







python中的解码和编码
转载:https://www.cnblogs.com/shine-lee/p/4504559.html
在python中,编码解码其实是不同编码系统间的转换,默认情况下,转换目标是Unicode,即编码unicode→str,解码str→unicode,其中str指的是字节流
而str.decode是将字节流str按给定的解码方式解码,并转换成utf-8形式,u.encode是将unicode类按给定的编码方式转换成字节流str
注意调用encode方法的是unicode对象生成的是字节流,调用decode方法的是str对象(
字节流
)生成的是unicode对象,若str对象调用encode会默认先按系统默认编码方式decode成unicode对象再encode,忽视了中间默认的decode往往导致报错
自己写代码时只需记住str字节流调用decode,unicode对象调用
|
1
2
3
|
s
=
u
'严'
s
print
type
(s), s
|
第二行会输出u'\u4e25'
第三行输出<type 'unicode'> 严
|
1
2
3
|
u
=
s.encode(
'utf8'
)
u
print
type
(u),u
|
倘若这时我用s.encode('utf8'),则将s使用utf-8编码并将编码结果保存为字节流
第二行输出'\xe4\xb8\xa5'
第三行输出
<type 'str'> 涓
还有要注意的是,终端默认的编码格式是gbk,
windows cmd中可以通过chcp查看以及改变,也可以到注册表修改终端默认编码(
HKEY_CURRENT_USER console或者powershell下的codepage),936为简体中文,65001为utf8,两者都可显示中文,但为了方便中文输入,我将其默认设为936
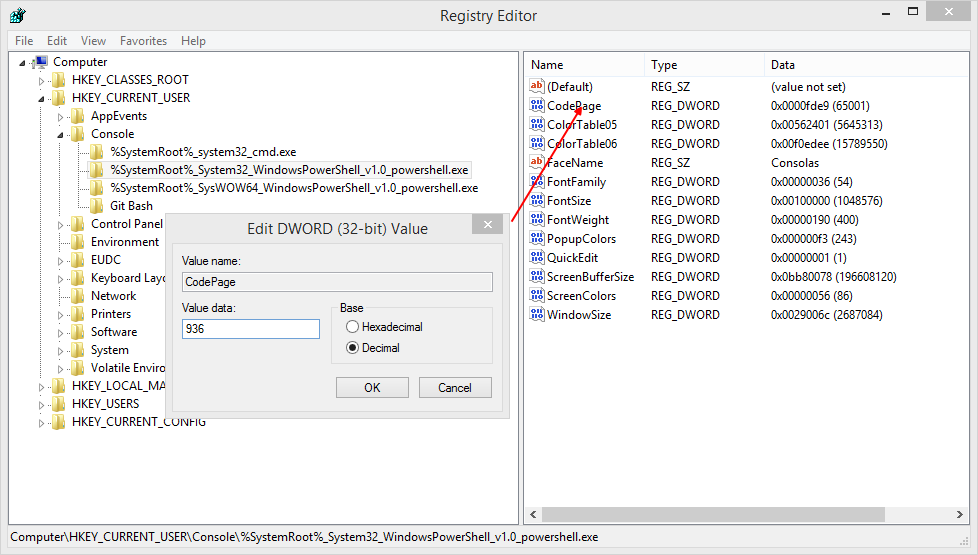
当调用print函数将内容格式化输出到终端时,会将unicode对象转换为终端的编码方式输出,如上面第一次print的结果是正常的,print utf8字节流时,终端按其默认gbk解码显示时就会出问题,这里恰巧'\xe4\xb8'为gbk下的“涓”
|
1
2
|
t
=
s.encode(
'utf8'
).decode(
'utf8'
)
t
|
文件的编码格式
保存文本时也有编码格式,比如txt文件保存可选择则ASCII、utf8等,对py文件可在
前两行注明编码方式# -*- coding: UTF-8 -*-
在python中读取文件
|
1
2
|
fr
=
open
(
'encode.py'
,
'r'
)
fstr
=
fr.read()
|
只要记住fstr
是字节流,其他的操作参看上面即可
注:以上操作均在cmd或powershell下完成,在python自带的解释器下会有问题,s=u'你好',然后s,显示的虽然是unicode对象,但是编码却是gbk的而不是unicode















 751
751

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









