






大家好,我是鸭鸭。
今天一早就被消息刷屏了。
——什么?大牛市来了?
——什么?券商系统崩了?
——什么?是上交所被买崩了?
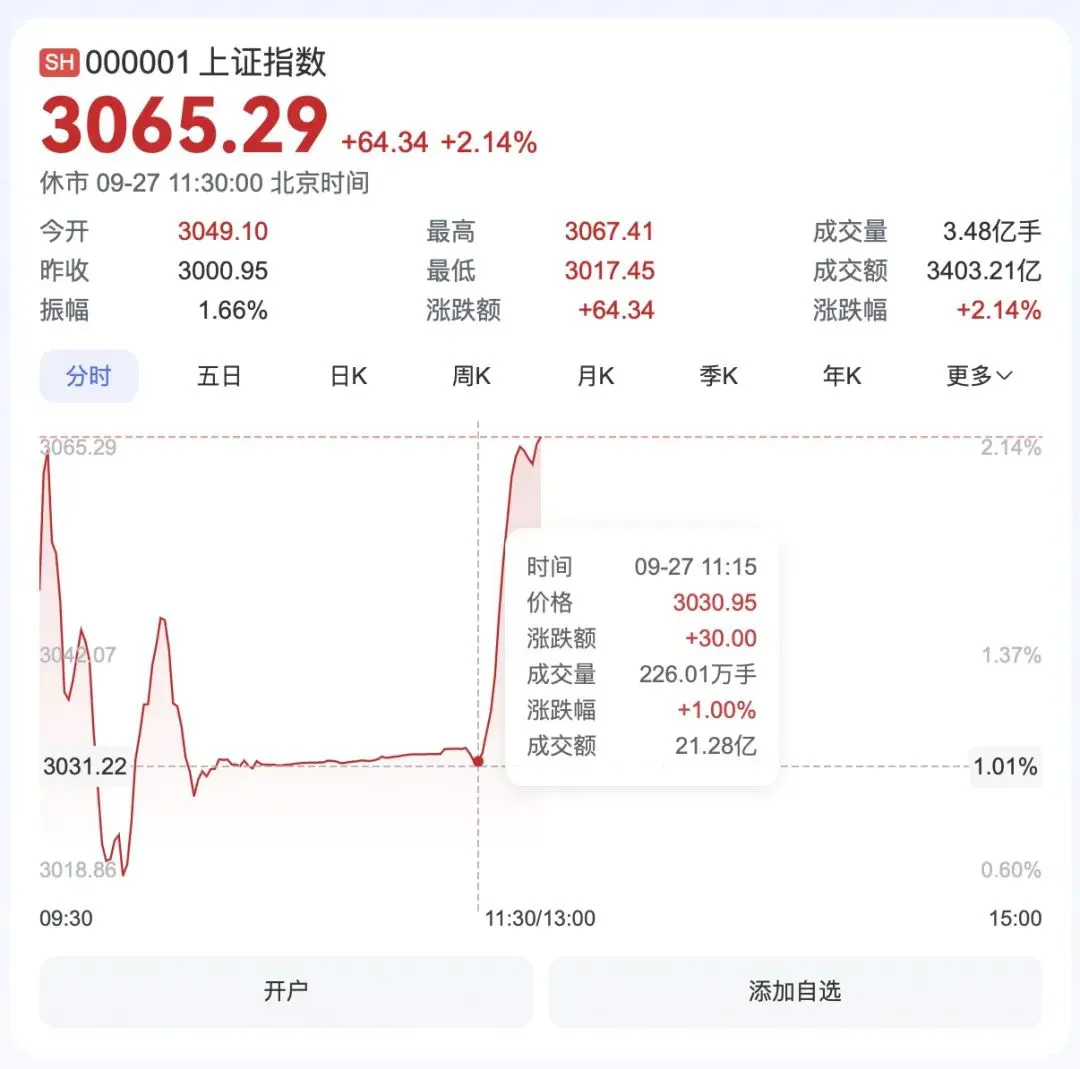
今天这一上午,A 股可以说是跌宕起伏。早上A 股三大股指大幅高开。然而正当大家激情买入的时候,上午 10 点,上证指数成交量急剧萎缩 90%以上,指数直接拉成了横线。10:22 左右,更是出现交易异常情况,成交近乎停止。疑似是系统出现故障。直到 11 点半收盘前后,上交所交易才陆续恢复正常。
有业内人士分析,这和目前市场委托量非常大有关,撤单委托可能无法及时收到明确结果,属于正常现象。
最近几天, A 股在利好的刺激下,继续高开走强,重新站上 3000 点,白酒、地产板块甚至迎来 涨停!。所以这是太多人入场买卖导致把证券系统搞崩了?
鸭鸭这算不算是见证了历史?……
为有效优化和解决这类问题,一般交易所和券商系统都会采用分布式架构,以便在高峰期间更灵活地分散请求压力。
道理是相通的,今天我们就以 Kafka 为例来看下高可用性的实现思路。
面试题:Kafka 的高可用性是如何实现的?当 Broker 宕机时,如何保证服务不受影响?
回答重点
Kafka 的高可用性主要通过以下几个关键机制来实现:
1)多副本机制(Replication):Kafka 中的每个分区都有多个副本(Replicas),这些副本分布在不同的 Broker 上。当一个 Broker 宕机时,其他持有该分区副本的 Broker 能够接管工作。
2)Leader-Follower 模式:每个分区有一个 Leader 副本和若干 Follower 副本。生产者和消费者只与 Leader 副本交互,而 Follower 副本则被用来备份数据。当 Leader 副本所在的 Broker 宕机时,一个新的 Leader 会被选举出来。
3)ZooKeeper 协调:Kafka 使用 ZooKeeper 进行分布式协调和元数据管理。当 Broker 宕机时,ZooKeeper 负责通知集群其他部分,并触发 Leader 选举过程。
