







AlexNet
(新手入门,如理解有误感谢指正)
论文地址
AlexNet是2012年ILSVRC的第一名
它的整体框架如图1所示:

首先整体概括一下AlexNet主要用到的一些技术方法:
- 使用ReLU作为非线性激活函数而非以往的sigmoid或tanh
- 采用了模型并行,将网络按照feature maps的深度一分为二放在两个GPU上训练
- 使用了Local Response Normalization(LRN)局部归一化
- 使用了重叠的池化层
- 防止过拟合采用了数据增强(Data Augmentation)和丢弃法(Dropout)
总共8层网络5层是卷积层,3层是全连接层,下面就按照图1逐层分析一下
卷积层特征图输出尺寸计算公式:
M = N − F + 2 P S + 1 M = \frac{N-F+2P}{S} + 1 M=SN−F+2P+1
其中N是输入的尺寸,即 N × N N\times N N×N的输入,F是卷积核的尺寸,即 F × F F\times F F×F的卷积核,P是padding,S是stride步长
Input:
3 × 224 × 224 3\times 224\times 224 3×224×224的图片(C, H, W)
第一层:
1. 卷积层
卷积核个数96个
卷积核尺寸 3 × 11 × 11 3\times 11\times 11 3×11×11
步长S为4
无padding
输出feature maps的尺寸根据公式 224 − 11 + 0 4 + 1 ≈ 55 \frac{224-11+0}{4}+1\approx 55 4224−11+0+1≈55,所以最终的尺寸应为 96 × 55 × 55 96\times 55 \times 55 96×55×55。
由于使用模型并行,这里按照深度一份为二,放在两个GPU上训练,那么每个GPU上的输出feature maps的尺寸为 96 2 × 55 × 55 = 48 × 55 × 55 \frac{96}{2}\times55\times55 = 48\times55\times 55 296×55×55=48×55×55
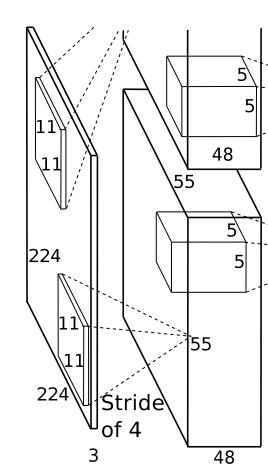
图2
2. ReLU
经过ReLU进行激活
f
(
x
)
=
m
a
x
(
0
,
x
)
f(x) = max(0, x)
f(x)=max(0,x)
论文实验表明使用ReLU模型收敛更快

3. Max Pooling
采样核的尺寸是 3 × 3 3\times3 3×3
论文采用重叠Pooling,使用步长S为2
这样采样后的feature maps尺寸根据公式 55 − 3 + 0 2 + 1 = 27 \frac{55-3+0}{2}+1=27 255−3+0+1=27,由于这一步操作是在各个GPU上独立操作,所以每个GPU上输出的feature maps尺寸均为 48 × 27 × 27 48\times27\times27 48×27×27
4. LRN归一化
采用下面这个公式进行归一化
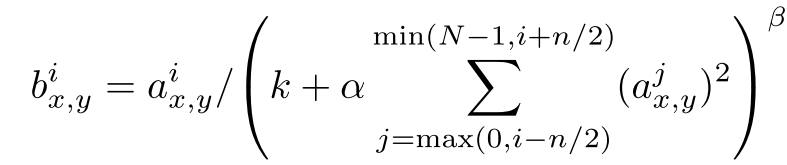
简单来说就是上一步经过池化层后得到了feature maps,每个深度每个位置的值用
a
x
,
y
i
a_{x,y}^i
ax,yi表示,也就是i深度(x, y)位置的值,然后经过公式处理,这个位置的值
a
x
,
y
i
a_{x,y}^i
ax,yi变成了
b
x
,
y
i
b_{x,y}^i
bx,yi
我们具体看一下过程是怎样的,
k
,
α
,
β
,
n
k, \alpha, \beta, n
k,α,β,n是常数,是需要调的超参数,i,j就代表深度,n就是相邻的n个深度,N是总的深度

