







Spark线上问题引发的思考
先来简单介绍一下背景:我们使用的是公司搭建的Jupyter平台,打通了公司内部的Hadoop和Spark整套体系,用户可以使用Jupyter完成数据分析场景、算法场景(模型训练和预测)的全流程。但是最近突然有个别用户无法启动Spark,Spark在很长时间的pending资源过后,报错org.apache.spark.SparkException: Yarn application has already ended! It might have been killed or unable to launch application master
首先,简单看下日志,起初我以为是队列资源比较紧张,用户pending资源超时,导致Yarn把Spark任务kill了,于是又到队列资源平台看了下,该队列资源还是比较充足的,所以应该不是这个原因。然后又去Yarn的日志中详细看了下,在最后日志最后报错,Failed connect to application master,很明显,是无法连接到Application Master也就是AM。由于Jupyter通过Spark魔法命令(内部开发,可以方便快捷启动Spark)启动Spark使用的模式是Yarn Client模式,也就是Driver是在用户容器中的,根据报错日志,基本可以断定是Driver没连上AM,导致Spark启动超时自行kill,但是是由于什么原因导致的连接不上AM?
因为我们启动Spark使用的资源模式是Yarn,需要配置队列,而这个用户配置的队列是网络隔离的一个队列,所以第一感觉肯定是网络隔离引起的问题。但是许多其他的用户使用的也是网络隔离队列,均可以正常使用,我也反复测试了一下,但是在使用网络隔离队列有时可以连接,有时也会偶发的启动失败,貌似和网络隔离没关系(这就离谱,完全不讲道理,埋坑了😳)。
问了一下底层Yarn资源的同学,他们也只能确定就是Driver无法连接上AM的原因,再细化的原因也不太清楚了。又经过漫长的排查,在使用网络隔离队列报错机器上使用非网络隔离的队列启动Spark是可以正常启动的,在反反复复启动了几十个容器之后,基本可以确定非网络隔离的队列都可以启动Spark,使用网络隔离的队列偶发的不能启动Spark。所以感觉根本还是网络隔离出的问题,那么Spark中AM和Driver是如何通信的呢?AM是在队列容器中还是在Driver所在容器中的呢?带着两个疑问快速查阅了几本书和博客:
相关博客:
https://blog.csdn.net/baidu_35901646/article/details/81612164
https://www.jianshu.com/p/e8d806506578
https://zhuanlan.zhihu.com/p/61902619
相关书籍:
《Spark技术内幕》
《Apache Spark源码剖析》
然后简单总结了一下Spark使用Yarn资源调度器的情况下的两种架构模式
YARN Cluster模式
-
在命令行提交作业
-
YARN集群中的Resource Manager在众多Node Manager中挑一个启动Application Master,并在该节点中创建SparkContext,作为Driver节点
-
在AM(Application Master)启动后并将自己注册为一个YARN AM之后,才会开始执行用户提交的application。AM会通过YARN RM和NM的接口在集群中启动若干容器,用于启动Executor
-
成功申请到资源并启动Executor之后,Driver与Executor通过Akka应用进行消息接受和发送

