






补充
- 结构体的定义
- 1)先定义结构体类型,在定义结构体类型的变量
struct stutype
{
int num;
char name[20];
char sex;
int age;
float score;
char addr[30];
};
struct stutype s1,s2; /*定义了s1和s2两个变量,为struct stutype类型的变量*/
这种方式是声明类型和定义变量分离,在声明类型后可以随时定义变量,比较灵活
- 在定义结构体类型的同时定义结构体类型的变量
struct stutype
{
int num;
char name[20];
char sex;
int age;
float score;
char addr[30];
}s1,s2; /*定义了s1和s2两个变量,为struct stutype类型的变量*/
这种方式适合于定义局部使用的结构体类型或结构体类型变量,如在一个文件内部或函数内部。
- 直接定义结构体类型的变量
struct
{
int num;
char name[20];
char sex;
int age;
float score;
char addr[30];
}s1,s2;
适合于临时定义局部变量或结构体成员变量。
2.指向结构体变量的指针
1)一个指针变量当用来指向一个结构体变量时,称之为结构体指针变量。结构体指针变量中的值是所指向的结构体型变量的首地址。
2)结构体指针变量说明的一般形式为
struct 结构体名 * 结构体指针变量名;
3)其访问的一般形式为:
结构体变量名.成员名
或为:
结构指针变量->成员名
3.typedef类型定义符
1)其访问的一般形式为:
结构体变量名.成员名
或为:
结构指针变量->成员名
2)作用是定义了别名STU表示结构体类型struct student,然后可用STU来定义结构体类型变量:
STU s1,s2; 等价于 struct student s1,s2;
- 动态存储分配
1)分配内存空间函数malloc
调用形式:
(类型说明符*)malloc(size)
功能:在内存的动态存储区中分配一块长度为“size”字节的连续区域。函数的返回值为该区域的首地址。
如:p=(char *)malloc(100);
表示分配100个字节的内存空间,并强制转换为字符数组类型,函数的返回值为指向该字符数组的指针,把该指针赋予指针变量p。
2)释放内存空间函数free
调用形式:
free(void *p);
功能:释放p所指向的一块内存空间,p是一个任意类型的指针变量,它指向被释放区域的首地址。被释放区域应是由malloc函数所分配的区域。
绪论
基本概念和术语
1.数据:是所有能被输入到计算机中,且能被计算机处理的符号的集合,它是计算机操作的对象的总称
2.数据元素(结点/记录):是数据的一个个体,是数据的基本单位
3.数据项(域/字段):是组成数据元素的、有独立含义的、不可分割的最小单位
4.数据对象:是具有相同性质的若干个数据元素的集合
5.数据结构:是相互之间存在着某种特定的关系的数据元素的集合
6.数据的逻辑结构:由数据元素之间的逻辑关系构成,是数据元素间抽象化的相互关系,与数据的存储无关,独立于计算机,它是从具体问题抽象出来的数学模型
7.数据的存储(物理)结构:数据元素及其关系在计算机存储器中的存储方式
数据的逻辑结构
逻辑结构:数据元素之间的逻辑关系,一个逻辑结构包括数据元素和关系两个要素,可用二元组描述 G=(D,R),G 表示数据逻辑结构的名称,D表示数据元素的有限集合,R表示D上所有元素之间的关系的有限集合
1.集合结构:{1 8 6 0 3}
2.线性结构:数据元素之间存在一对一的关系,集合中的元素除了开始结点和终端结点之外,其余结点都有且仅有一个直接前驱结点和一个直接后继结点
尖括号表示数据元素的关系是有向的
3.树形结构:数据元素之间存在一对多的关系,除了起始结点以外,各个结点都有唯一的直接前驱结点,所有结点都有0个到多个直接后继结点,树形结构能反映出结点之间的层次关系,有向的箭头体现了结点之间的从属关系
4.图形结构:每个结点都有多个直接前驱结点和多个直接后继结点
圆括号表示数据元素之间的关系是无向的
5.非线性结构:把数据元素之间存在“一对多”关系的树形结构和数据元素之间存在多对多关系的图形结构,包括树、二叉树、有向图、无向图
6.线性结构:线性表、栈和队、字符串、数组、广义表、
数据的存储结构
数据的存储结构:数据元素及其关系在计算机存储器中的表示,也称数据的物理结构
数据元素在计算机中主要有以下四种存储结构:
1.顺序存储结构:借助元素在存储器中的相对位置来表示数据元素之间的逻辑关系,它是把逻辑上相邻的结点存储在物理位置相邻的存储单元里,结点间的逻辑关系由存储单元的邻接关系来体现
2.链式存储结构:借助指示元素存储地址的指针来表示数据元素之间的逻辑关系,不要求逻辑上的相邻节点再物理位置上相邻,结点之间的关系由附加的指针域来表示
3.索引存储结构:除了需要建立存储节点信息外,还需要建立附加的索引表,表中的每一项都有关键字(能唯一标识一个节点的数据项)和地址组成,索引表反映了所有结点信息按某一个关键字递增或递减排列的逻辑次序,采用索引存储结构主要作用是为了提高数据的检索速度
4.散列(或哈希)存储结构:散列技术是一种将数据元素的存储位置与关键字之间建立确定对应关系的查找技术,散列技术除了用于查找外,还可用于存储;散列存储结构是通过构造散列函数来确定数据存储地址,散列存储结构的内存存放形式称为散列表,也称哈希表
数据类型和数据抽象类型
1.数据类型:是高级程序设计语言中的基本概念,每一个数据都属于一个数据类型;类型明显或隐含地规定了数据的取值范围、存储方式以及允许进行的运算
2.抽象数据类型:是指由用户定义的、表示应用问题的数据模型,以及定义在此数学模型上的一组操作的总称。包括三部分:数据对象、数据对象上的关系的集合以及对数据对象的基本操作的集合。抽象数据类型不考虑计算机具体存储结构,也不考虑运算的具体实现算法
抽象数据类型=逻辑结构+抽象运算
算法和算法分析方法
1.算法:数据元素之间的关系有逻辑关系和物理关系,对应的操作有逻辑结构上的操作功能和具体存储结构上的操作实现。通常把具体存储结构上的操作实现步骤或过程称为算法。
算法也是对特定问题求解步骤的一种描述,是指令的有限序列。其中每一条指令表示一个或多个操作
2.算法的五个特性:
1)有穷性:算法应在执行有穷步后结束,且每一步在有穷时间内完成
2)确定性:每步定义都是确切、无二义的
3)可行性:可通过基本运算有限次执行来实现
4)有输入
5)有输出
3.算法设计的目标
1)正确性:要求算法能够正确地执行预先规定的功能和性能要求。这是最重要也是最基本的标准。
2)可使用性:要求算法能够很方便地使用。这个特性也叫做用户友好性。
3)可读性:算法应该易于人的理解,也就是可读性好。为了达到这个要求,算法的逻辑必须是清晰的、简单的和结构化的。
4)健壮性:要求算法具有很好的容错性,即提供异常处理,能够对不合理的数据进行检查。不经常出现异常中断或死机现象。
5)高效性:通常算法的效率主要指算法的执行时间。对于同一个问题如果有多种算法可以求解,执行时间短的算法效率高。算法存储量指的是算法执行过程中所需的最大存储空间。效率和低存储量这两者都与问题的规模有关。
4.算法的时间复杂度
1)算法执行的时间需依据该算法编制的程序在计算机上的执行时间来度量
2)事后统计法:需要先将算法实现,然后测算其时间和空间开销。这种方法需将算法转换成可执行的程序,时空开销且依赖计算机算硬件等环境因素。
缺点:
1.必须先运行依据算法编制的程序
2.所得时间统计量依赖于硬件、软件等环境因素,掩盖算法本身的优劣
3)事前分析估算法:
一个高级语言程序在计算机上运行所消耗的时间取决于:
算法选用何种策略
问题的规模
程序语言
编译程序产生机器代码质量
机器执行指令速度
影响算法时间代价的最主要因素是问题规模,一个算法的执行时间大致上等于所有语句执行的时间总和。
特例:


最好、最坏和平均时间复杂度分析

各种不同数量级对应的值存在着如下关系:
O(1)<O(log2n)<O(n)<O(nlog2n)<O(n2)<O(n3)<O(2n)<O(n!)
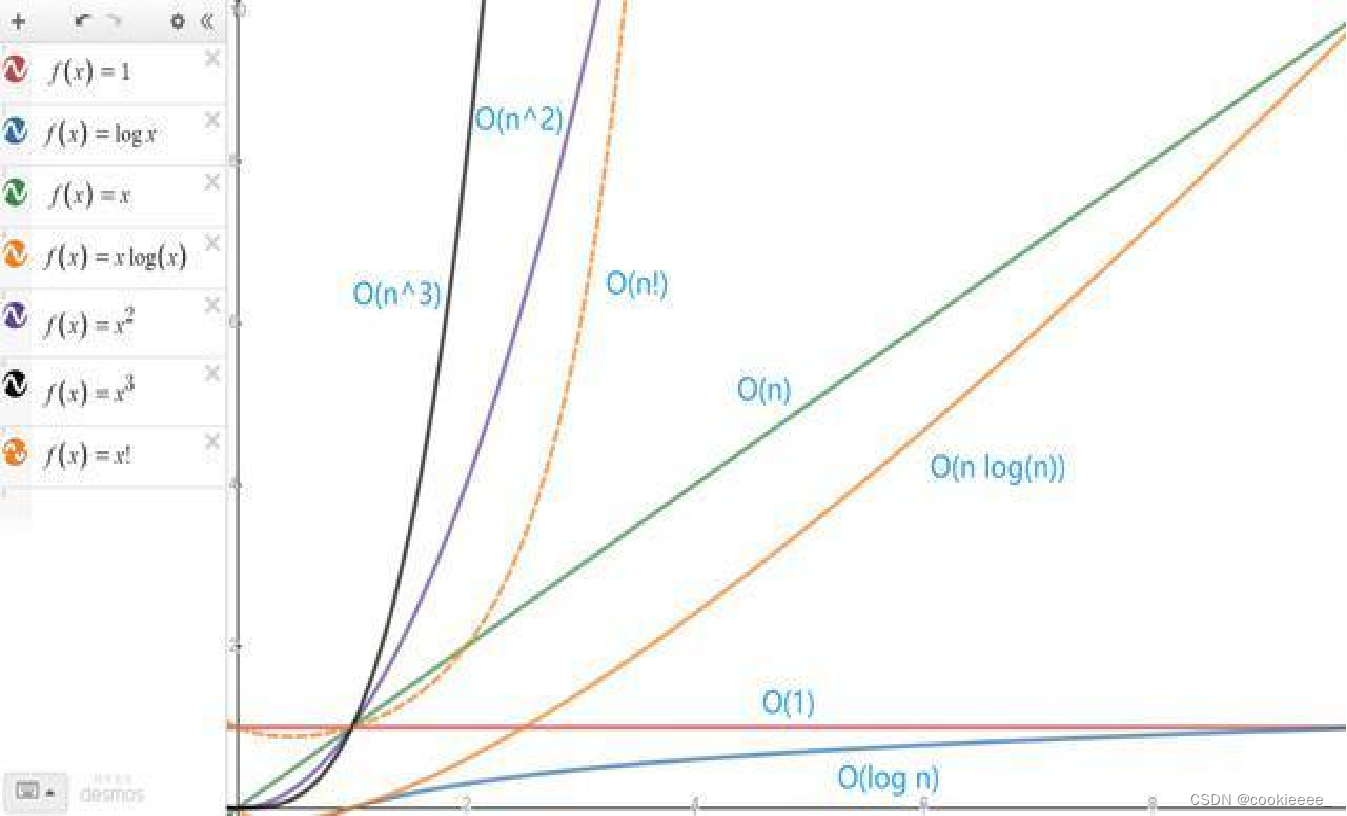
空间复杂度

错题:记录是数据处理的最小单位 ❌ 数据项是最小单位
程序一定是算法、算法不一定是程序
线性表
线性表的定义
1. 线性表是一种线性数据结构,其特点是数据元素之间存在“一对一”的关系。
2.一个线性表是n个类型相同数据元素的有限序列,每个数据元素的具体含义在不同的情况下可以不同,甚至其他更复杂的信息
记录、文件:
在一个复杂的线性表种,一个数据元素可以由若干个数据项组成,常把数据元素称为记录,含有大量记录的线性表又称文件
逻辑位序
3.ai表示最后一个数据元素,ai表示第i个数据元素,称i为数据元素ai的逻辑位序
线性二元组:

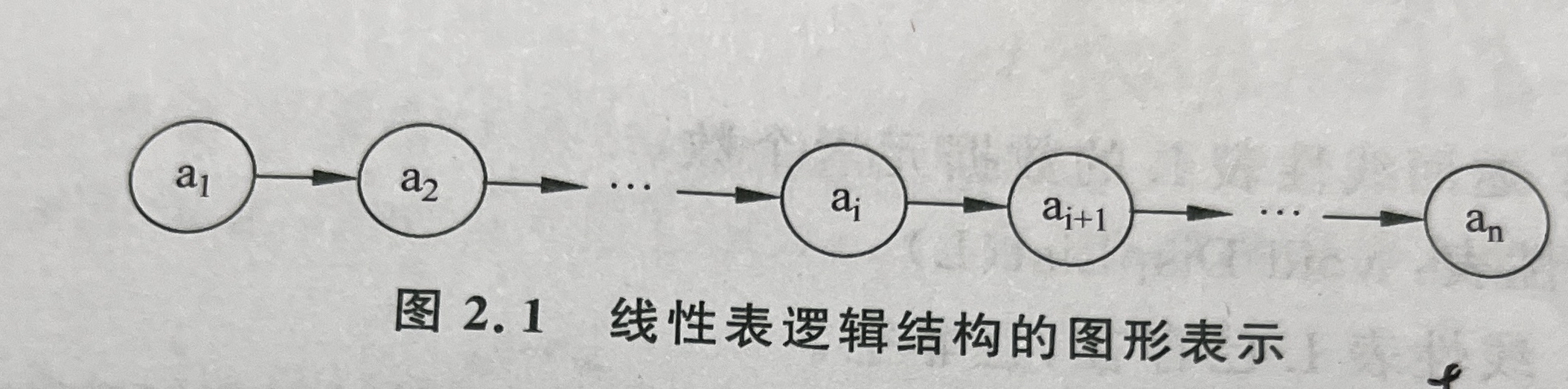
顺序表
顺序表位置计算
1.顺序表用数组存储,其特点是线性表中相邻元素ai和ai+1存储在相邻存储位置LOC(ai)和LOC(ai+1中,即逻辑顺序和物理顺序是一致的)
2.设线性表中每个元素需占用d个存储单元,并以所占第一个单元的存储地址作为数据元素的存储地址,则第i个数据元素的地址为:LOC(ai)=LOC(a1)+(i-1)*d (1<=i<n)
顺序表示意图
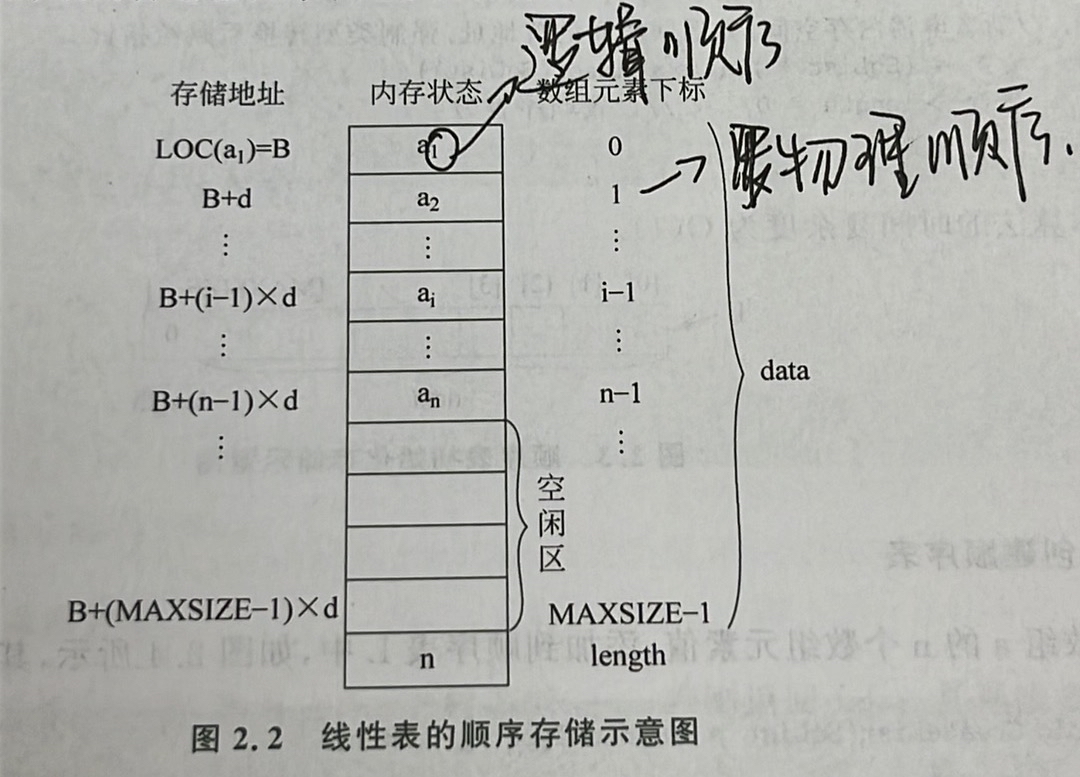
插入删除操作平均移动次数
1.进行插入操作时,则所需平均移动次数为:n/2(下面有详解)
2.进行删除操作时,则所需平均移动次数为:(n-1)/2
4.插入元素: 1)检查插入位置的有效性,插入位置 i 的有效的范围是:1<=i<=L->length+1
2)时间复杂度分析:从算法可知,在顺序表中某个位置上插人一个数据元素时,其时间主要消耗在移动元素上,而移动元素的个数取决于插人元素的位置。
3.假设P,是在第i个位置上插入新元素的概率,则在长度为n的线性表中插人一个元素
所需平均移动次数为:

顺序表缺点
1)对顺序表做插入或删除操作时,需要移动大量的数据元素,影响运行效率
2)顺序表预分配空间时,必须按最大空间分配,存储空间可能得不到充分利用
3)对于某些高级语言来说,顺序表的容量难以扩充
顺序表的实现
//顺序表各种操作的实现
#include<stdio.h>
#include<stdlib.h>
#define maxsize 50
typedef int ElemType;
typedef struct