图4
所以要计算 a x , y i a_{x,y}^i ax,yi的归一化值实际上就是先把和它挨着的若干个深度相同位置的值(蓝色方格)求个平方加起来乘一个系数 α \alpha α再加一个系数k,再求 β \beta β次方,最后用 a x , y i a_{x,y}^i ax,yi除以算出的这个数
最终论文中选取 k = 2 , n = 5 , α = 1 0 − 4 , β = 0.75 k=2, n=5, \alpha=10^{-4}, \beta=0.75 k=2,n=5,α=10−4,β=0.75
第二层:
1.卷积层
卷积核个数 256
卷积核尺寸 48 × 5 × 5 48\times5\times5 48×5×5
padding为2,步长S为1
这一层依然是再各个GPU上独立运算,所以256个卷积核实际分成了两部分,每个GPU上各128个卷积核
这样两个GPU上输出的feature maps尺寸为
27
−
5
+
2
×
2
1
+
1
=
27
\frac{27-5+2\times2}{1}+1=27
127−5+2×2+1=27,注意上一层最后经过max pooling后的尺寸是
48
×
27
×
27
48\times27\times27
48×27×27,这样输出的尺寸每个GPU上均为
128
×
27
×
27
128\times27\times27
128×27×27

图5
2. ReLU
3. Max Pooling
采样核的尺寸是 3 × 3 3\times3 3×3
论文采用重叠Pooling,使用步长S为2
这样采样后的feature maps尺寸根据公式 27 − 3 + 0 2 + 1 = 13 \frac{27-3+0}{2}+1=13 227−3+0+1=13,由于这一步操作是在各个GPU上独立操作,所以每个GPU上输出的feature maps尺寸均为 128 × 13 × 13 128\times13\times13 128×13×13
4. LRN归一化
尺寸不变
第三层:
第三层比较有意思,前两层都是在各自GPU上单独运算,第三层则在两个GPU之间进行了运算,即进行了信息的交互
1. 卷积层
卷积核个数384
卷积核尺寸 256 × 3 × 3 256\times 3\times 3 256×3×3
步长S为1,padding为1

图6
如图6我们可以知道,每个卷积核的深度256实际上是相当于把上一层两个GPU上的 128 × 13 × 13 128\times13\times13 128×13×13合在一起了,即 256 × 13 × 13 256\times13\times13 256×13×13的输入,为啥是13,图上是27,别忘了上一层经过max pooling了
这样我们计算输出feature maps的尺寸 13 − 3 + 2 1 + 1 = 13 \frac{13-3+2}{1}+1=13 113−3+2+1=13,所以输出的尺寸为 384 × 13 × 13 384\times13\times13 384×13×13,然后我们再按照深度一分为二放到两个GPU,每个GPU的输出feature maps尺寸就变成图上的 192 × 13 × 13 192\times13\times13 192×13×13
2. ReLU
ReLU激活
第四层:
第四层和第一第二层一样,也是单独再各自GPU上独立运算
1. 卷积层
卷积核个数384,每个GPU上192个
卷积核尺寸 192 × 3 × 3 192\times3\times3 192×3×3
padding为1,步长S为1
输出尺寸 13 − 3 + 2 1 + 1 = 13 \frac{13-3+2}{1}+1=13 113−3+2+1=13,每个GPU上的feature maps尺寸仍为 384 2 × 13 × 13 = 192 × 3 × 3 \frac{384}{2}\times13\times13=192\times3\times3 2384×13×13=192×3×3
2. ReLU
ReLU激活

