







 本文深入探讨了斯坦福大学机器学习课程中的逻辑回归模型,特别关注如何利用正则化技术来解决过拟合问题,以提高模型泛化能力。
本文深入探讨了斯坦福大学机器学习课程中的逻辑回归模型,特别关注如何利用正则化技术来解决过拟合问题,以提高模型泛化能力。
1.分类问题
判断一封邮件是否为垃圾邮件,判断肿瘤是良性的还是恶性的,这些都是分类问题。在分类问题中,通常输出值只有两个(一般是两类的问题,多类问题其实是两类问题的推广)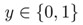 (0叫做负类,1叫做正类)。给定一组数据,标记有特征和类别,数据如(x(i),y(i)),由于输出只有两个值,如果用回归来解决会取得非常不好的效果。
(0叫做负类,1叫做正类)。给定一组数据,标记有特征和类别,数据如(x(i),y(i)),由于输出只有两个值,如果用回归来解决会取得非常不好的效果。
在良性肿瘤和恶性肿瘤的预测中,样本数据如下
上图是用线性归回得到的结果,那么可以选定一个阈值0.5,建立该模型后就可以预测:

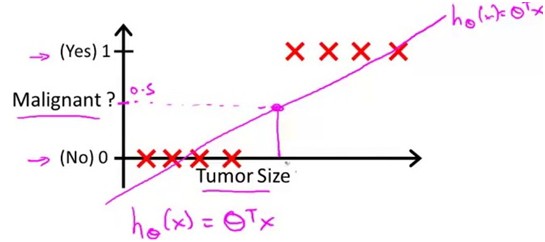
如果训练数据是这样的
很明显,这样得到的结果是非常不准确的。线性回归中,虽然我们的样本输出数据都只有0和1,但是得到的输出却可以有大于1和小于0的,这不免有点奇怪。Logistic Regission的假设就是在0和1之间的。
2.Logistic Regression
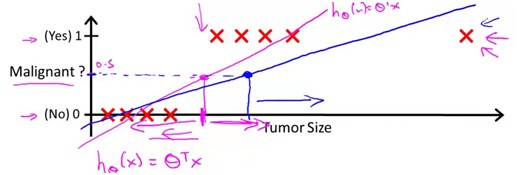
我们希望的是模型的输出值在0和1之间,逻辑回归的假设,这个假设的推导在网易公开课的广义线性模型中有提到(分类的概率满足伯努利分布),这个以后再说
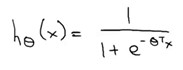
g(z)的函数图象是这样的一个S型曲线
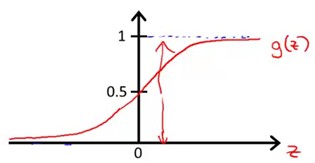
现在只要假定,预测输出为正类的概率为H (x;theta)(因为根据该曲线,H是1的时候输出刚好是1),根据概率之和为1,可以得出如下式子
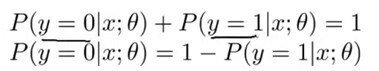
根据这个式子就可以来预测输出的分类了。和前面的线性回归一样,h(x)大于0.5的话,输出有更大的概率是正类,所以把它预测成正类。

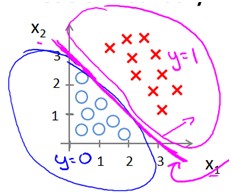
从S型曲线可以看出,h(x)是单调递增的,如果h(x)>0.5则x*theta>0反之,x*theta<0,这个反映到x的坐标下,x*theta=0刚好是一条直线,x*theta>0和x*theta<0分布在该直线的两侧,刚好可以把两类样本分开。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1140
1140











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









