







1.模型优缺点比较:

2.信息熵:
信息熵是信息的期望值,描述信息的不确定度。一个系统越是有序,信息熵就越低;反之,一个系统越是混乱,它的信息熵就越高。
计算公式:
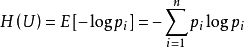
3.信息增益:
表示得知特征X的信息而使得类Y的信息的不确定性减少的程度
计算公式:
infoGain = baseEntropy - EntropyAfter
当infoGain > 0 ,表明集合信息熵减小,包含的信息更纯更有序,价值得到提高。
当infoGain < 0,信息变得混沌。
当infoGain = 0,信息量没有变化,但不表明信息没有变化。
4.混淆矩阵
真阳性(True Positive,TP):样本的真实类别是正例,并且模型预测的结果也是正例
真阴性(True Negative,TN):样本的真实类别是负例,并且模型将其预测成为负例
假阳性(False Positive,FP):样本的真实类别是负例,但是模型将其预测成为正例
假阴性(False Negative,FN):样本的真实类别是正例,但是模型将其预测成为负例
from sklearn.metrics import confusion_matrix
confusion_matrix = confusion_matrix(y_test, y_predict)

准确率(accuracy):预测正确的结果占总样本的百分比
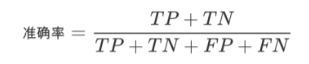
召回率(recall):在实际为正的样本中被预测为正样本的概率
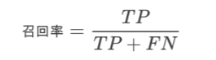
精准率(precision):
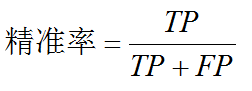
F1值(调和平均值):
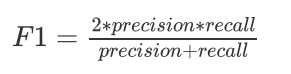
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score
print('准确率:', accuracy_score(y_test, y_hat))
print('精确率:', precision_score(y_test, y_hat))
print('召回率:', recall_score(y_test, y_hat))
print('F1调和平均值:', f1_score(y_test, y_hat))
print('score方法计算正确率:',lr.score(x_test, y_test))














 548
548











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