{
ElemType data[maxsize]; //存放顺序表元素
int length; //保存顺序表的长度
} SqList;
void InitList(SqList *&L) //SqList *&L和SqList *L的区别
{
L=(SqList*)malloc(sizeof(SqList));
L->length=0;
}
void CreatList(SqList *&L,ElemType a[],int n) //建立顺序表
{
int i;
for(i=0;i<n;i++) //将数组a的n个数组元素值,添加到顺序表L中
{
L->data[i]=a[i];
L->length++; //顺序表长度加1
}
}
int ListLength(SqList *L) //求长度
{
return L->length;
}
void DispList(SqList *L) //输出顺序表
{
int i;
for(i=0;i<=L->length-1;i++)
{
printf("%4d",L->data[i]); //将顺序表L中实际包含的数据元素一次打印出来
}
printf("\n");
}
bool ListEmpty(SqList *L) //判断顺序表是否为空
{
return (L->length==0);
}
bool GetElem(SqList *L,int i,ElemType &e) //按位置查找顺序表
{
if(i<1||i>L->length) //先判断要查找的位序是否合法
return false;
else
{
e=L->data[i-1];
return true;
}
}
int LocateElem(SqList *L,ElemType e) //按值查找顺序表
{
int i=0;
while(i<L->length && L->data[i]!=e) //循环遍历顺序表的data数组同时i既作为循环条件
i++;
if(i>=L->length)
return 0;
else
return i+1; //又记录了找到后该值的位序(转成逻辑编号)
}
int InsertElem(SqList *&L,ElemType e)
int main()
{
int i,n=10;
SqList *p;
ElemType a[10]={1,2,3,4,5,6,7,8,9,0};
do
{
printf("~~~~~~~~~~~~~~~~~~~~~~~~~\n");
printf(" 主菜单 \n");
printf(" 1.初始化顺序表 \n");
printf(" 2.创建顺序表 \n");
printf(" 3.顺序表长度 \n");
printf(" 4.输出顺序表 \n");
printf(" 5.判断是否为空 \n");
printf(" 6.按位置查找元素 \n");
printf(" 7.按值查找元素 \n");
printf(" 8.插入元素 \n");
printf(" 9.删除元素 \n");
printf(" 10.销毁顺序表 \n");
printf(" 0.退出 \n");
printf("~~~~~~~~~~~~~~~~~~~~~~~~~\n");
printf("请输入一个想要的操作:\n");
scanf("%d",&i);
switch(i)
{
case 1:InitList(p);
break;
case 2:CreatList(p,a,n);
break;
case 3:r=ListLength(p);
printf("长度为%d\n",r);
break;
case 4:DispList(p);
break;
case 5:re=ListEmpty(p);
if(re==true)
printf("是空表\n");
else
printf("不是空表\n");
break;
case 6: printf("请输入要查找的位置\n");
scanf("%d",&w);
re=GetElem(p,w,e);
if(re==true)
printf("该位置的数是%d\n",e);
else
printf("错误,请重新输入\n",e);
break;
case 7:printf("请输入要查找的元素值\n");
scanf("%d",&w);
r=LocateElem(p,w);
if(r==0)
printf("错误,请重新输入\n",e);
else
printf("该元素在第%d个\n",r);
break;
}
}while(1);
return 0;
}单链表
是由若干结点构成的;单列表的结点只有一个指针域
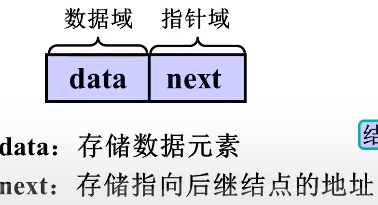
存储特点:
1. 逻辑次序和物理次序不一定相同
2.元素之间的逻辑关系用指针表示
3.使用链表时,往往关心的时节点间的逻辑顺序,对每个结点的实际地址并不关心

Node是struct node的别名,Link是指向struct的一个指针类型
p=(Link)malloc(sizeof(Node));malloc语句分配存储空间,让p指向这个存储空间
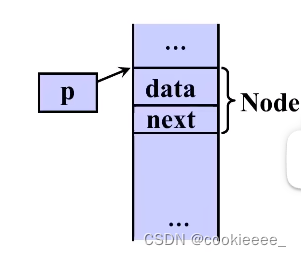
typedef
如何引用数据元素
引用上图
(*p).data==p->data(引用p所指向的data域的数据)
如何引用指针域
p->next
什么是存储结构
真正的存储结构是零散的、不连续的
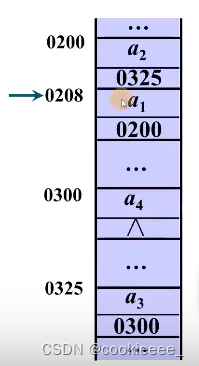
为了能让存储结构更好的理解,一般情况下画成如下的图
链表示意图
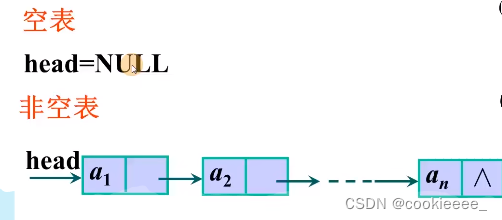
头指针:指向第一个结点的地址
尾标志:终端结点的指针域为空
这两者缺一不可
1.创建一个单链表(将数组录入单链表中)
1)头插法
头结点:在单链表的第一个元素结点之前附设一个类型相同的结点,以便空表和非空表处理统一,且头节点的数据域可以不存储任何信息,也可以存储如线性表的长度等数据信息
由于单链表中每个结点占用的存储空间不是预先分配的,而是运行时系统根据需要生成的
void CreateListF(LinkNode *&L,ElemType a[],int n)
//头插法建立单链表
{
LinkNode *s; //定义指向新节点的指针
L=(LinkNode *)malloc(sizeof(LinkNode)); //创建头结点
L->next=NULL;
for (int i=0;i<n;i++)
{
s=(LinkNode *)malloc(sizeof(LinkNode)); //创建新结点s
s->data=a[i];
s->next=L->next; //将结点s插在原开始结点之前,头结点之后
L->next=s;
}
}
2)尾插法
同样首先建立一个空链表,加入一个指针始终指向单链表的尾结点,以便新节点能插入单链表的尾部
void CreateListR(LinkNode *&L,ElemType a[],int n)
//尾插法建立单链表
{
LinkNode *s,*r;
L=(LinkNode *)malloc(sizeof(LinkNode)); //创建头结点
L->next=NULL;
r=L; //r始终指向终端结点,开始时指向头结点
for (int i=0;i<n;i++)
{
s=(LinkNode *)malloc(sizeof(LinkNode));//创建新结点s
s->data=a[i];
r->next=s; //将结点s插入结点r之后
r=s;
}
r->next=NULL; //终端结点next域置为NULL
}
2.求链表的长度
要设一个移动指针p和计数器
int ListLength(LinkNode *L)
{
int i=0;
LinkNode *p=L;
while(p->next!=NULL)
{
i++;
p=p->next; //通过该循环语句将指针p向后“移动”
}
return i;
}
3.输出单链表
将顺序表的元素依次打印输出
void DispList(LinkNode *L)
{
LinkNode *p=L->next;
while(p!=NULL)
{
printf("%4d\n",p->data);
p=p->next;
}
printf("\n");
}
4.判断单链表是否为空
bool ListEmpty(LinkNode *L)
{
return L->next==NULL;
}
5.查找单链表
1.按逻辑位序查找单链表
用p来遍历,用 j 来计数,循环条件为j<i 且指针p不为空
bool GetElem(LinkNode *L,int i,ElemType &e)
{
LinkNode *p=L;
int j=0;
while(j<i && p!=NULL)
{
j++;
p=p->next;
}
if(p==NULL)
return false;
else
e=p->data;
return true;
}
2.按值查找单链表
用指针p的循环遍历判断当前节点的数据域是否等于e,且同时用 j 计数,当p的数据域和e相等时,该值找到了,这时的 j 就是该值的位置
int LocateElem(LinkNode *L,ElemType e)
{
LinkNode *p=L->next;
int j=1;
while(p->data!=e && p!=NULL)
{
j++;
p=p->next;
}
if(p==NULL)
return 0;
else
return j;
}
6.在单链表中插入元素值
还是两个循环条件:要插入的位置 i 合理,指针p不为空,找到了之后就进行插入操作
bool ListInsert(LinkNode *&L,int i,ElemType e)
{
LinkNode *p=L->next,*s;
int j=1;
if(i<1)
return false;
while(j<i-1 && p!=NULL) //在单链表中查找第i-1个结点
{
j++;
p=p->next;
}
if(p==NULL)
return false;
else
{
s=(LinkNode*)malloc(sizeof(LinkNode));
s->data=e;
s->next=p->next;
p->next=s;
return true;
}
}
7.在单链表中删除元素值
先用指针p循环查找第i-1个结点,能循环的条件:1)位置 i 合理 、2)计数器 j 不超过要查找的位置 i 、3)指针p不为空
再进行删除操作.....
