







【上一篇 4 动态编程(Dynamic Programming, DP)】
【下一篇 6 Temporal-Difference (TD) Learning 】
与上一节动态编程(DP)方法不同的是,蒙特卡洛(Monte Carlo, MC)方法不需要环境的全部信息,而只需要 “experience”,这里的“experience”指的是 states、actions和环境的 rewards 的采样序列。在机器学习领域,不需要环境动态性的先验知识是非常重要的一个优点,蒙特卡洛方法从真实的或者仿真的 experience 中进行学习,虽然它也需要一个环境模型用来产生样本转换,但它不像动态编程一样需要所有可能转换的所有概率分布。蒙特卡洛方法主要是通过对样本的 returns 进行平均来解决增强学习问题的,有点类似于 Multi-armed bandit 的机制。
1 Monte Carlo Prediction
基于一个给定的规则,蒙特卡洛方法学习 state-value 函数的方法是将所有 “visit” 过该状态的经历中的 returns 进行平均,假设给定一个服从规则 π \pi π 的 episodes 集合,在一个 episode 中每次处于在状态 s 就称为是对状态 s 的一次 visit,每个 episode 中第一次处于状态 s 就称为是 First Visit to s。
MC 中的预测方法可以分成两种:first-visit MC 与 every-visit MC,其中 first-visit MC 方法是将 v π ( s ) v_{\pi}(s) vπ(s) 评估为 s 的所有 first visits 的平均值,而 every-visit MC 方法是将 v π ( s ) v_{\pi}(s) vπ(s) 评估为 s 的所有 visits 的平均值,这两种方法非常相似只具有微微不同的理论属性,当 s 被 visit 的次数趋于无穷时,这两种方法都会收敛到 v π ( s ) v_{\pi}(s) vπ(s)。first-visit MC 的伪代码如下图所示,其每个返回值是一个独立的、对 v π ( s ) v_{\pi}(s) vπ(s) 的相同的分布估计,并且带有有限的方差,每个平均值本身都是一个无偏估计,误差的标准偏差为 1 n \frac{1}{\sqrt{n}} n1 (其中 n n n 为 returns 的数量),这个估计可以说是成平方收敛的(converge quadratically)。

