






爬取百度图片表情包
案例目的:
通过爬取百度图片表情包,介绍对url中加密数据的解析。
代码功能:
通过输入爬取的页数,自动将每页的表情包图片下载到本地。
1.输入要所搜所的内容(表情包):

2.得到响应数据(响应数据含有图片url的url)
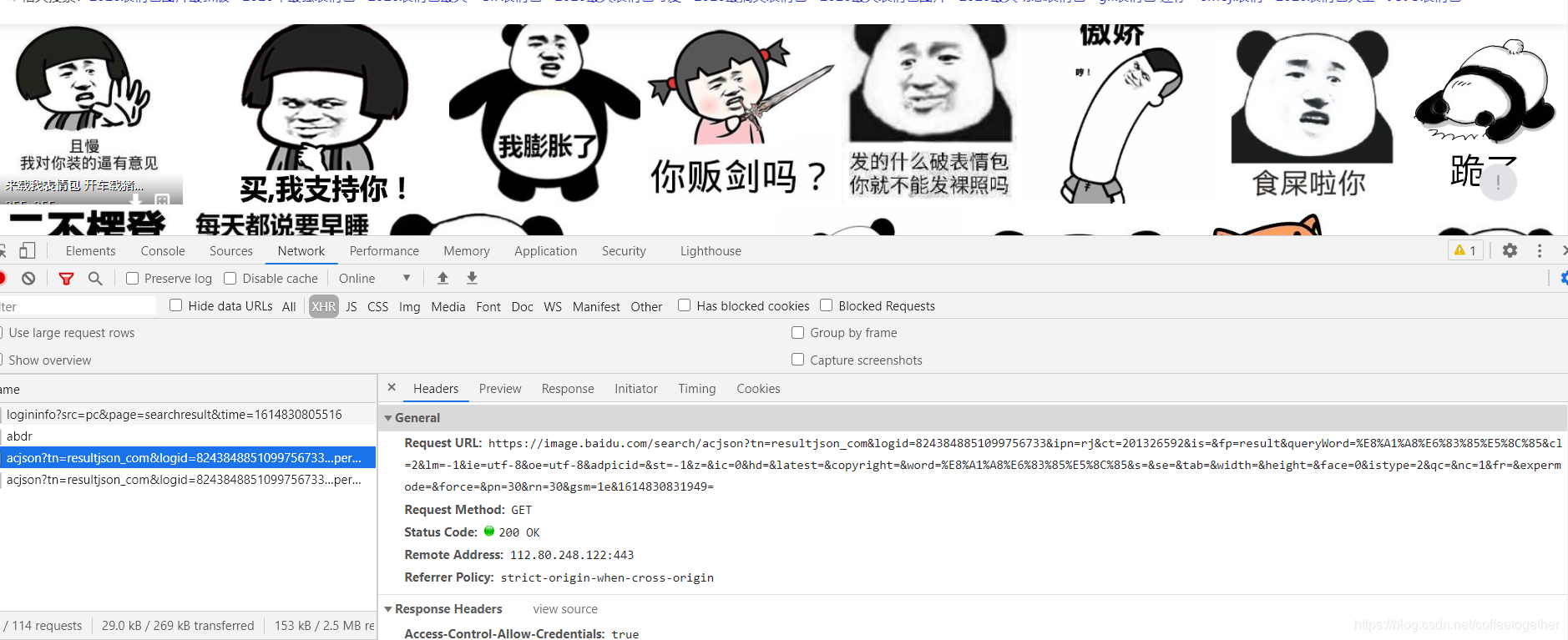