bool ListDelete(LinkNode *&L,int i,ElemType &e)
{
LinkNode *p=L->next,*q;
int j=1;
if(i<1)
return false;
while(j<i-1 && p!=NULL)
{
j++;
p=p->next;
}
if(p==NULL)
return false;
else
{
q=p->next;
if(q==NULL)
return false;
e=q->data;
p->next=q->next;
free(q);
return true;
}
}
8.销毁单链表
pre和p两个指针来完成向“后”推进
void DestroyList(LinkNode *&L)
{
LinkNode *pre=L,*p=L->next;
while(p!=NULL)
{
free(pre);
pre=p;
p=p->next;
}
free(pre);
}
9.链表的实现
//单链表基本运算算法
#include <stdio.h>
#include <stdlib.h>
typedef int ElemType;
typedef struct LNode
{
ElemType data;
struct LNode *next; //指向后继结点
} LinkNode; //声明单链表结点类型
void CreateListF(LinkNode *&L,ElemType a[],int n)
//头插法建立单链表
{
LinkNode *s;
L=(LinkNode *)malloc(sizeof(LinkNode)); //创建头结点
L->next=NULL;
for (int i=0;i<n;i++)
{
s=(LinkNode *)malloc(sizeof(LinkNode));//创建新结点s
s->data=a[i];
s->next=L->next; //将结点s插在原开始结点之前,头结点之后
L->next=s;
}
}
void CreateListR(LinkNode *&L,ElemType a[],int n)
//尾插法建立单链表
{
LinkNode *s,*r;
L=(LinkNode *)malloc(sizeof(LinkNode)); //创建头结点
L->next=NULL;
r=L; //r始终指向终端结点,开始时指向头结点
for (int i=0;i<n;i++)
{
s=(LinkNode *)malloc(sizeof(LinkNode));//创建新结点s
s->data=a[i];
r->next=s; //将结点s插入结点r之后
r=s;
}
r->next=NULL; //终端结点next域置为NULL
}
void InitList(LinkNode *&L)
{
L= (LinkNode*)malloc(sizeof(LinkNode));
L->next=NULL;
}
bool ListEmpty(LinkNode *L)
{
return L->next==NULL;
}
int ListLength(LinkNode *L)
{
int i=0;
LinkNode *p=L;
while(p->next!=NULL)
{
i++;
p=p->next;
}
return i;
}
void DispList(LinkNode *L)
{
LinkNode *p=L->next;
while(p!=NULL)
{
printf("%4d\n",p->data);
p=p->next;
}
printf("\n");
}
bool GetElem(LinkNode *L,int i,ElemType &e)
{
LinkNode *p=L;
int j=0;
while(j<i && p!=NULL)
{
j++;
p=p->next;
}
if(p==NULL)
return false;
else
e=p->data;
return true;
}
int LocateElem(LinkNode *L,ElemType e)
{
LinkNode *p=L->next;
int j=1;
while(p->data!=e && p!=NULL)
{
j++;
p=p->next;
}
if(p==NULL)
return 0;
else
return j;
}
bool ListInsert(LinkNode *&L,int i,ElemType e)
{
LinkNode *p=L->next,*s;
int j=1;
if(i<1)
return false;
while(j<i-1 && p!=NULL)
{
j++;
p=p->next;
}
if(p==NULL)
return false;
else
{
s=(LinkNode*)malloc(sizeof(LinkNode));
s->data=e;
s->next=p->next;
p->next=s;
return true;
}
}
bool ListDelete(LinkNode *&L,int i,ElemType &e)
{
LinkNode *p=L->next,*q;
int j=1;
if(i<1)
return false;
while(j<i-1 && p!=NULL)
{
j++;
p=p->next;
}
if(p==NULL)
return false;
else
{
q=p->next;
if(q==NULL)
return false;
e=q->data;
p->next=q->next;
free(q);
return true;
}
}
void DestroyList(LinkNode *&L)
{
LinkNode *pre=L,*p=L->next;
while(p!=NULL)
{
free(pre);
pre=p;
p=p->next;
}
free(pre);
}
int main()
{
LinkNode *p=NULL;
ElemType a[10]={1,2,3,4,5,6,7,8,9,0};
int i,j,r,n=10;
bool re;
ElemType e;
do{
printf("-------------------------------------\n");
printf("| 主菜单 |\n");
printf("| 1 初始化单链表 |\n");
printf("| 2 创建单链表 |\n");
printf("| 3 显示单链表 的长度 |\n");
printf("| 4 显示单链表 元素 |\n");
printf("| 5 判断线性表是否为空 |\n");
printf("| 6 按位置查找结点 |\n");
printf("| 7 按元素值查找 |\n");
printf("| 8 插入结点 |\n");
printf("| 9 删除结点 |\n");
printf("| 10 销毁单链表 |\n");
printf("| 0 退出 |\n");
printf("-------------------------------------\n");
printf("请输入您选择的操作:");
scanf("%d",&i);
switch(i)
{
case 1:
InitList(p);
break;
case 2:
CreateListF(p,a,n);
break;
case 3:
printf("长度为%d\n",ListLength(p));
break;
case 4:
DispList(p);
break;
case 5:
re=ListEmpty(p);
if(re==true)
printf("线性表为空\n");
else
printf("线性表不为空\n");
break;
case 6:
printf("请输入查找逻辑序号:");
scanf("%d",&j);
re=GetElem(p,j,e);
if(re)
printf("该元素为%d\n",e);
else
printf("查找失败!\n");
break;
case 7:
printf("请输入查找元素的值:");
scanf("%d",&j);
r=LocateElem(p,j);
if(r)
printf("元素的位置逻辑编号为%d\n",r);
else
printf("失败!\n");
break;
case 8:
printf("请输入元素插入位置:");
scanf("%d",&j);
printf("请输入插入元素值:");
scanf("%d",&e);
re=ListInsert(p,j,e);
if(re)
printf("插入成功!\n");
else
printf("插入失败!\n");
break;
case 9:
printf("请输入删除元素位置:");
scanf("%d",&j);
re=ListDelete(p,j,e);
if(re)
printf("删除成功!\n");
else
printf("删除失败!\n");
break;
case 10:
DestroyList(p);
break;
case 0:
exit(0);
default:
printf("输入有误,请重新输入\n");
break;
}
}while(1);
return 0;
}循环链表的实现
单链表的缺点:可以知道下个结点在哪里,如何找到前驱呢
循环链表:
将单链表的首尾相接,将终端结点的指针域由空指针改为指向头结点,构成单循环链表,简称循环链表

空循环链表
![]()
非空循环链表
![]()
非空和空表的处理一致
循环链表的插入
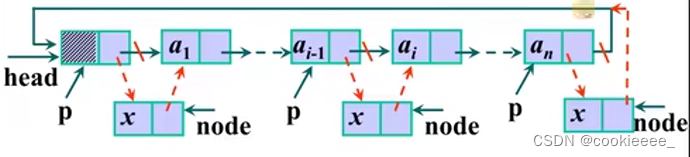
单链表的插入代码循环链表仍然可以使用,但要注意,循环链表中没有明显的尾端
要防止死循环的出现
p!=NULL 改成 p!=head
p->next!=NULL 改成 p->next!=head
循环链表设置尾指针

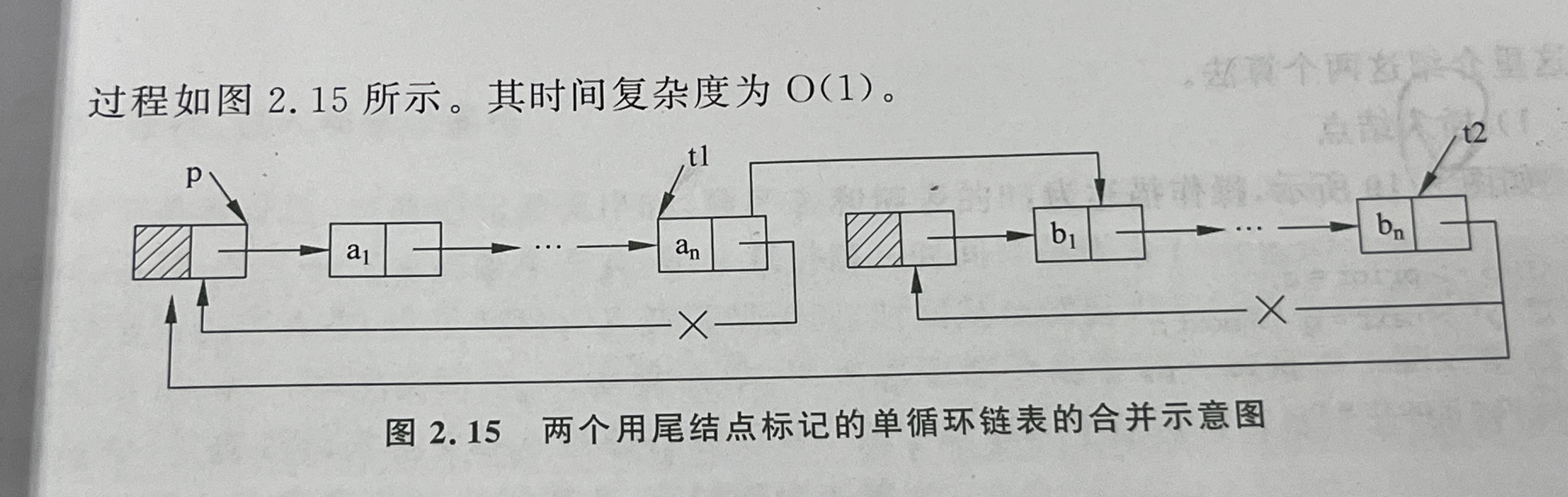
双向链表
1.在双向链表中,若 p 为指向某一结点的指针,则有: p->next->prior =p->prior>next=p; 这个表达式正反映了这种结构的特性。
2. 当想让p的前或后指针指向新节点s,直接p->next/prior=s,即可
![]()

求表长、查找、显示等仅需涉及一个方向的指针域,这些算法与单链表相同
但删除、插入这种需要修改两个方向的指针域操作有很大的不同
#include<stdio.h>
#include<stdlib.h>
#include<malloc.h>
typedef struct LNode{
int data;
struct LNode * next;
struct LNode * prior;
}*DLinkList,LNode;
void Menu();
void HeadCreatList(DLinkList * L);
void TailCreatList(DLinkList * L);
void InserList(DLinkList L,int i,int e );
void DeleList(DLinkList L,int i);
void PrintList(DLinkList L);
void DestoryList(DLinkList * L);
void SearchList(DLinkList L,int i);
void Menu(){
printf("\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t请输入下列你想要的操作\t\t\n");
