







题目:Deep Visual-Semantic Alignments for Generating Image Descriptions
- 作者:Andrej Karpathy ,Li Fei-Fei
- 论文地址[https://arxiv.org/abs/1412.2306]
1.解决的问题
- (1)用文字搜索库中图片、用图片搜索库中的文字。
- (2)对图片进行描述(Captioning)
2.方法
- 针对要解决的问题(1), 采用了 RCNN + BRNN 框架,首先将图片和文字切成片段,然后将片段图片和片段文字都映射到同一个特征空间,然后利用两个向量在同一空间的相似度来描述整张图片与一段文字的相似度,取相似度较高的结果。
- 针对要解决的问题(2), 采用了VGGNet + RNN 的框架,开始输入一张图片,然后生成一段话。
3.RCNN + BRNN
图片表示:对19个检测出的候选框(物体)外加整张图片进行卷积操作:
v=Wm[CNNθc(Ib)]+bm v = W m [ C N N θ c ( I b ) ] + b m
CNN(Ib) C N N ( I b ) 将 Ib I b 转变成4096维的向量, θc θ c 大概用6000万个参数, Wm W m 的维度是 h∗4096 h ∗ 4096 (h 在 1000-1600维之间),所以每张图片用20个 h 维的向量描述。
- 句子表示:将句子中的每个单词输入到BRNN中转成h维的向量:
- 首先用 word2vec 将单词转为300维的向量表示(实验中发现改动词向量会对在最终结果产生轻微影响)
- 然后将词向量输入BRNN中训练,实验中采用的隐藏层维度为 300 - 600 ,采用ReLU激活函数。如下图所示:

