







前言
几次面试下来,优化算法被问到的频率非常的高,所以在这里简单记录一个常见优化算法的特点。因自己对AI领域的了解还不是很深,只能浅浅地记录一下
BGD
批量梯度下降,Batch gradient descent
训练集较小( m ≤ 2000 m \leq 2000 m≤2000),直接使用批量梯度下降
SGD
随机梯度下降,Stochastic gradient descent
这里的“随机”指的是对样本进行随机采样
SGD由于每次只选取了一个样本,失去了用动量进行加速的机会
MBGD
小批量梯度下降,mini-batch gradient descent
综合了批量梯度下降和随机梯度下降的优点,适合处理大型数据集
- mini-batch size = m时,为批量梯度下降
- mini-batch size = 1时,为随机梯度下降
该算法每次只处理一个小批量样例,而不是处理一个完整的训练集。比如现在有500万条数据,就可以将它划分成5000个批次,每个批次有1000个样例
mini-batch size通常设置为2的幂数
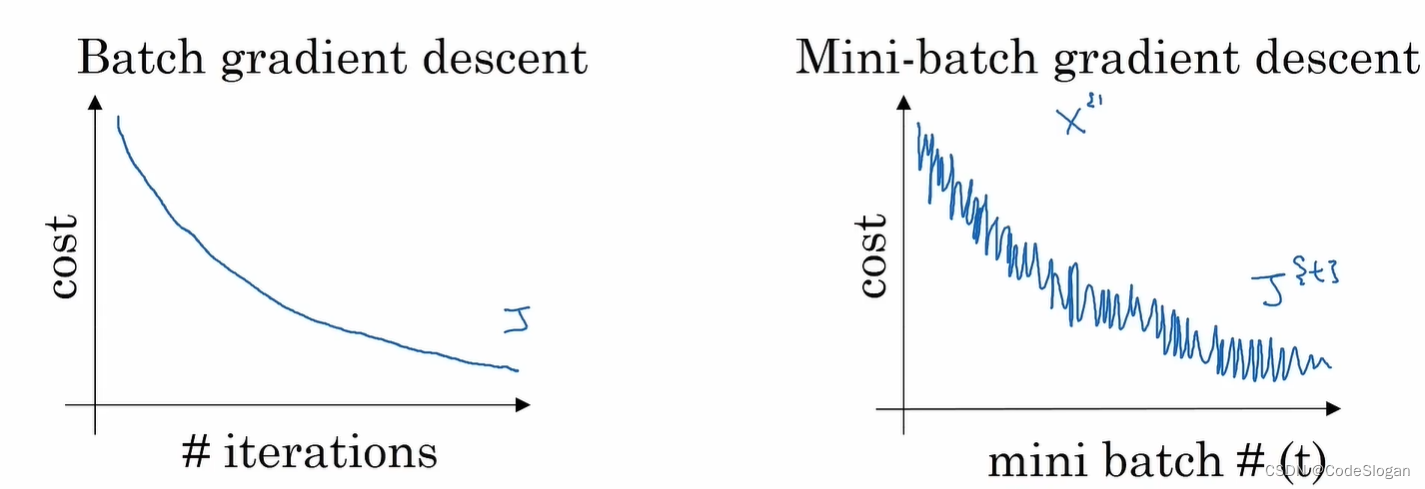
好处:
- 向量处理。如每个批次有1000个样例,可以用一个向量同时处理这1000个样本
- 不用等待整个数据集都训练完后,才运行梯度下降。如上述例子,每遍历完一次训练集,可以执行5000次梯度下降算法
- 相比SGD,更一致地朝着最小值的方向前进,不会总在最小值附近摆动
Momentum
动量梯度下降
计算梯度的指数加权平均,然后利用梯度来更新权重
v d W = β v d W + ( 1 − β ) d W v_{dW}=\beta v_{dW}+(1-\beta)dW vdW=βvdW+(1−β)dW
v d b = β v d b + ( 1 − β ) d b v_{db}=\beta v_{db}+(1-\beta)db vdb=βvdb+(1−β)db
W = W − α v d W , b = b − α v d b W=W-\alpha v_{dW},b=b-\alpha v_{db} W=W−αvdW,b=b−αvdb
RMSprop
均方根传播,Root Mean Square prop
基于权重梯度最近量级的均值为每一个参数适应性地保留学习率。这意味着算法在非稳态和在线问题上有很有优秀的性能
Adagrad
适应性梯度算法(AdaGrad)为每一个参数保留一个学习率以提升在稀疏梯度(即自然语言和计算机视觉问题)上的性能
Adam
适应性矩估计
是动量和RMSProp的结合
- α \alpha α:学习率
- β 1 \beta_1 β1:0.9, d W dW dW代表这个导数的平均值(第一阶矩)
- β 2 \beta_2 β2:0.999, d W 2 dW^2 dW2用于计算平均数的指数加权平均(第二阶矩)
- ϵ \epsilon ϵ: 1 0 − 8 10^{-8} 10−8
优势:
- 实现简单,计算高效,所需内存小
- 梯度对角缩放的不变性
- 超参数可以直观解释,仅需要极少量的调参
与传统SGD的区别:
- SGD保持单一的学习率更新所有的权重,学习率在训练过程中不会发生改变
- Adam通过计算梯度的一阶矩估计和二阶矩估计而为不同的参数设计独立的自适应学习率

















 4万+
4万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