printf("\t\t1.创建链表\t\t\t2.插入结点\t\t\t3.删除结点\t\t\t\n\t\t4.按位查找\t\t\t5.销毁链表\t\t\t6.打印链表\n\t\t0.退出程序\n ");
}
void HeadCreatList(DLinkList * L){
printf("选择头插法成功,结束输入请输入0:\n");
DLinkList p,s;
int x;
p=(*L)=(DLinkList)malloc(sizeof(LNode));
p->next=NULL;
p->prior=NULL;
scanf("%d",&x);
while(x){
s=(DLinkList)malloc(sizeof(LNode));
s->data=x;
//当插入的数据放在最后(即初始化只有头结点时)那该数据就没有前驱指针指向他,需要特殊处理
s->next=p->next;
if(p->next!=NULL)
p->next->prior=s;
p->next=s;
s->prior=p;
scanf("%d",&x);
}
printf("头插法创建成功\n");
}
void TailCreatList(DLinkList * L){
printf("选择尾插法成功,结束输入请输入0:\n");
DLinkList p,s;
int x;
p=(*L)=(DLinkList)malloc(sizeof(LNode));
p->next=NULL;
p->prior=NULL;
scanf("%d",&x);
while(x){
s=(DLinkList)malloc(sizeof(LNode));
s->data=x;
//当插入的数据放在最后(即初始化只有头结点时)那该数据就没有前驱指针指向他,需要特殊处理
s->next=p->next;
p->next=s;
s->prior=p;
p=p->next;
scanf("%d",&x);
}
s->next=NULL;
printf("尾插法创建成功\n");
}
void InserList(DLinkList L,int i,int e ){
DLinkList s,p;
p=L;
int count=0;
s=(LNode *)malloc(sizeof(LNode));
s->data=e;
while(count<i-1 && p!=NULL){
p=p->next;
count++;
}
s->next=p->next;
if(p->next!=NULL)
p->next->prior=s;
p->next=s;
s->prior=p;
printf("插入成功\n");
}
void DeleList(DLinkList L,int i){
int count=0;
while(count<i-1 && L!=NULL){
L=L->next;
count++;
}
if(L->next==NULL)
return;
LNode * s=(LNode *)malloc(sizeof(LNode));
s=L->next;
L->next=s->next;
s->next->prior=L;
free(s);
printf("删除成功\n");
}
void PrintList(DLinkList L){
while(L->next!=NULL){
L=L->next;
printf("%d ",L->data);
}
printf("\n");
}
void DestoryList(DLinkList * L){
DLinkList p,temp;
p=(*L)->next;//从第一个结点开始
while(p!=NULL){
temp=p->next;
free(p);
p=temp;
}
(*L)->next=NULL; //让头结点指针指向NULL
printf("销毁成功\n");
}
void SearchList(DLinkList L,int i){
if(i<1)
return;
LNode * p=L;
int j =0;
while(p!=NULL && j<i-1){
p=p->next;
j++;
}
printf("该值为%d\n",p->next->data);
}
int main()
{
DLinkList L;
int command;
int command1;
int i,e,x;
Menu();
do{
scanf("%d",&command);
switch(command){
case 1:printf("请选择<头插法/尾插法> <1/2>\n");
scanf("%d",&command1);
if(command1==1) HeadCreatList(&L);
else if(command1==2) TailCreatList(&L);
else printf("输入错误请重新输入:");
break;
case 2:printf("请输入需要插入结点的序列 >");
scanf("%d",&i);
printf("请输入需要插入结点的数值 >");
scanf("%d",&e);
InserList(L,i,e);
break;
case 3:printf("请输入要删结点的序列 >");
scanf("%d",&i);
DeleList(L,i);
break;
case 4:printf("请输入需要查找结点的序号>");
scanf("%d",&i);
SearchList(L,i);
break;
case 5:DestoryList(&L);
break;
case 6:PrintList(L);
break;
case 0:printf("退出成功");
break;
default :printf("输入错误,请重新输入 >");
break;
};
}while(command);
return 0;
}实践1--学生管理系统
链表的遍历
两种链表,第一种是第一个节点数据部分为空,另一种是第一个节点就存放数据
第一种方式:不管怎样对链表进行增加修改和删除,head的位置不会变化,head的值只需要传到函数中,不需要返回
第二种方式:如果数据插入到第一个节点,head存储的地址会发生变化,这种方式的链表在定义函数时,需要返回链表的head
本次使用第一种方式
算法分析
1.增加学生记录
先写出学生信息结构体
typedef struct Student{
char sno[20];
char sname[11];
}st;
再写出结点的结构体
typedef struct node{
struct Student data; //把学生信息结构体作为内容放在data区域
struct node *next;
}Node,*Link;
2.删除链表:
首先,利用 p 指针扫描链表,根据学生的学号找到要删除的节点位置。如果找到,则用以下语句就可以删除 p 所指向的节点:
q -> next = p->next;
free(p);
这里编程的要点是: 要保证 p,q 保持一前一后的关系,这样才能保证在找到节点位置后,可以顺利的删除。
如果当前 p 的学号不等于准备找的学号,则 p 指针后移。
3.修改链表,链表的查询:
这两个功能和删除链表的思路类似:
都是先找到要处理的节点,然后处理即可。
“修改”还要考虑修改的内容是否是学号,如果修改了学号,则应该编写程序保证不能破坏链表有序性的这个特点。
4.链表的清除:
当在菜单中选择了退出功能后,则结束程序。在结束程序之间,要考虑到一个问题:前面用 malloc 语句建立的结点,在 main 函数退出时,分配的存储空间是不会自动释放的,所以必须主动释放链表中所有节点占用的内存。
定义一个 clearLink 函数,实现链表的遍历,并用 free 语句释放所有 malloc 产生的结点
//============================================================================
// Name : LinkBlank.cpp
// Author :
// Version :
// Copyright : Your copyright notice
// Description : Hello World in C++, Ansi-style
//============================================================================
#include <stdio.h>
#include<string.h>
#include<malloc.h>
#include<stdlib.h>
#include<stdbool.h>
#define NO_LENGTH 20
#define NAME_LENGTH 11
/* 定义学生结构体的数据结构 */
typedef struct Student{
char studentNo[NO_LENGTH];
char studentName[NAME_LENGTH];
}st;
/* 定义每条记录或节点的数据结构 */
typedef struct node
{
struct Student data; //数据域
struct node *next; //指针域
}Node,*Link; //Node为node类型的别名,Link为node类型的指针别名
//定义提示菜单
void myMenu(){
printf(" * * * * * * * * * 菜 单 * * * * * * * * * *\n");
printf(" 1 增加学生记录 2 删除学生记录 \n");
printf(" 3 查找学生记录 4 修改学生记录 \n");
printf(" 5 统计学生人数 6 显示学生记录 \n");
printf(" 7 退出系统 \n");
printf(" * * * * * * * * * * * * * * * * * * * * * * * *\n");
}
void inputStudent(Link l){
printf("请输入学生学号:");
scanf("%s",l->data.studentNo);
printf("请输入学生的姓名:");
scanf("%s",l->data.studentName);
//每个新创建的节点的next域都初始化为NULL
l->next = NULL;
}
void inputStudentNo(char s[],char no[]){
printf("请输入要%s的学生学号:",s);
scanf("%s",no);
}
void displayNode(Link head){
// 填写代码,根据传入的链表head头指针,扫描链表显示所有节点的信息
}
/* 增加学生记录 */
bool addNode(Link head){
Link p,q; //p,q两个节点一前一后
Link node; //node指针指向新创建的节点
node=(Link)malloc(sizeof(Node));
inputStudent(node);
q = head;
p = head->next; //q指向head后面的第一个有效节点
if(head->next==NULL)
//链表为空时
head->next = node;
else {
//循环访问链表中的所有节点
while(p != NULL){
if (node->data.studentNo < p->data.studentNo){