单词 与 图片候选框对应:用点乘 vtist v i t s t 代表第 i 个候选框与第 t 个单词的相似度,那么对于图片 k (包含多个候选框)和句子 l(包含多个单词)来说,相似度可以定义为:
Skl=∑tϵgl∑iϵgkmax(0,vtist) S k l = ∑ t ϵ g l ∑ i ϵ g k m a x ( 0 , v i t s t )上面的公式中 gk g k 是图片 k 的候选框集合, gl g l 是句子 l 的单词集合,意思是将所有的候选框与单词进行了笛卡尔乘积然后将所有的相似度加和,作者发现下面的公式可以用下面的公式进行简化:
Skl=∑tϵglmaxiϵgk(0,vtist) S k l = ∑ t ϵ g l m a x i ϵ g k ( 0 , v i t s t )公式的意思是说对于句子中的每一个单词,从图片集合的候选框中选取相似度最大的候选框,然后将所有的(单词—候选框)相似度加和。就是这个句子与这个图片的相似度,实验表明替换成这个公式后提升了检索效果。最后的loss定义为:
C(θ)=∑k[∑lmax(0,Skl−Skk+1)+∑lmax(0,Slk−Skk+1)] C ( θ ) = ∑ k [ ∑ l m a x ( 0 , S k l − S k k + 1 ) + ∑ l m a x ( 0 , S l k − S k k + 1 ) ]个人理解这个公式的含义是 Skk S k k 是标准的答案(相似度最大),那么 Skl−Skk S k l − S k k 则小于0,而且只选出那么相似度相差比较近的 (0-1之间)。