蒙特卡洛夫方法估计 v π ( s ) v_{\pi}(s) vπ(s) 的 backup diagram 如下所示,从中可以看出,MC 方法的每一次 experience,都是从一个初始状态(即根节点)开始,沿着某个特定 episode 的转变轨迹遍历每一个经历过的节点,最终以终止状态结束。针对某一个节点,MC 方法只包含该特定 episode 选择的 action 的转换,而 DP 方法会将所有可能的转换都包含在内。从全局上来看,MC 方法包含了一个 episode 经历的所有转换,而 DP 方法只包含一步转换过程。
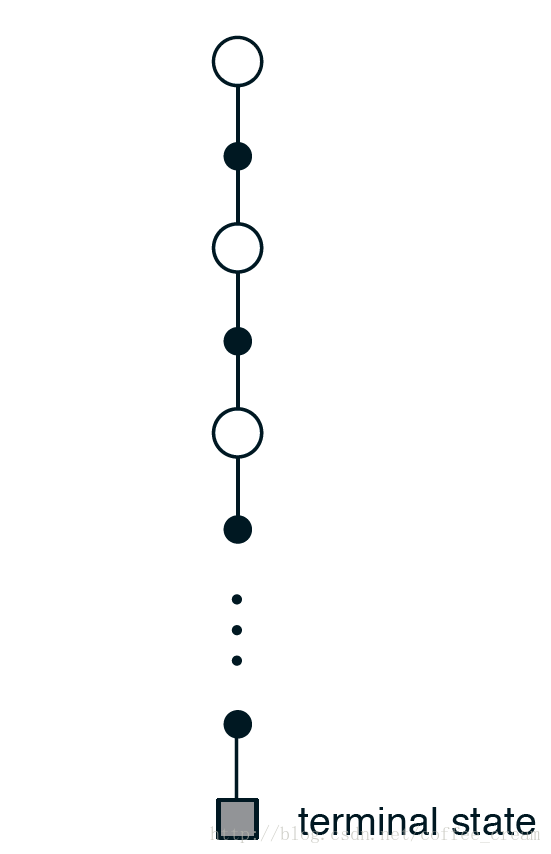
MP 方法的一个重要属性在于,它对每一个状态的估计是独立的,不依赖于对其他状态的估计。并且,MP 方法估计每一单一状态的 value 的计算成本是与状态的数量无关的,这从它的伪代码中也可以看出,它只需要希望计算的状态的 returns,而不需要计算的状态就可以忽略掉。
2 Monte Carlo Estimation of Action Values
当有模型时,只需要 state values 就可以确定一个规则,这时只需要选择会引向最好的 reward 和 下一个状态的 action 即可,但是在没有模型的时候,单单具有 state values 是不足确定一个规则的,这时就需要明确地知道每个 action values。因此,当模型未知时,获得 action values (state-action 对的价值)比 state values 更重要,因此蒙特卡洛的一个重要目标就是评估 q ∗ q_{\ast} q∗。
要评估 q ∗ q_{\ast} q∗,首先应该考虑的是 action value 的规则评价问题,也就是估计 q π ( s , a ) q_{\pi}(s,a) qπ(s,a)(在状态 s s s 下执行行为 a a a 的期望 return),MC 方法估计 q ∗ q_{\ast} q∗ 的思想与估计 state values 是一样的,在一个 episode 中,一对 s , a s,a s,a 称为是被 visit 过只的是在该 episode 中,agent 经历过 s s s 状态且选择执行了行为 a a a。
同样,这里的 MC 预测方法也可以分成两种:first-visit MC 与 every-visit MC,其中 first-visit MC 方法是对 ( s , a ) (s,a) (s,a)的所有 first visits 进行平均,而 every-visit MC 方法是对 ( s , a ) (s,a) (s,a) 的所有 visits 进行平均。当 visit 的次数趋于无穷时,这些方法也是成平方收敛的。
这里唯一复杂的地方在于,有可能有很多 state-action 对从未被 visit 过,这样就没有 returns 来进行平均,就无法对该 state-action 对进行评估,这其实就可以归结于是一般的 Maintaining Exploration 问题,也就是在指导 agent 的行为时要保持一定的探索精神。其中一种解决方法是 Exploring Starts,不明思议,该方法就是通过每一个 episode 的起点来做到 exploration 的,也就是每一对 State-Action Pair 都会以非零的概率被选中作为 episode 的起点,exploring starts 方法有时有用,但不具有一般性,很多时候受问题或者环境的约束无法实现,另外一种可行的方法是采用一种随机的规则,对每个状态所有的行为被选中的概率都是非零的。下一节内容中暂且假设采用的是 exploring starts 方案。
3 Monte Carlo Control
在 DP 方法中我们知道,将 policy evaluation 与 policy improvement 相结合就构成了 policy iteration 过程,这里先回顾一下 DP 的 policy iteration 过程:
π 0 → E v π 0 → I π 1 → E v π 1 → I π 2 → E ⋯ → I π ∗ → E v π ∗ \pi_0 \xrightarrow{E} v_{\pi_0} \xrightarrow{I} \pi_1 \xrightarrow{E} v_{\pi_1} \xrightarrow{I} \pi_2 \xrightarrow{E} \cdots \xrightarrow{I} \pi_{\ast} \xrightarrow{E} v_{\pi_{\ast}} π0Evπ0Iπ1Evπ1Iπ2E⋯Iπ∗Evπ∗
而在 MC 中,policy iteration 过程是这样的:
π 0 → E q π 0 → I π 1 → E q π 1 → I π 2 → E ⋯ → I π ∗ → E q π ∗ \pi_0 \xrightarrow{E} q_{\pi_0} \xrightarrow{I} \pi_1 \xrightarrow{E} q_{\pi_1} \xrightarrow{I} \pi_2 \xrightarrow{E} \cdots \xrightarrow{I} \pi_{\ast} \xrightarrow{E} q_{\pi_{\ast}} π
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 181
181

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