//如果node节点的学号比p节点的学号小,则插在p的前面,完成插入后,提前退出子程序
q->next = node;
node->next = p;
return true;
}
else{
//如果node节点的学号比p节点的学号大,继续向后移动指针(依然保持pq一前一后)
q = p;
p = p->next;
}
}
//如果没能提前退出循环,则说明之前没有插入,那么当前node节点的学号是最大值,此时插在链表的最后面
q->next = node;
}
return true;
}
bool deleteNode(Link head){
// 按照给定的学号删除学生记录,如果删除成功返回true,如果没找到学号返回false
//输入要处理的学号
char no[NO_LENGTH];
inputStudentNo("修改",no);
return false;
}
bool queryNode(Link head){
// 按照给定的学号查询学生记录,如果删除成功返回true,如果没找到学号返回false
//输入要处理的学号
char no[NO_LENGTH];
inputStudentNo("修改",no);
return false;
}
bool modifyNode(Link head){
// 按照给定的学号找到学生记录节点,如果修改成功返回true,如果没找到学号返回false
//输入要处理的学号
char no[NO_LENGTH];
inputStudentNo("修改",no);
return false;
}
int countNode(Link head){
//统计学生人数,扫描链表统计节点个数,返回节点数
Link p;
int count = 0;
p = head->next;
//填充代码
return false;
}
void clearLink(Link head){
Link q,p;
//遍历链表,用free语句删除链表中用malloc建立起的所有的节点
}
int main() {
int select;
int count;
Link head; // 定义链表
//建立head头结点,在这个程序中head指向头结点,头结点data部分没有内容,其后续节点才有真正的数据
head = (Link)malloc(sizeof(Node));
head->next = NULL;
while(1)
{
myMenu();
printf("\n请输入你的选择(0-7):"); //显示提示信息
scanf("%d",&select);
switch(select)
{
case 1:
//增加学生记录
if(addNode(head))
printf("成功插入一个学生记录。\n\n");
break;
case 2:
//删除学生记录
if(deleteNode(head))
printf("成功删除一个学生记录。\n\n");
else
printf("没有找到要删除的学生节点。\n\n");
break;
case 3:
//查询学生记录
if(queryNode(head))
printf("成功找到学生记录。\n\n");
else
printf("没有找到要查询的学生节点。\n\n");
break;
case 4:
//修改学生记录
if(modifyNode(head))
printf("成功修改一个学生记录。\n\n");
else
printf("没有找到要修改的学生节点。\n\n");
break;
case 5:
//统计学生人数
count = countNode(head);
printf("学生人数为:%d\n\n",count);
break;
case 6:
//显示学生记录
displayNode(head);
break;
case 7:
//退出前清除链表中的所有结点
clearLink(head);
return 0;
default:
printf("输入不正确,应该输入0-7之间的数。\n\n");
break;
}
}
return 0;
}实践2--约瑟夫环
1.约瑟夫环的定义
约瑟夫问题:有 n只猴子,按顺时针方向围成一圈选大王(编号从1到n),从第1号开始报数,一直数到m,数到m的猴子退出圈外,剩下的猴子再接着从1开始报数。就这样,直到圈内只剩下一只猴子时,这个猴子就是猴王,编程求输入 n,m后,输出最后猴王的编号。
2.用循环链表实现
#include <stdio.h>
#include <stdlib.h>
struct node {
int data;
struct node *next;
};
int main(void)
{
int n, m; //n个猴子个数,到m退出(隔m报数)
int i;
int answer[100]; //answer保存每次的答案,最后统一输出
int count = 0; //count用来控制题目答案的下标
struct node *head, *tail, *p, *q;
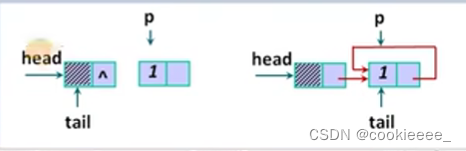
head = (struct node *)malloc(sizeof(struct node));//创建一个空指针,强制转换成指向结构体的指针
head->next = NULL;//指针域赋为空
while (1) {
scanf("%d %d", &n, &m);
if (n == 0 || m == 0) {
free(head);//要把创建的空间释放掉
break;
}
else {
//尾插法,生成循环链表
tail = head;
for (i = 0; i < n; i++) {
p = (struct node *)malloc(sizeof(struct node));
p->data = i + 1;//填写猴子序号

tail->next = p;
p->next = head->next;
tail = p;
}
//报数
p = head->next; //后结点
q = tail; //前结点
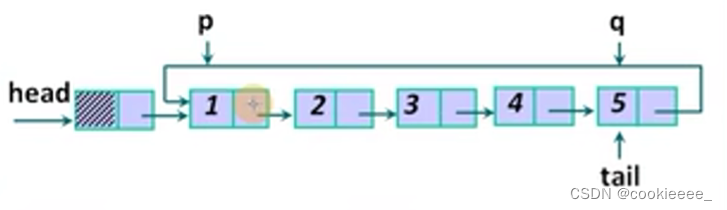
i = 1;
while (p != q) {
if (i == m) { //达到m,删除此数
q->next = p->next;
free(p);
p = q->next;
i = 1;
} else {
q = p;
p = p->next;
i++;
}
}
answer[count] = p->data;
count++;
free(p);//注意链表的删除
head->next = NULL;
}
}
for (i = 0; i < count; i++) {
printf("%d\n", answer[i]);
}
return 0;
}
3.数组标志位实现
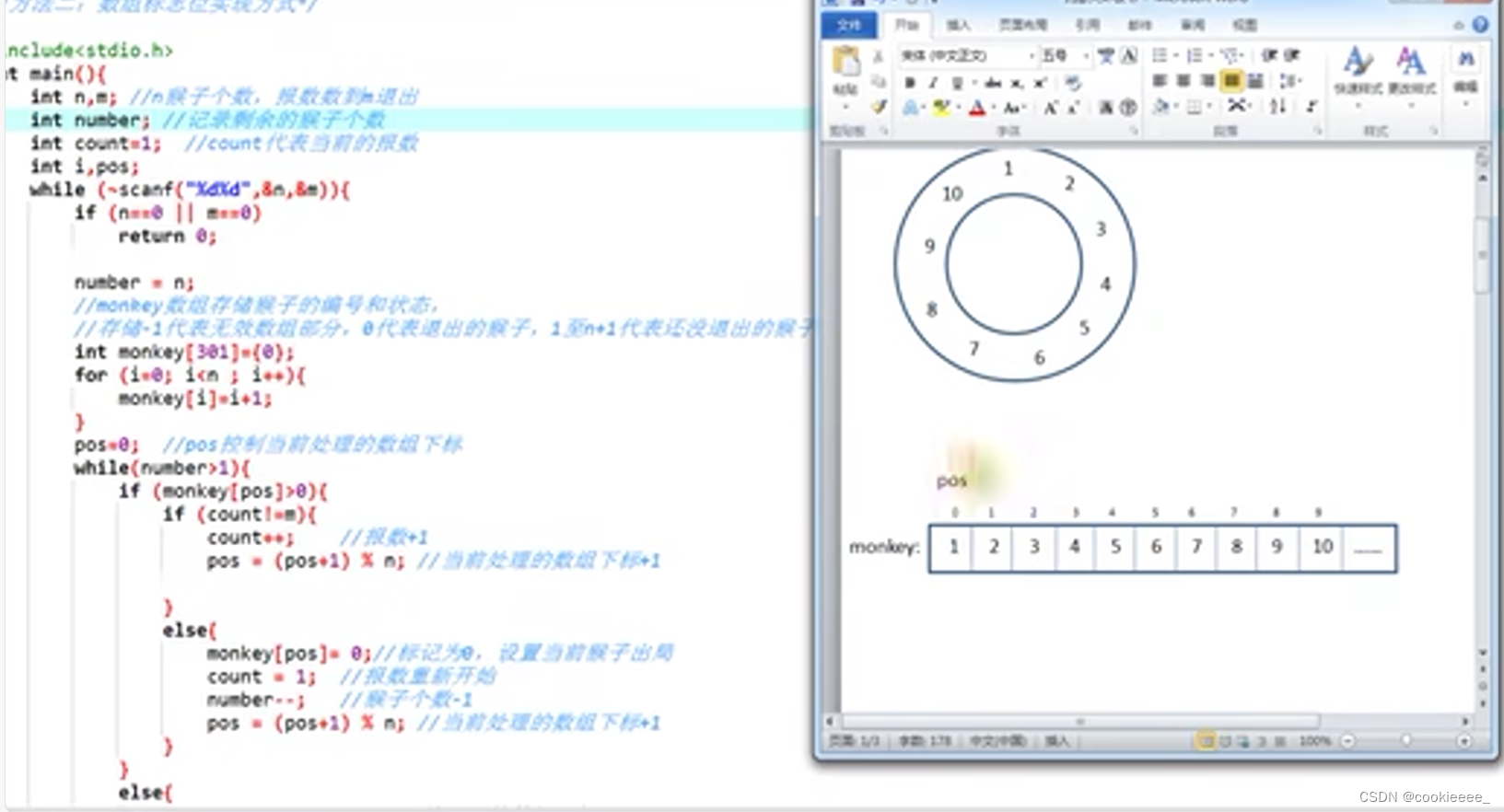
4.数组链接方式实现
实践3--多项式加法
思路:
代码
题目描述:
实现两个一元n次多项式的加法。例如P(A)=x+3x2-5x5+7,P(B)=2x2+6x3+x5-4x6,求P(A)+P(B)。
提示:
首先弄清楚一元多项式的加法原理,然后明确多项式的存储方法。链表节点存储系数和指数,只存系数非0的项。
讨论内容:
(1) 指针ha和hb分别指向两个多项式中当前进行比较的节点,如果指针ha所指节点的指数小于指针hb所指节点的指数值,该怎么处理?
(2) 如果指针ha所指节点的指数等于指针hb所指节点的指数值,该怎么处理?
(3) 如果指针ha所指节点的指数大于指针hb所指节点的指数值,该怎么处理?
(4) 如果其中一个多项式先比较完,那么另一个多项式余下的部分该怎么处理?
代码内容:
1.先定义一个结构体
typedef struct polynomial
{
int coefficient;//系数
int exp;//指数
struct polynomial *next;
}*Link,Node;//用Link可以声明一个指向结构体的指针,Node可以声明这种形式的结构体变量
void inputPoly(Link head);//用于从控制台读入链表的函数
void print(Link head);//打印链表用的函数
bool insert(Link head,int coefficient,int exp);//向链表插入一个元素的函数
void combin2List(Link heada,Link headb,Link headab);//合并两个链表
int main()
{
Link headA,headB;//两个多项式的头指针
Link headAB;//合并后的多项式的头指针
/*链表的初始化*/
headA=(Link)malloc(sizeof(Node));
headA->next=NULL;
headB=(Link)malloc(sizeof(Node));
headB->next=NULL;
headAB=(Link)malloc(sizeof(Node));
headAB->next=NULL;
printf("请输入第一个多项式的系数和指数,以(0 0)结束:\n");
inputPoly(headA);
printf("第一个");
print(headA);
printf("请输入第二个多项式的系数和指数,以(0 0)结束:\n");
inputPoly(headB);
printf("第二个");
print(headB);
combin2List(headA,headB,headAB);
printf("合并后");
print(headAB);
return 0;
}
/**输入二项式数据的函数*/
/*这个函数用来输入二项式,给用户合适的提示,读入用户输入的系数和指数。
调用函数insert,将用户输入的二项式的一项插入到链表中去。*/
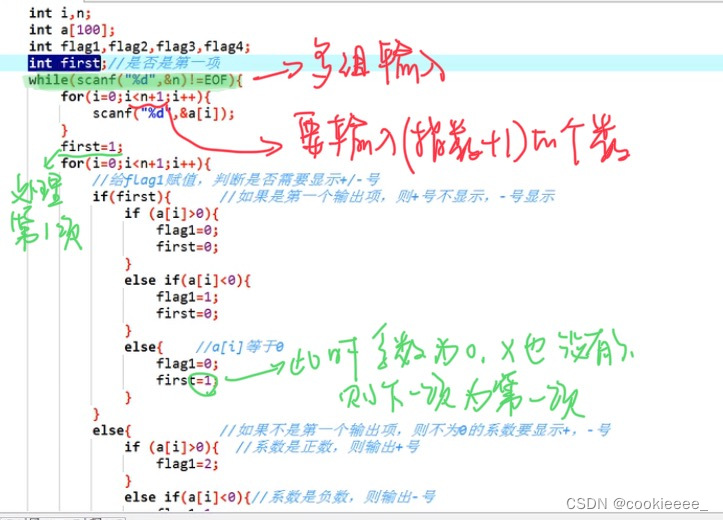
void inputPoly(Link head)
{
int coefficient,exp;//系数和指数
printf("请输入系数和指数(如:\"2 3\"表示2x^3):");
scanf("%d %d",&coefficient,&exp);
while(coefficient!=0||exp!=0)//连续输入多个系数和指数
{
insert(head,coefficient,exp);//调函数输入多项式
printf("请输入系数和指数:");
scanf("%d %d",&coefficient,&exp);
}
}
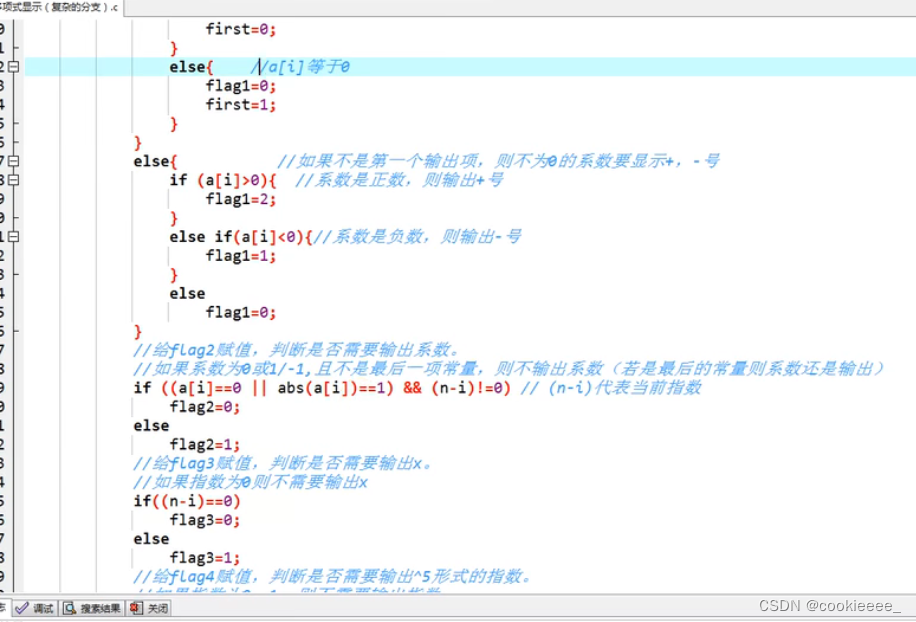
插入
1.无节点(head->next为空时):
用head->next=node这条语句,把node插入到链表中
2.有节点了(但假设该链表是有序的)
因为有序所以先比较node的系数指数和要插入位置的系数指数:
1)大于,插在前面
2)等于,将系数进行合并,之后将node结点free掉
3)小于,插在后面,且需要循环与后面比较大小
/**向多项式链表中插入元素的函数
int coefficient 一个多项式项的系数
int exp 一个多项式项的幂
*/
bool insert(Link head,int coefficient,int exp)
{
Link node; //node指针指向新创建的节点
Link q,p; //q,p两个节点一前一后
//创建一个新结点
//.....
if(head->next==NULL)//空表,插第1个
{
//......