YARN Driver模式
-
在命令行提交作业
-
YARN RM请求启动ApplicationMaster,但是这里的ApplicationMaster其实只是一个ExecutorLauncher,但是它的功能是很有限的
-
在AM启动后,会向RM申请container,RM分配一批container,AM连接NM,然后在NM上启动Executor,但是此时Executor并不像cluster模式那样去向AM反向注册,此时Executor会向本地的Driver机器去注册
-
成功申请到资源并启动Executor之后,Driver与Executor通过Akka应用进行消息接受和发送
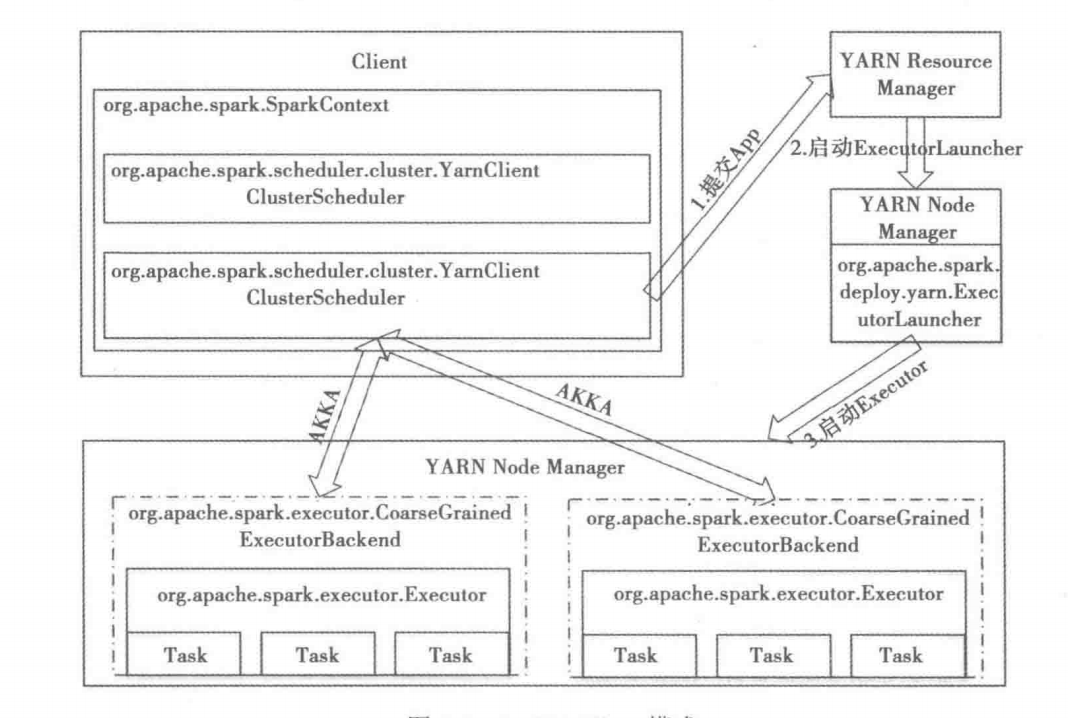
对比一下两种模式
1、yarn-client用于测试,因为driver运行在本地客户端,负责调度aplication,会与yarn集群产生大量的网络通信,从而导致网卡流量激增。好处在于,直接执行时,本地可以看到所有的log,方便调试。
2、yarn-cluster用于生产环境,因为driver运行在nodemanager,没有网卡流量激增的问题,缺点在于调试不方便,本地用spark-submit提交之后,看不到log,只能通过yarn application -logs application_id 这种命令来查看,不方便。
后续分析
所以基本可以确定AM节点就是在队列中的,也就是AM是在一个网络隔离的队列中的,Driver无法连接上AM,貌似也说的过去,那么为什么这种情况这么偶发呢?既然两者需要通信,那当然和两者都有关系,在队列层面貌似是没法发现问题了,就把问题转到用户容器层面,会不会由于个别容器所在宿主机引发的问题呢?(简直天才)又反反复复启动了十几个容器,发现了一些规律:
宿主机1 10.23.xxx.xxx 可以使用受限队列正常启动spark
宿主机2 10.22.xxx.xxx 可以使用受限队列正常启动spark
宿主机3 10.36.xxx.xxx 可以使用受限队列正常启动spark
宿主机1 10.23.xxx.xxx 可以使用受限队列正常启动spark
宿主机2 10.22.xxx.xxx 可以使用受限队列正常启动spark
宿主机3 10.36.xxx.xxx 可以使用受限队列正常启动spark
宿主机4 10.39.xxx.xxx 不可以使用受限队列正常启动spark
宿主机4 10.39.xxx.xxx 不可以使用受限队列正常启动spark
所以貌似是宿主机的原因,查询了一下网络隔离配置的iptables,发现10.39.xxx.xxx网段并没有配置iptables白名单!所以一切都说的通了,由于一开始所有宿主机比较空闲,分配到宿主机4的概率比较小,而且同时分到到宿主机4的用户需要使用网络隔离队列才会出现问题,可以说这种概率非常小了。给队列iptables添加上宿主机4的网段,再启动容器到宿主机4反复测试,均可以正常启动Spark了,一切搞定!激动!
简单总结一下,这个问题在后面复盘的时候感觉是非常好解的,一开始排查耗了很长时间的主要原因还是对Spark底层架构还有Yarn之间的通信机制不熟悉导致!所以之后还是要对底层多了解一些,排查问题时先分析问题可能引起的原因。















 1859
1859











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