当某个 Broker 宕机时,Kafka 保证服务不受影响的方式主要体现在以下几个方面:
1)自动选举新 Leader:ZooKeeper 会检测到 Broker 宕机,然后触发新 Leader 的选举过程。新的 Leader 选举出来后,继续对外提供服务。
2)数据冗余:由于存在多个副本,即使一个 Broker 宕机,其他副本仍然可以保证数据的完整性和高可用性。
3)分区再均衡(Rebalance):Kafka 会将宕机 Broker 上的分区自动重新分配到其他可用的 Broker 上,确保整个集群负载均衡。
扩展知识
为了更好地理解 Kafka 的高可用性,以下是一些相关的扩展知识点:
1)ISR(In-Sync Replicas,同步副本集):这是 Kafka 中用于维护高可用性的核心概念。ISR 是指所有与 Leader 副本保持同步的副本集合。只有在 ISR 中的副本才有可能被选为新的 Leader。
2)ACK 确认机制:Kafka 生产者在发送消息时可以指定不同的 ACK 确认机制,包括“0”表示不需要确认,“1”表示只需 Leader 确认,“-1”或“all”表示需要所有 ISR 成员确认。这种机制可以根据业务对延迟和容错的不同要求做出调整。
3)控制器(Controller):集群中会有一个指定的 Broker 作为控制器,负责管理分区的 Leader 选举和分区状态变更。控制器也是通过 ZooKeeper 选举出来的,如果控制器宕机,会由 ZooKeeper 选出新的控制器。
4)惰性故障检测:Kafka 采取惰性故障检测机制避免无谓的 Broker 重启操作。当 ZooKeeper 检测到某个 Broker 宕机时,并不会马上重新选举和再平衡,而是等待一段时间以避免因短时间内的小故障导致的频繁重选。
最后
再来推荐下我们的面试刷题网站和小程序:面试鸭 !已经有 8000+ 道面试题目啦,欢迎大家来阅读!

















 165
165

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