}
else
{
while(p != NULL){ //循环访问链表中的所有节点
//如果node节点的指数比p节点的指数大,则插在p的前面,完成插入后,提前退出
//如果node节点的指数和p节点的指数相等,则合并这个多项式节点,提前退出
//如果node节点的指数比p节点的指数小,继续向后移动指针(依然保持p,q一前一后)
}
//如果退出循环是当前指针p移动到链表结尾,则说明之前没有插入,那么当前node节点的指数值是最大值,此时插在链表的最后面
}
return true;
}
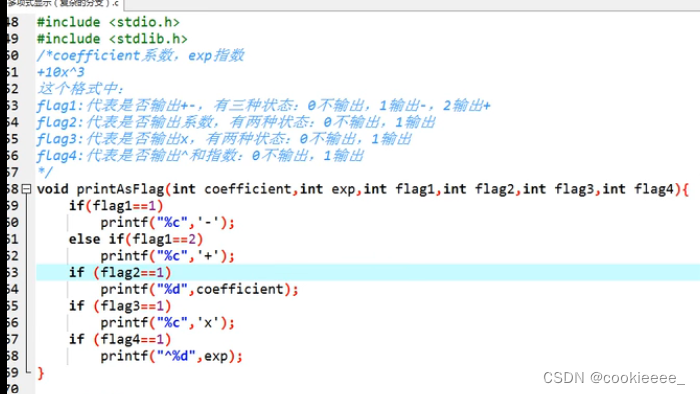
/**
打印多项式链表的函数
*/
/*
① 通过指针访问链表
② 多重条件语句嵌套
③ 数字转换为字符串函数itoa
④ 标志是否为第一个节点的flag的设置
⑤ 字符串连接函数strcat
⑥ 字符串清空函数memset。memset(item,0,20);清空长20的字符串item
请补充代码实现。
*/
void print(Link head)
{
Link p; //指向链表要输出的结点
printf("多项式如下:\n");
p=head->next;
if (p == NULL)
{
printf("多项式为空\n");
return;
}
// 不是空表
char item[20]="";//要打印的当前多项式的一项
char number[7]="";//暂时存放系数转换成的字符串
bool isFirstItem=true;//标志是否为第一个节点的flag
//打印节点
do {
memset(item,0,20);//清空字符串item
//如果是第一项,不要打+号
//如果不是第一项,且系数为正数,要打加号
//如果系数为负数,系数自身带有符号
//如果系数为1,不用打系数
//系数为-1打印负号
//如果系数不为1或-1,打印系数
//如果指数为0,直接打系数不用打x^和指数
//如果系数是-1或1,需要打1出来,不能只打符号
//指数不为0
//打印x
//如果指数为1,不打指数,否则打指数
printf("%s",item);//打印当前节点代表的项
p = p->next;//指向下个结点
isFirstItem=false;//flag标志不是第一项了
}while(p != NULL);
printf("\n");
return;
}
/**
合并两个有序链表a,b到链表ab
heada.headb,headab分别为链表a,b,ab的头指针
*/
void combin2List(Link heada,Link headb,Link headab)
{
Link pa,pb;//指向a,b链表和ab的指针
pa=heada->next;
pb=headb->next;
while(pa!=NULL&&pb!=NULL)//a,b链表都没有没有访问完毕
{
//如果指数a>指数b,a节点插入ab链表,a指针后移
//如果指数a<指数b,b节点插入ab链表,b指针后移
//如果指数a==指数b,a、b系数相加,插入ab链表,a、b指针后移
//......
}
//如果a、b链表还有尾巴,将它加到ab链表后面
while(pa!=NULL)
{
//......
}
while(pb!=NULL)
{
//.......
}
return;
}
栈
栈、队列、线性表都是逻辑结构
顺序栈
1.概念:栈是操作受限的线性表,插入和删除数据元素的操作只能在线性表的一段进行
可以用一维数组表示用一个记录栈顶位置的整型变量(栈顶指针)来表示栈顶元素的位置
2.主要操作:
1)入栈
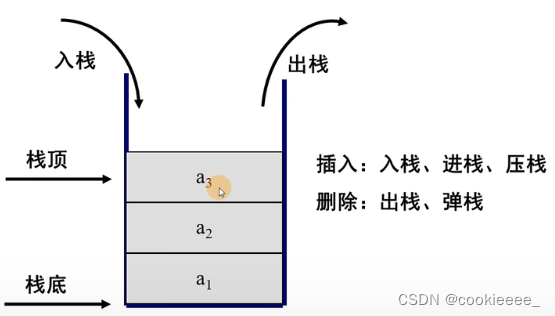
2)栈的操作特性:先进后出
考题1:
判断是否合法
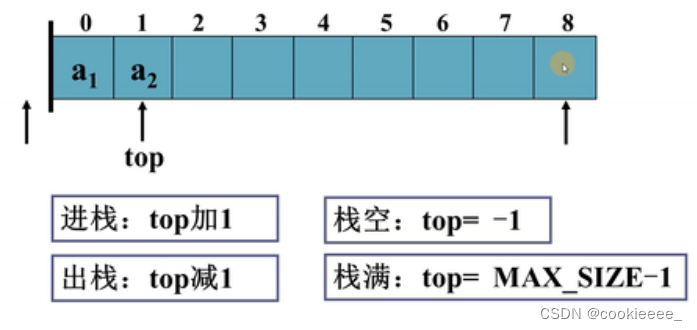
3.栈的顺序存储结构及实现
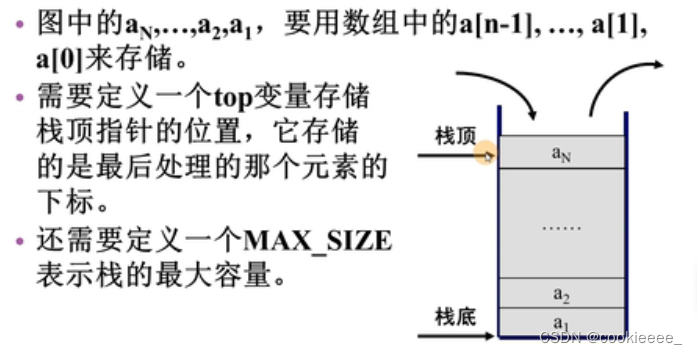
4.栈的上溢和下溢
上溢:栈顶的指针指出栈的外面
下溢:本身可以表示空栈,因此可以用它来作为控制转移的条件
上溢的判断
当栈为空时,top的值为-1.当往栈中压入一个元素时,top的值会加1。这样,a[0]就代表第一个进栈的元素,a[i-1]代表第i个进栈的元素,a[top]则表示栈顶元素
当top== MAX_SIZE-1(上溢)时,表示栈满。如果再有元素进栈时,则栈会溢出,这时称为上溢,上溢出是一种错误状态,应该避免
下溢的判断
反之当top==-1(栈为空)时,再将栈顶元素弹出,就要发生下溢,下溢出是正常状态
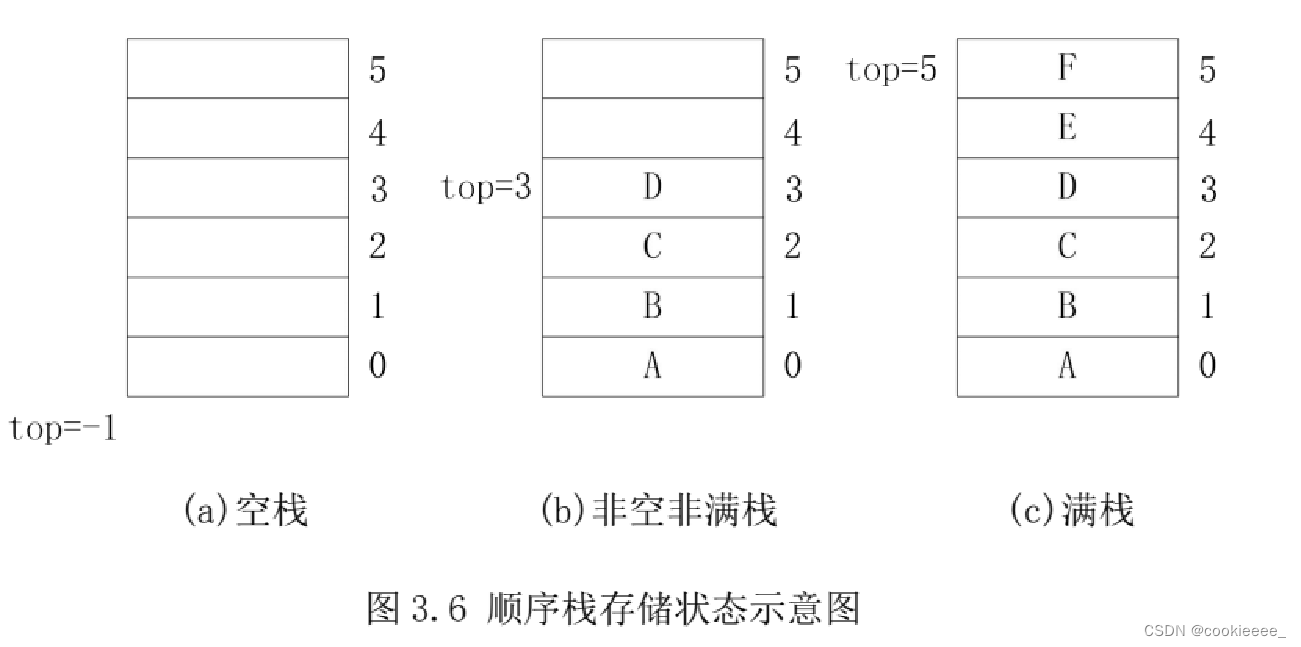
5.顺序栈的存储形态
根据顺序栈中元素的数目和栈的容量,顺序栈存在三种形态:空栈、非空非满栈和满栈。
6.栈类的定义
#define MAX_SIZE100 //定义栈最大值常量
typedef int ElemType;
typedef struct SequnceStack
{
ElemType data[MAXSIZE];
int top; //栈顶指针,表示栈顶元素的数组下标
} SqStack; //顺序栈类型
初始化函数
void initStack(SqStack *&s)
{
s=(SqStack *)malloc(sizeof(SqStack));
s->top=-1; //空顺序栈的标识
}
判断顺序栈是否为空
bool StackEmpty (SqStack *s)
{
return s->top==-1;
}
入栈操作
bool Push(SqStack *&s,ElemType e)
{
if(s->top==MAXSIZE-1) //栈满的情况,即上溢
return false;
s->top++; //修改栈顶指针,加1
s->data[s->top]=e; //在栈顶添加新元素e入栈
return true;
}
出栈操作
bool Pop(SqStack *&s,Elemtype &e)
{
if(s->top==-1) //栈为空,即下溢
return false;
e=s->data[a->top]; //将栈顶元素值赋给引用型参数e
s->top--; //栈顶指针top减1
return true;
}
读取栈顶元素
bool GetTop(SqStack *s,ElemType &e)
{
if(s->top==-1) //如果顺序栈s不为空
return false;
e=s->data[s->top]; //将栈顶元素值赋给引用型参数e
return true;
}
销毁栈函数
void DestroyStack(SqStack *&s)
{
free(s->data); //销毁指针s指向的顺序栈空间
s=NULL;
}
上述 6 个顺序栈基本操作的时间复杂度均为 O(1),说明顺序栈是一种高效的算法设计。
7.顺序栈的实现
//顺序栈基本运算算法
#include <stdio.h>
#include <stdlib.h>
#define MaxSize 100
typedef int ElemType;
typedef struct
{
ElemType data[MaxSize];
int top; //栈指针
} SqStack; //顺序栈类型
void InitStack(SqStack *&s)
{
s=(SqStack *)malloc(sizeof(SqStack));
s->top=-1;
}
void DestroyStack(SqStack *&s)
{
free(s);
}
bool StackEmpty(SqStack *s)
{
return(s->top==-1);
}
bool Push(SqStack *&s,ElemType e)
{
if (s->top==MaxSize-1) //栈满的情况,即栈上溢出
return false;
s->top++;
s->data[s->top]=e;
return true;
}
bool Pop(SqStack *&s,ElemType &e)
{
if (s->top==-1) //栈为空的情况,即栈下溢出
return false;
e=s->data[s->top];
s->top--;
return true;
}
bool GetTop(SqStack *s,ElemType &e)
{
if (s->top==-1) //栈为空的情况,即栈下溢出
return false;
e=s->data[s->top];
return true;
}
int main()
{
SqStack *s;
ElemType e;
bool re;
int i;
do{
printf("-------------------------------------\n");
printf("| 主菜单 |\n");
printf("| 1 初始化顺序栈 |\n");
printf("| 2 进栈 |\n");
printf("| 3 出栈 |\n");
printf("| 4 判断是否为空 |\n");
printf("| 5 取栈顶元素 |\n");