图7
第五层:
1. 卷积层
卷积核个数256,每个GPU上128个
卷积核尺寸 192 × 3 × 3 192\times3\times3 192×3×3
步长padding均为1
输出尺寸 13 − 3 + 2 1 + 1 = 13 \frac{13-3+2}{1}+1=13 113−3+2+1=13,每个GPU上的输出feature maps尺寸为 128 × 13 × 13 128\times13\times13 128×13×13
2. ReLU
ReLU激活

图8
3. Max Pooling
采样核的尺寸是 3 × 3 3\times3 3×3
论文采用重叠Pooling,使用步长S为2
这样采样后的feature maps尺寸根据公式 13 − 3 + 0 2 + 1 = 6 \frac{13-3+0}{2}+1=6 213−3+0+1=6,由于这一步操作是在各个GPU上独立操作,所以每个GPU上输出的feature maps尺寸均为 128 × 6 × 6 128\times6\times6 128×6×6,总共是 256 × 6 × 6 256\times6\times6 256×6×6
第六层:
从这一层开始到最后均为全连接层,从这里开始不再是每个GPU上单独运算,GPU之间也会进行全连接
1. 全连接层
共4096个神经元,每个GPU上2048个,和上一层 256 × 6 × 6 256\times6\times6 256×6×6个节点全连接
2. ReLU
3. Dropout
简单理解就是随机将激活后的节点输出值置为0,这样这些节点在本轮训练中将不再参与后面的前向传播和梯度回传,这样使得输出值不会严重依赖于某些节点和权重,使得学习更加均衡,避免过拟合
第七层:
1. 全连接层
共4096个神经元,每个GPU上2048个,和上一层4096个节点全连接
2. ReLU
3. Dropout
第八层:
1. 全连接层
共1000个神经元,即1000个输出,和上一层4096个节点全连接
2. softmax
计算预测类别的概率分布

图9
下面使用pytorch实现一个简化的AlexNet,代码来源于李沐的动手学习深度学习的pytorch开源版本
该版本的AlexNet没有使用LRN归一化,在2015年Very Deep Convolutional Networks for Large-Scale Image Recognition. 这篇文章中提到LRN基本没什么用
 图10
图10
PyTorch Code:
import time
import torch
from torch import nn, optim
import torchvision
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
class AlexNet(nn.Module):
def __init__(self):
super(AlexNet, self).__init__()
self.conv = nn.Sequential(
# 这里不再使用模型并行将网络按照深度拆分,而是一个整体
# 第一层
nn.Conv2d(1, 96, 11, 4), # in_channels, out_channels, kernel_size, stride, padding
nn.ReLU(),
nn.MaxPool2d(3, 2), # kernel_size, stride
# 第二层
nn.Conv2d(96, 256, 5, 1, 2),
nn.ReLU(),
nn.MaxPool2d(3, 2),
# 第三层
nn.Conv2d(256, 384, 3, 1, 1),
nn.ReLU(),
# 第四层
nn.Conv2d(384, 384, 3, 1, 1),
nn.ReLU(),
# 第五层
nn.Conv2d(384, 256, 3, 1, 1),
nn.ReLU(),
nn.MaxPool2d(3, 2),
)
# 全连接层
self.fc = nn.Sequential(
# 根据上面的讲解这里按照论文中的应该是256*6*6
# 但是我们在看论文中会发现第一层的卷积层计算出的尺寸实际上是54.25不能整除
# 论文按55计算了,所以到了最后是256*6*6
# 而pytorch应该是向下取整了,这里如果写256*6*6会出现size mismatch错误
nn.Linear(256*5*5, 4096),
nn.ReLU(),
nn.Dropout(0.5),
nn.Linear(4096, 4096),
nn.ReLU(),
nn.Dropout(0.5),
# 输出层。由于这里使用Fashion-MNIST,所以用类别数为10,而非论文中的1000
nn.Linear(4096, 10),
)
def forward(self, img):
feature = self.conv(img)
print(feature.shape)
output = self.fc(feature.view(img.shape[0], -1))
return output















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