上一步中只是将单词与候选框进行对应,而实际中存在很多单词(句子片段)对应一个候选框的情况,作者在这里用马尔可夫夫随机场来解决这个问题。
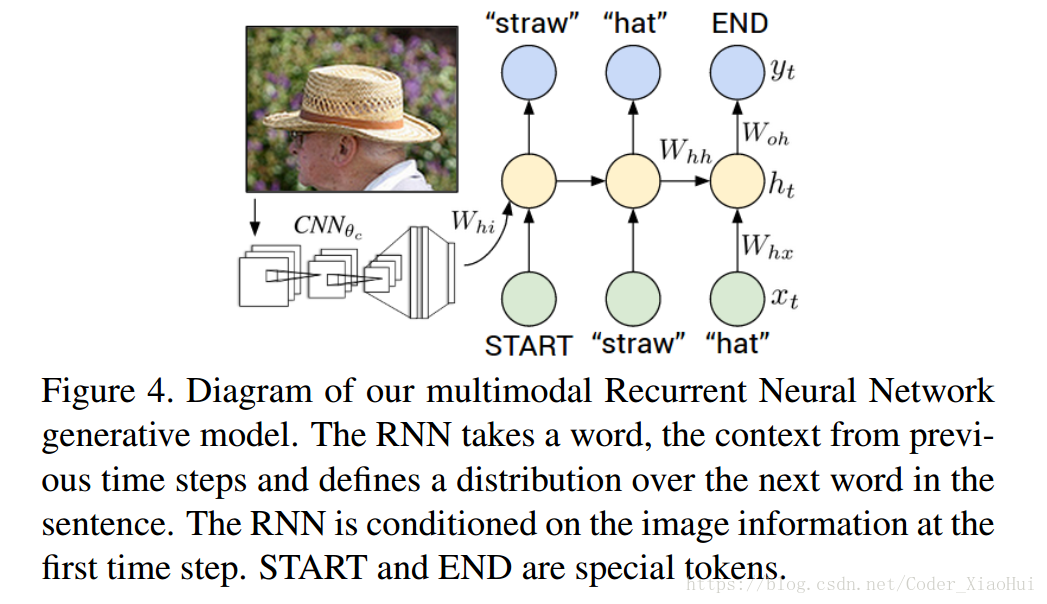
4.图片描述生成(VGGNet + RNN)
这个方法比较简单,即是用VGGNet对整张图片的特征进行抽取,然后用RNN生成语句,主要如下图所示:
要注意的是训练的时候每一时刻输入的是标准答案,测试的时候的输入是上一时刻概率最大的单词。
5.实验
用了三个数据集:Flickr8K、Flickr30K 和 MSCOCO,分别包含8000、31000、123000张图片,每张图片都有五句描述。对于Flickr8K 和 Flickr30K 采用1000张图片作为验证集,1000张图片作为测试集。对于MSCOCO采用5000张图片作为验证集,5000张作为测试集。
预处理:将所有句子转为小写,然后选取出现不少于五次的单词,对于三个数据集分别得到 2538,7414,8791个单词。
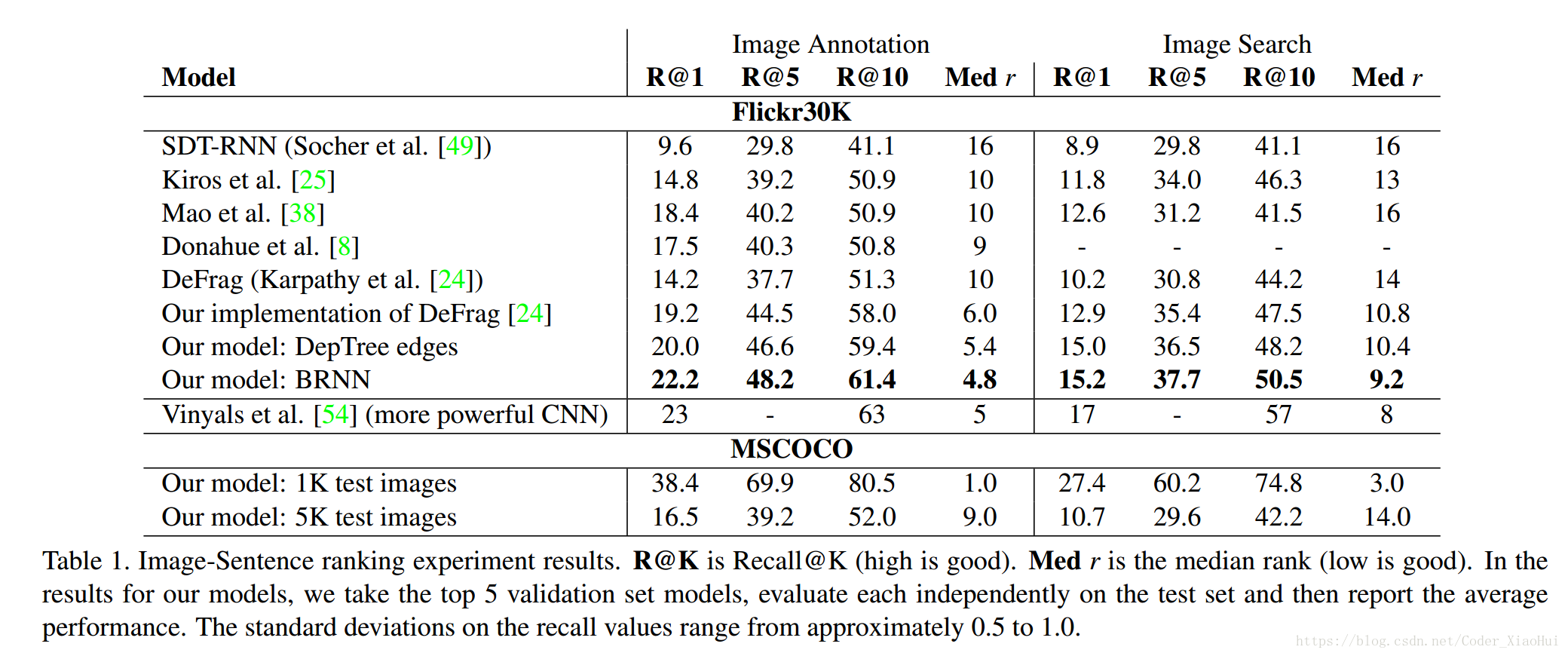
用图片搜句子和用句子搜图片得到的结果是:
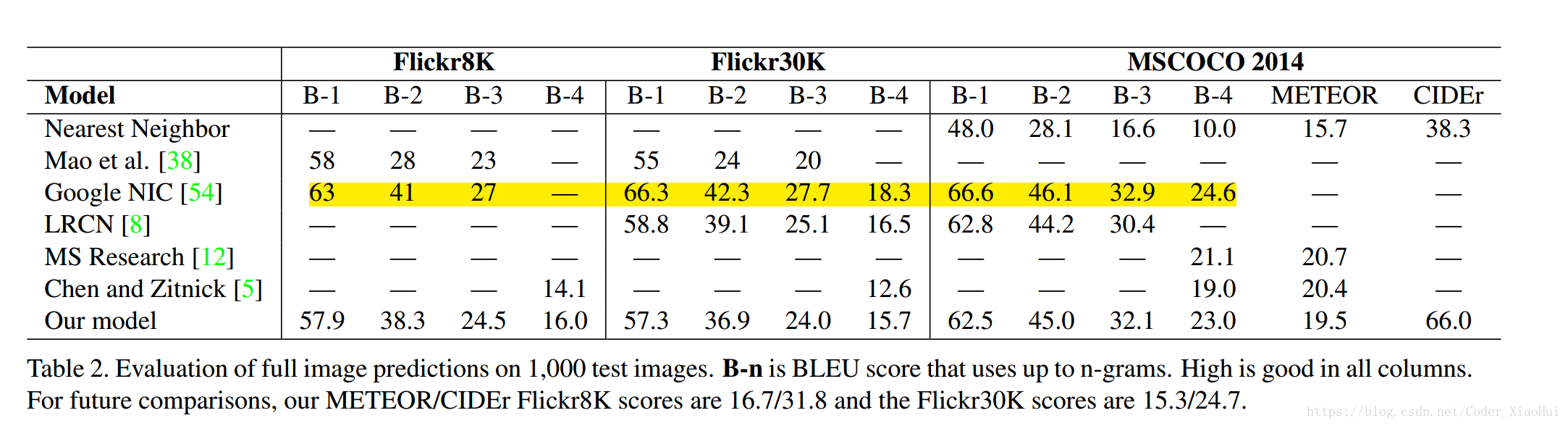
图片描述的结果是:
6.思考
- 扫描图片,确定实体,然后描述实体间的交互关系是不是更好一些
- RNN接受到图片信息是通过加法直接传入RNN的,会不会有更复杂抽象的关系比如乘法等效果会更好
- 现在的模型是两个模型分开的,如何设计端到端的模型。














 2300
2300











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