printf("| 6 销毁栈 |\n");
printf("-------------------------------------\n");
printf("请输入您选择的操作:");
scanf("%d",&i);
switch(i)
{
case 1:
InitStack(s);
break;
case 2:
printf("请输入进栈的元素值\n");
scanf("%d",&e);
Push(s,e);
break;
case 3:
Pop(s,e);
printf("出栈元素为%d\n",e);
break;
case 4:
re=StackEmpty(s);
if(re==true)
printf("为空\n");
else
printf("不为空\n");
break;
case 5:
GetTop(s,e);
printf("栈顶元素为%d\n",e);
break;
case 6:
DestroyStack(s);
break;
default:
printf("输入有误,请重新输入\n");
break;
}
}while(1);
return 0;
}
链栈
采用链式存储的栈称为链栈,用单链表实现
优点:不存在栈满上溢的情况
链栈的所有操作是在单链表的表头进行的,用带头节点的单链表表示链栈
第一个数据节点是栈顶节点,最后一个数据节点是栈底节点
栈为空的条件是s->next==NULL,表示单链表中没有数据节点
栈满条件不考虑
链栈示意图
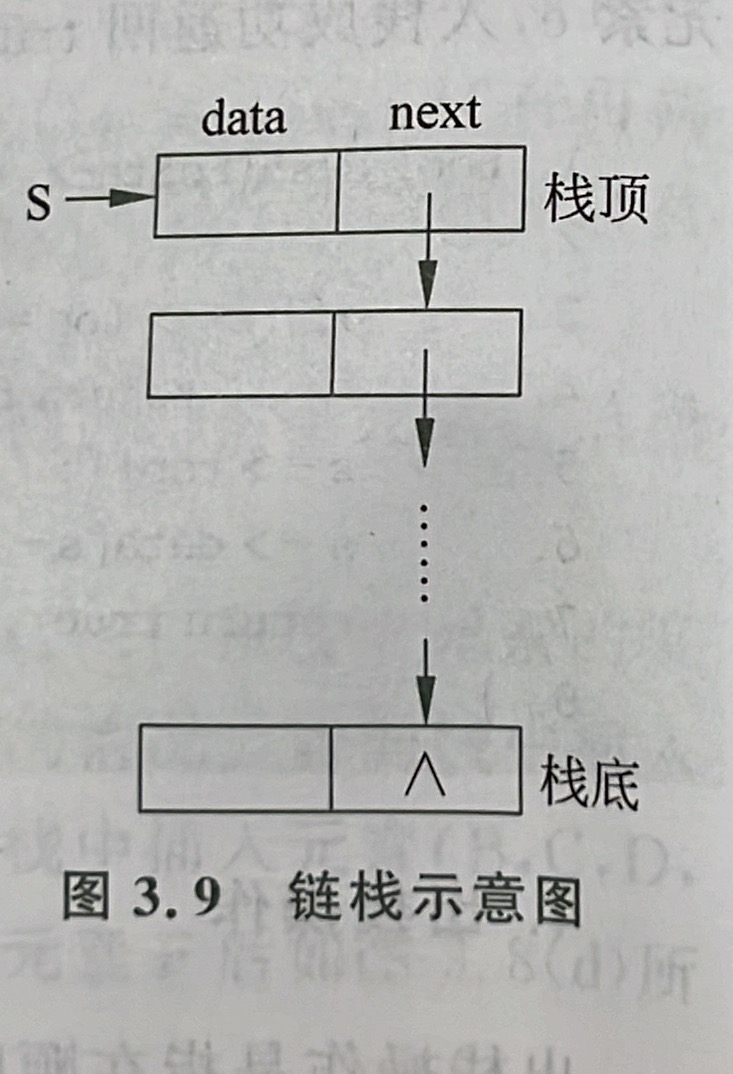
LinkStNode *&s表明s是指向当前链栈的指针,ElemType &e表示e是出栈的元素值反向传给主调函数
链栈的基本操作
1.链栈的类型定义
typedef int ElemType;
typedef struct linknode
{
ElemType data; //数据域
struct linknode *next; //指针域
}LinkStNode; //链栈节点类型
2.初始化链栈
void IinitStack(LinkStNode *&s)
{
s=(LinkStNode *)malloc(sizeof(LinkStNode));
s->next=NULL;
}
![]()
3.判断栈是否为空
bool StackEmpty(LinkStNode *s)
{
return s->next==NULL;
}
4.出栈
bool Pop(LinkStNode *&s,ElemType &e)
{
LinkStNode *p;
if(s->next==NULL) //栈空的情况
return false;
p=s->next; //s->next(头节点的指针域)存的是此时此刻栈顶结点的地址,将地址 赋值给p也就是说p指向首节点,即删除栈顶节点
e=p->data; //将栈顶节点的值赋给e
s->next=p->next; //头节点指向新的栈顶节点
free(p); //释放p指向的节点
p=NULL;
return true;
}
5.入栈
void Push(LinkStNode *&s,ElemType e)
{ LinkStNode *p;
p=(LinkStNode *)malloc(sizeof(LinkStNode));
p->data=e; //新建元素e对应的结点p
p->next=s->next; //插入p结点作为开始结点
s->next=p;
}
6.读取栈顶元素
bool GetTop(LinkStNode *s,ElemType &e)
{ if (s->next==NULL) //栈空的情况
return false;
e=s->next->data;
return true;
}
7.销毁链栈
依次销毁栈顶结点
void DestroyStack(LinkStNode *&s)
{
LinkStNode *p=s->next;
while (p!=NULL)
{
free(s);
s=p;
p=p->next;
}
free(s); //s指向尾结点,释放其空间
}
链栈的实现
//链栈基本运算算法
#include <stdio.h>
#include <stdlib.h>
typedef int ElemType;
typedef struct linknode
{
ElemType data; //数据域
struct linknode *next; //指针域
} LinkStNode; //链栈类型
void InitStack(LinkStNode *&s)
{
s=(LinkStNode *)malloc(sizeof(LinkStNode));
s->next=NULL;
}
void DestroyStack(LinkStNode *&s)
{
LinkStNode *p=s->next;
while (p!=NULL)
{
free(s);
s=p;
p=p->next;
}
free(s); //s指向尾结点,释放其空间
}
bool StackEmpty(LinkStNode *s)
{
return(s->next==NULL);
}
void Push(LinkStNode *&s,ElemType e)
{ LinkStNode *p;
p=(LinkStNode *)malloc(sizeof(LinkStNode));
p->data=e; //新建元素e对应的结点p
p->next=s->next; //插入p结点作为开始结点
s->next=p;
}
bool Pop(LinkStNode *&s,ElemType &e)
{ LinkStNode *p;
if (s->next==NULL) //栈空的情况
return false;
p=s->next; //p指向开始结点
e=p->data;
s->next=p->next; //删除p结点
free(p); //释放p结点
return true;
}
bool GetTop(LinkStNode *s,ElemType &e)
{ if (s->next==NULL) //栈空的情况
return false;
e=s->next->data;
return true;
}
int main()
{
LinkStNode *s;
ElemType e;
bool re;
int i;
do{
printf("-------------------------------------\n");
printf("| 主菜单 |\n");
printf("| 1 初始化顺序栈 |\n");
printf("| 2 进栈 |\n");
printf("| 3 出栈 |\n");
printf("| 4 判断是否为空 |\n");
printf("| 5 取栈顶元素 |\n");
printf("| 6 销毁栈 |\n");
printf("-------------------------------------\n");
printf("请输入您选择的操作:");
scanf("%d",&i);
switch(i)
{
case 1:
InitStack(s);
break;
case 2:
printf("请输入进栈的元素值\n");
scanf("%d",&e);
Push(s,e);
break;
case 3:
Pop(s,e);
printf("出栈元素为%d\n",e);
break;
case 4:
re=StackEmpty(s);
if(re==true)
printf("为空\n");
else
printf("不为空\n");
break;
case 5:
GetTop(s,e);
printf("栈顶元素为%d\n",e);
break;
case 6:
DestroyStack(s);
break;
default:
printf("输入有误,请重新输入\n");
break;
}
}while(1);
return 0;
}栈的案例分析
十进制二进制转换
算术表达式转换
错题
以下说法错误的是( )。
- A、用一片连续的存储空间来存储栈中的数据元素,这样的栈称为顺序栈
- B、可用一维数组来存放顺序栈
- C、在顺序栈中无需记录栈顶元素的位置
- D、栈也有两种存储结构分别为顺序存储结构和链式存储结构
队列
定义
队列(Queue)是插入操作限定在表的尾部,而删除操作限定在表的头部进行的线性表。把允许进行删除的一端称为队头(front),允许插入的一端称为队尾(rear)。在队列中插入一个新元素的操作简称为进队或入队,新元素进队后就成为新的队尾元素;从队列中删除一个元素的操作简称为出队或离队,当元素出队后,其后继元素就成为新的队头元素。若队列中没有元素,则称为空队列。
队列的操作是按照先进先出(FIFO)或者后进后出(LILO)
顺序队
1.定义
用一片连续的存储空间来存储队列中的数据元素,这样的队列称为顺序队列(SequenceQueue)。类似于顺序栈,用一维数组来存放顺序队列中的数据元素,用队头指针 front 和队尾指针 rear 来指示队头元素和队尾元素的位置。和顺序栈一样,顺序队列也有空队、满队或非空非满队三种形态。
