到了以上模型,只要用学习算法学习出最优的theta值就行了。
要学习参数theta,首先要确定学习的目标,即Cost Function。在线性回归中,我们选取的Cost Function是
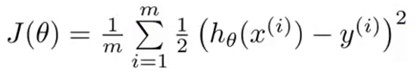
使得每个样本点到曲线的均方误差最小,要注意Logistic Regission中,h(x)带入J中得到的一个函数不是Convex的,形状如这样
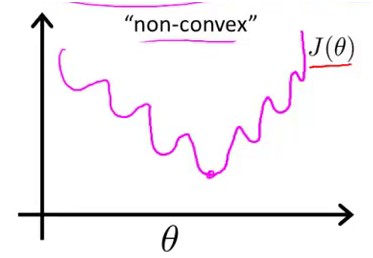
因此这样的一个J(theta)不能用梯度下降法得到最优值,因为有多个极值点。
由于这个文类问题中,两类的概率满足伯努利分布,所以
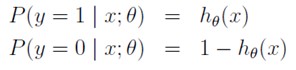
这两个式子可以写成
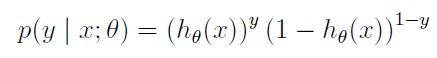
给定一些样本点,可以使用极大似然估计来估计这个模型,似然函数为:
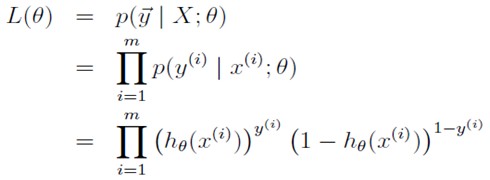
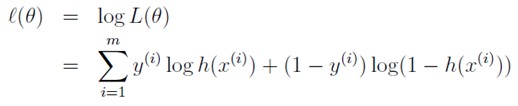
这里要求L(theta)的最大值,所以在前面添个负号就变成了求最小值,就可以用梯度下降法求解了。
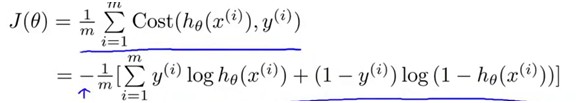
观察J的前后两项,都是单调函数,因此J是Convex函数,目标就是要最小化这个函数,因此可以用梯度下降法。


求偏导之后发现这个式子和线性回归中的那个式子的相同的,要注意的是这里的h(theta)和线性回归中的是不一样的,需要区分。这样就得到了逻辑回归的分类模型!
3.过拟合问题以及解决方法(Regularization)
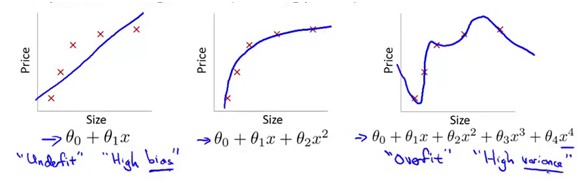
下面三个例子中,二是拟合的比较好的,一中有着较大的MSE,不是很好的模型,这种情况叫做 under fit,第三种情况虽然准确得拟合了每一个样本点,但是它的泛华能力会很差,这种情况叫做overfit。
在LogisticRegression中,上面三种情况对应的就是
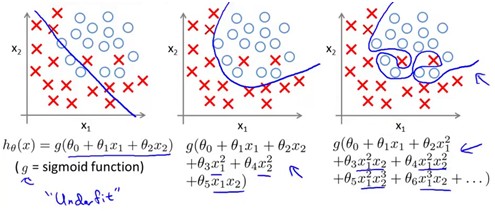
Underfit和Overfit是实践过程中需要避免的问题,那么如何避免过拟合问题呢?
第一种方法就是减少feature,上面的例子中可以减少x^2这样的多项式项。
第二种方法就是这里要介绍的Regularization,Regularization是一种可以自动减少对预测结果没有影响(或影响较小)的feature的方法。
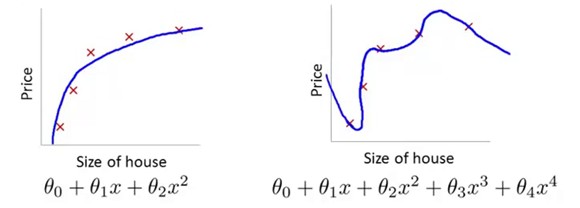
在下面这个例子中,如果我们学习得到theta3和theta4都是0或者非常接近于0,那么x的三次方项和四次方项这两个feature可以忽略,而得到的模型就是左边这个。
方法就是在原来的J后面加上惩罚项lambda*theta^2,这个例子中
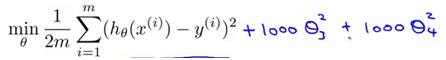
优化过程中就会使得theta3和theta4尽量小,从而加惩罚因子的这些feature对模型的影响越小。
加上lambda后面的惩罚项(regularization parameter),这样就得到了Regularization后的新的模型
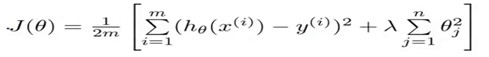
这里惩罚项式从1开始到n的,没有把0加进去,事实上,把0加进去对结果的影响非常小。
还有一个就是惩罚项系数lambda的选取问题,如果lambda选取的过大,那么最后的theta会接近于0,那么分割的曲线就会接近于直线,从而导致underfit(因为如果lambda非常非常大,要得到和前面的(h-y)相当大小的数值theta里面的所有元素就要很小),如果lambda过小,就相当于没有惩罚项,就是overfit。
求偏导后,梯度下降法中的更新式就变成了

最后还要说一下,对convex函数的优化,matlab提供了相应的优化工具,你可以把它看成是一个黑盒,你只需要把你的Cost Function和初始的theta值给他,并告诉它你需要用到什么样的优化方法,他就会帮你优化。下面是具体的使用方法:
- % Set Options
- options = optimset('GradObj', 'on', 'MaxIter', 400);
- % Optimize
- [theta, J, exit_flag] = ...
- fminunc(@(t)(costFunctionReg(t, X, y, lambda)), initial_theta, options);
设置好选项,参数t会去调用你的costfunction,并用相应的你指定的方法优化相应的迭代次数。
总结:Logistic Regression和过拟合问题的解决方法是机器学习中非常重要的方法。貌似Google的搜索广告的摆放就是用了逻辑回归算法。















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