3.检查响应数据
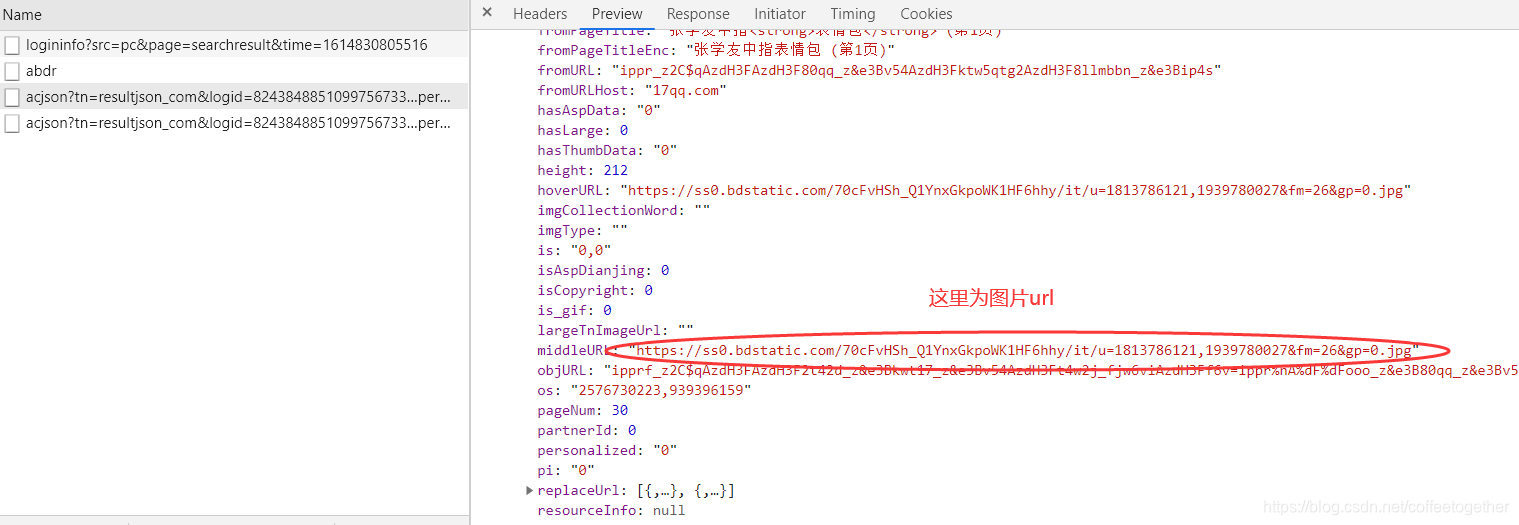
4.对每个图片的url发送请求,获取响应数据(表情包图片)
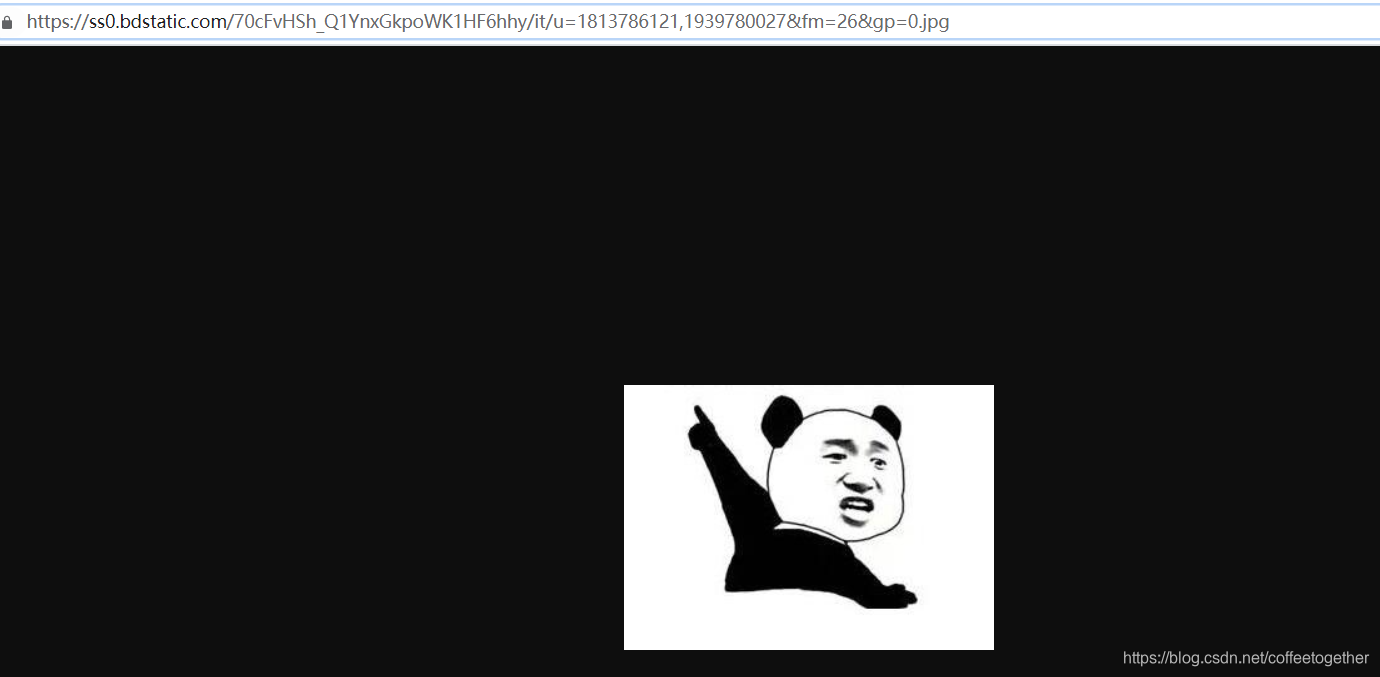
5.将图片保存到本地
6.(重点在于)找到翻页url的规律:
不同页url的url如下:



对比前三页的url可知:不同页url的规律在于:
参数一:pn
参数二:gsm
参数三:最后"="前面的数字
参数分析:
1.参数一pn:第一页的pn参数为30,第二页为60,第三页为90,因此pn参数的规律为页数n*30。
2.参数二gsm:经过分析发现,gsm参数为参数pn的16进制数。
3.参数三:根据参数的格式可知,为以毫秒为单位的时间戳。
将参数格式化放进url中,如下图:


7.找到url图片对应的jsonpath语法:
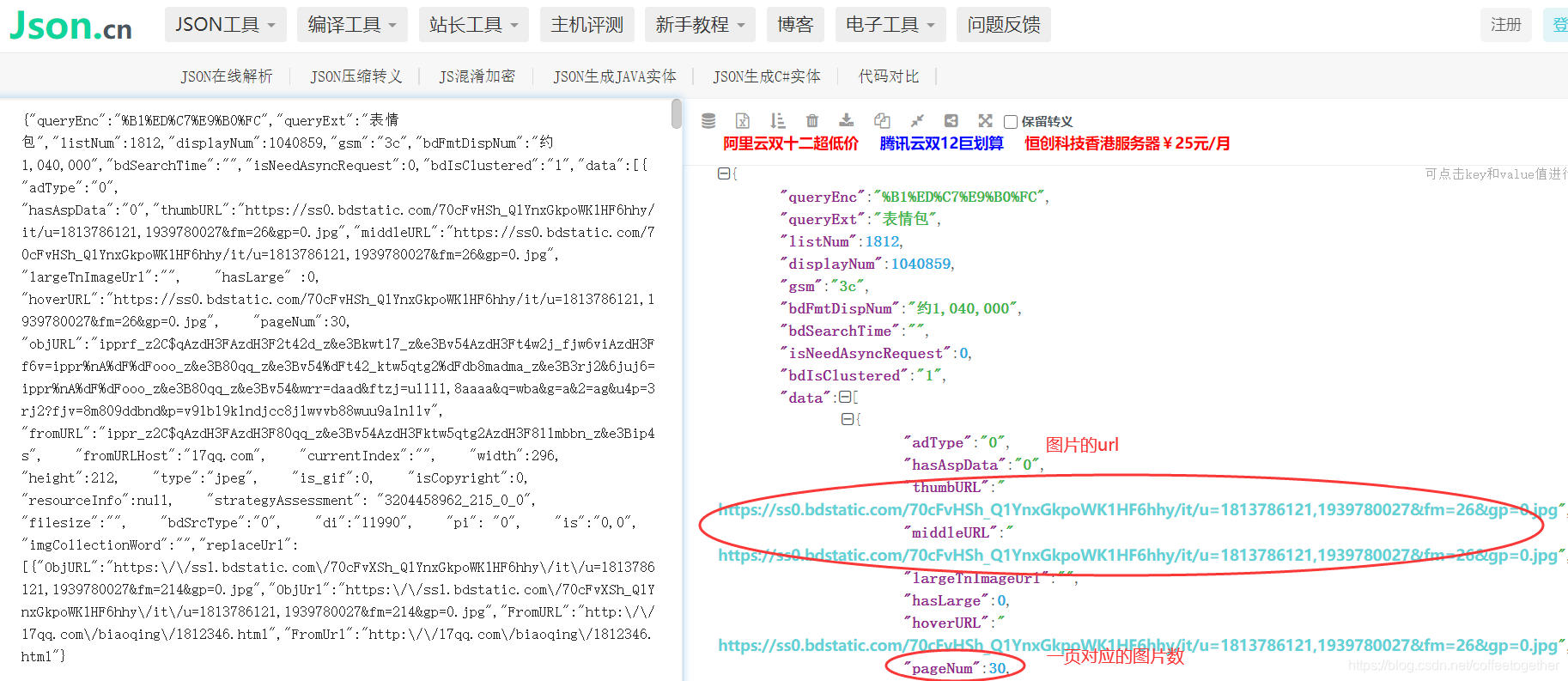
解析完毕,开始代码:
import requests
import time
import jsonpath
if __name__ == '__main__':
pages = int(input('请输入要爬取的页数:'))
for i in range(pages):
pn = (i+1)*30
# 确认图片页面的url
url = f'https://image.baidu.com/search/acjson?tn=resultjson_com&ipn=rj&ct=201326592&is=&fp=result&queryWord=%E8%A1%A8%E6%83%85%E5%8C%85&cl=2&lm=-1&ie=utf-8&oe=utf-8&adpicid=&st=-1&z=&ic=0&hd=&latest=©right=&word=%E8%A1%A8%E6%83%85%E5%8C%85&s=&se=&tab=&width=&height=&face=0&istype=2&qc=&nc=1&fr=&expermode=&force=&pn={pn}&rn=30&gsm={str(hex(pn))[-2:]}&{str(int(time.time())*1000)}='
# 创建请求头参数
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.104 Safari/537.36'
}
# 发送请求获取响应
response = requests.get(url,headers=headers)
# 判断数据类型(为json类型)
py_data = response.json()
# 提取数据中图片的url
img_url = jsonpath.jsonpath(py_data,'$.data[*].middleURL')
print(len(img_url))
for i in py_data['data']:
if i:
img_url = i['middleURL']
response1 = requests.get(img_url,headers=headers)
bytes_data = response1.content
# 保存数据
with open(f'表情包.{int(time.time()*1000)}.jpg','wb')as f:
f.write(bytes_data)
爬取了两页
执行结果如下:
注:图片数量比较多,因此为了避免重复,我们将表情包+时间戳作为图片的名称。




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