注意:
队头指针front指向当前队头元素的前一个位置,而不是指向队头元素
2.顺序队示意图
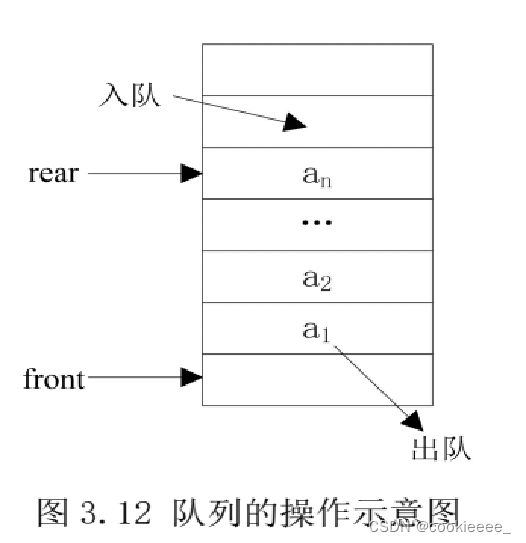
3.假溢出
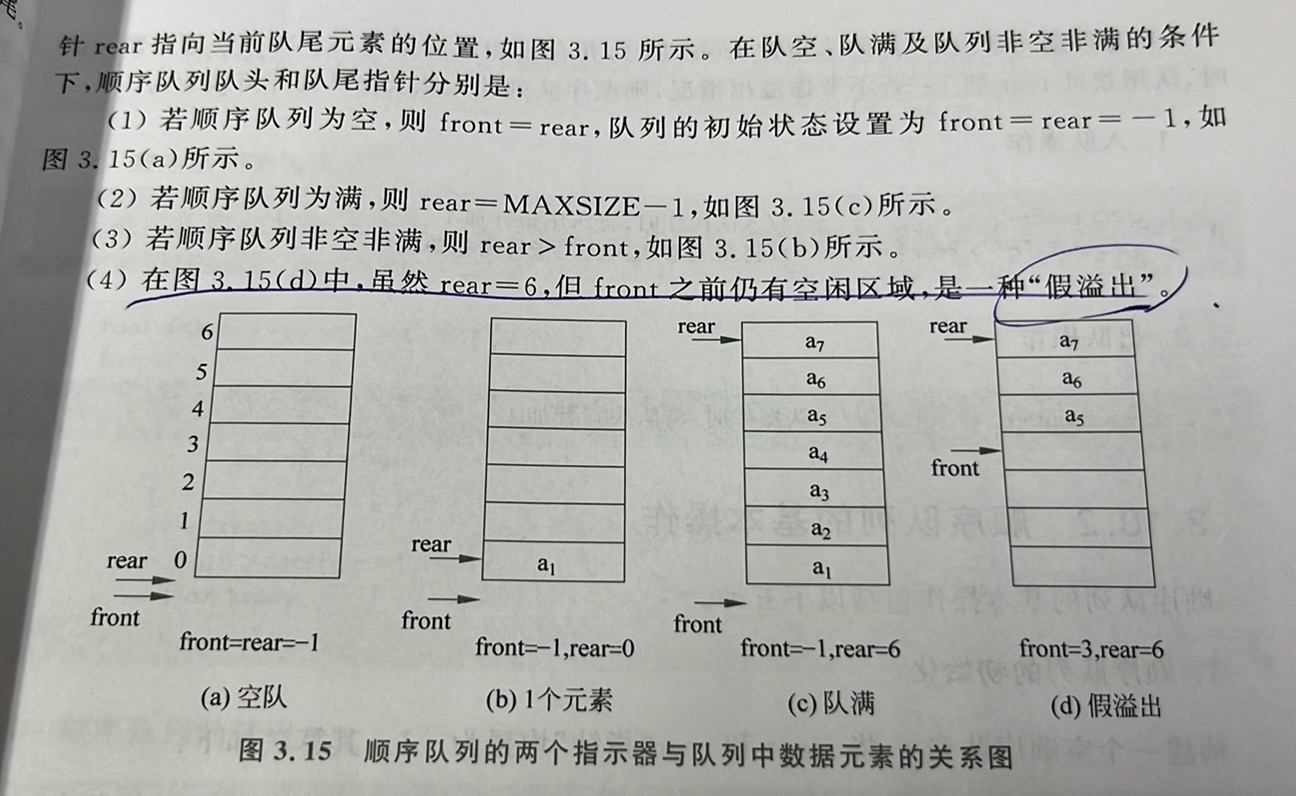
当前队列中元素的个数(队列的长度)为rear-front;若rear=front,则表示当前为空队列;若rear-front=MAXSIZE时,则表示当前为满队
4.顺序队的基本操作
1)类型说明
typedef int ElemType;
typedef struct SquenceQueue
{
ElemType data[MAXSIZE];
int front,rear;
}SqQueue;
2)初始化
构建一个空顺序队列q,将front和rear“指针”均设置为-1
void InitQueue(SqQueue* &q)
{
q=(SqQueue*)malloc(sizeof(SqQueue));
q->front=q->rear=-1;
}
3)入队
bool enQueue(SqQueue*&q,ElemType e)
{
if(q->rear==MAXSIZE-1)
return false;
q->rear--;
q->data[q->rear]=e;
return true;
}
4)出队
bool deQueue(SqQueue*&q,ElemType e)
{
if(q->front==q->rear)
return false;
q->front++;
e=q->data[q->front];
return true;
}
5)销毁
void DestoryQueue(SqQueue *&q)
{
free(q);
q=NULL;
}
循环队列
1.循环队列
1)为避免顺序队列的假溢出发生,可以将整个数组空间变成一个首尾相接的圆环,即把data[0]接在 data[MAXSIZE-1]之后,称这种数组为循环数组。用循环数组表示的队列称为循环队列。
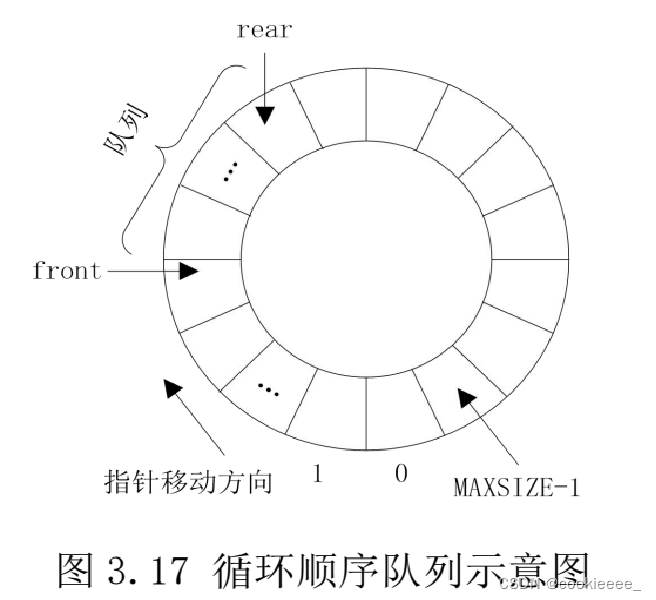
2)利用取余的“模运算”可以使循环队列的运算更加简洁。进行入队操作时,在循环队列中队尾指针加 1 的操作可描述为:rear = (rear+1)%MAXSIZE。同样,进行出队操作时,循环队列中队头指针加 1 的操作可描述为:front =(front+1)%MAXSIZE。
3)同顺序队列一样,队头指针指向的是队头元素的前一个位置
4)当循环队列的某个元素出队后,队头指针向前追赶队尾指针。若 front==rear,则循环队列为空队;当循环队列的某个元素入队后,队尾指针向前追赶队头指针,若 rear==front,则循环队列为满队。可见,队空的条件是 front==rear,队满的条件亦是 front= =rear。显然无法用条件 front==rear 判断和区分循环队列到底是“空队”还是“满队”。
5)解决:因此,采用牺牲一个存储单元的方法来解决这个问题:在循环数组中始终保留一个空闲单元不用。这样,判别循环队列是否为满队时,只要确定当前尾指针 rear 的下一个单元的位置是否为头指针 front 所指即可,即(rear+1)%MAXSIZE == front,若相同,则队满;否则,队不满。这样队满还是队空就可以区别开了。
2.基本操作
1)初始化
构建一个空循环队列q,将队头指针和队尾指针均设置为MAXSIZE-1
void InitCircleQueue(SqQueue*&q)
{
q=(SqQueue*)malloc(sizeof(SqQueue));
q->front=q->rear=MAXSIZE-1;
}
2)判断是否为空
bool CricleQueueEmpty (SqQueue*&q)
{
return q->front==q->rear;
}
3)入队
bool enCricleQueue(SqQueue*&q,ElemType e)
{
if((q->rear+1)%MAXSIZE==q->front) //队满、上溢出
{
return false;
}
q->rear=(q->rear+1)%MAXSIZE; //队尾指针加1
q->data[q->rear]=e; //rear位置上插e
return true;
}
4)出队
若循环队列q为空,则返回false,否则将队头指针front=(front+1)/MAXSIZE,将该位 置元素值赋给引用型参数e,返回true。其算法如下:
bool deCricleQueue(SqQueue*&q,ElemType e)
{
if(q->front==q->rear) //队空、下溢出
{
return false;
}
q->front=(q->front+1)%MAXSIZE; //队头指针加1
e=q->data[q->front];
return true;
}
5)销毁
void DestroyCricleQueue(SqQueue*&q)
{
free(q);
q=NULL;
链队列
1.定义
队列的链式存储结构称为链队列,通常用单链表来存储队列中的元素。
2.链队列示意图
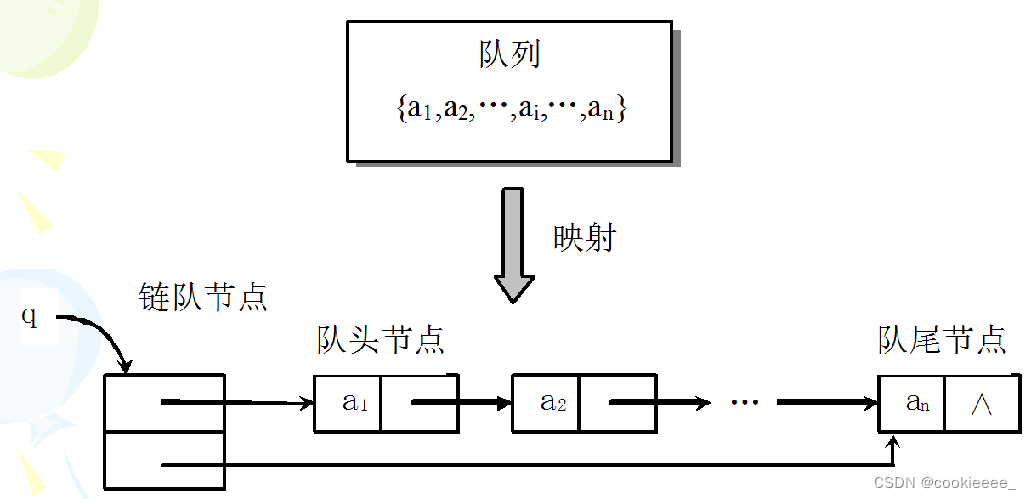
3.基本操作
1)链队列类型定义
typedef int ElemType;
typedef struct DataNode
{
ElemType data;
struct DataNode *next;
} DataNode;
2)初始化
两个指针front和rear都指向空
void InitQueue(LinkQuNode *&q)
{
q=(LinkQuNode *)malloc(sizeof(LinkQuNode));
q->front=q->rear=NULL;
}
3)判断是否为空
bool QueueEmpty(LinkQuNode *q)
{
return(q->rear==NULL);
}
4)入队
使用尾插法
void enQueue(LinkQuNode *&q,ElemType e)
{ DataNode *p;
p=(DataNode *)malloc(sizeof(DataNode));
p->data=e;
p->next=NULL;
if (q->rear==NULL) //若链队为空,则新结点是队首结点又是队尾结点
q->front=q->rear=p;
else
{ q->rear->next=p; //将p结点链到队尾,并将rear指向它
q->rear=p;
}
}
5)出队
bool deQueue(LinkQuNode *&q,ElemType &e)
{ DataNode *t;
if (q->rear==NULL) //队列为空
return false;
t=q->front; //t指向第一个数据结点
if (q->front==q->rear) //队列中只有一个结点时
q->front=q->rear=NULL;
else //队列中有多个结点时
q->front=q->front->next;
e=t->data;
free(t);
return true;
}
5)销毁队列
void DestroyQueue(LinkQuNode *&q)
{
DataNode *pre=q->front,*p;//pre指向队首结点
if (pre!=NULL) //释放数据结点占用空间
{ p=pre->next;
while (p!=NULL)
{ free(pre);
pre=p;p=p->next;
}
free(pre);
}
free(q); //释放头结点占用空间
}
错题
1.若用一个大小为6 的数组来实现循环队列,且当前rear 和front 的值分别为5和3,从当前队列中删除一个元素,再入队两个元素后,rear和front的值分别为( )。
- A、1 和5
- B、0和4
- C、4 和2
- D、5 和l
2.循环队列是否可以插入一个新的元素与队头指针和队尾指针的值有关
3.栈必须用数组来表示 X
4.栈与队列是特殊操作的线性表
5.循环队列也存在空间溢出问题
6.栈和链表是两种不同的数据结构
数组
多维数组的定义
数组的逻辑结构
1.n维数组可以看作是由多个n-1维数组组成
2.c语言实现数组的存储方式和数组这种数据类型的本质相同,有以下特性:
1)数组元素个数在定义时就被确定
2)数组的元素可以是任意类型,但每个元素的数据类型必须相同
3)唯一确定的下标访问数组中的任意元素
数组的物理结构
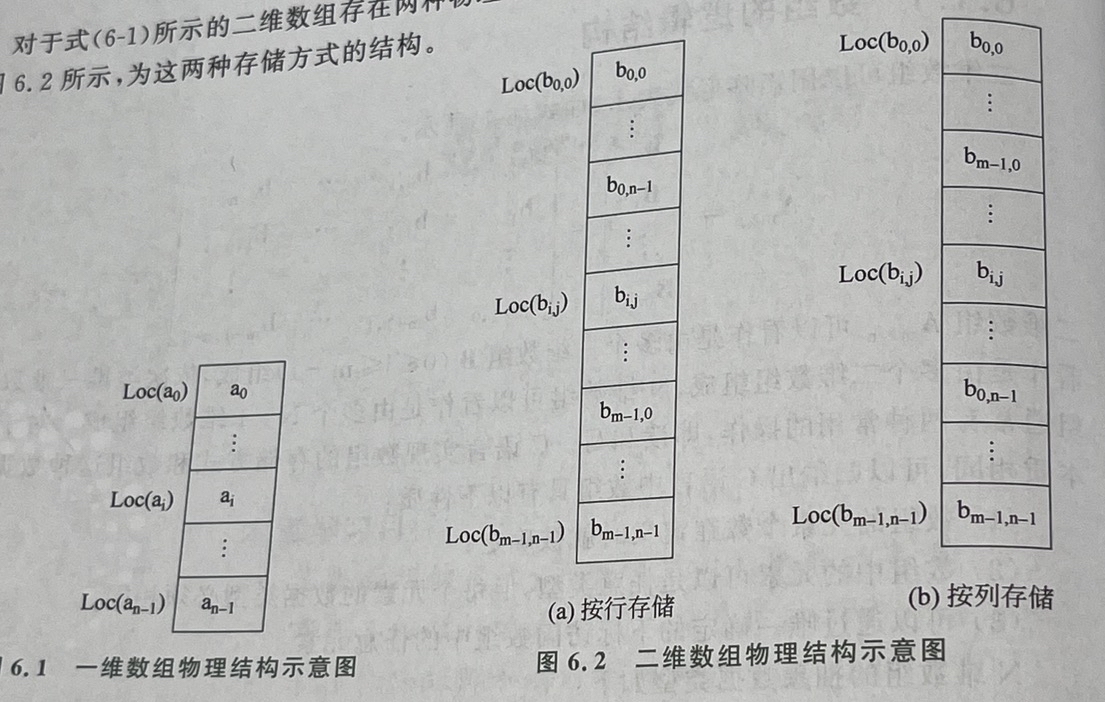
1)一维数组的物理结构:
A={a0,a1,....,ai,......,an-1}
元素地址计算公式: 单元地址+前面的元素个数*存储单位
i:代表ai前有i个元素,q:是每个数据元素需要q个单位来存储,Loc:该单元的地址
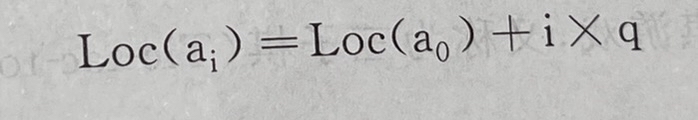
2)二维数组的物理结构 :按行存储;按列存储

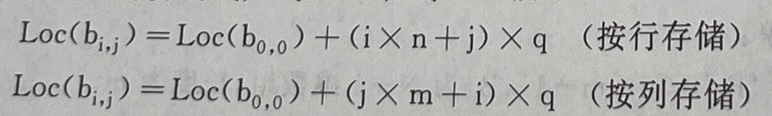
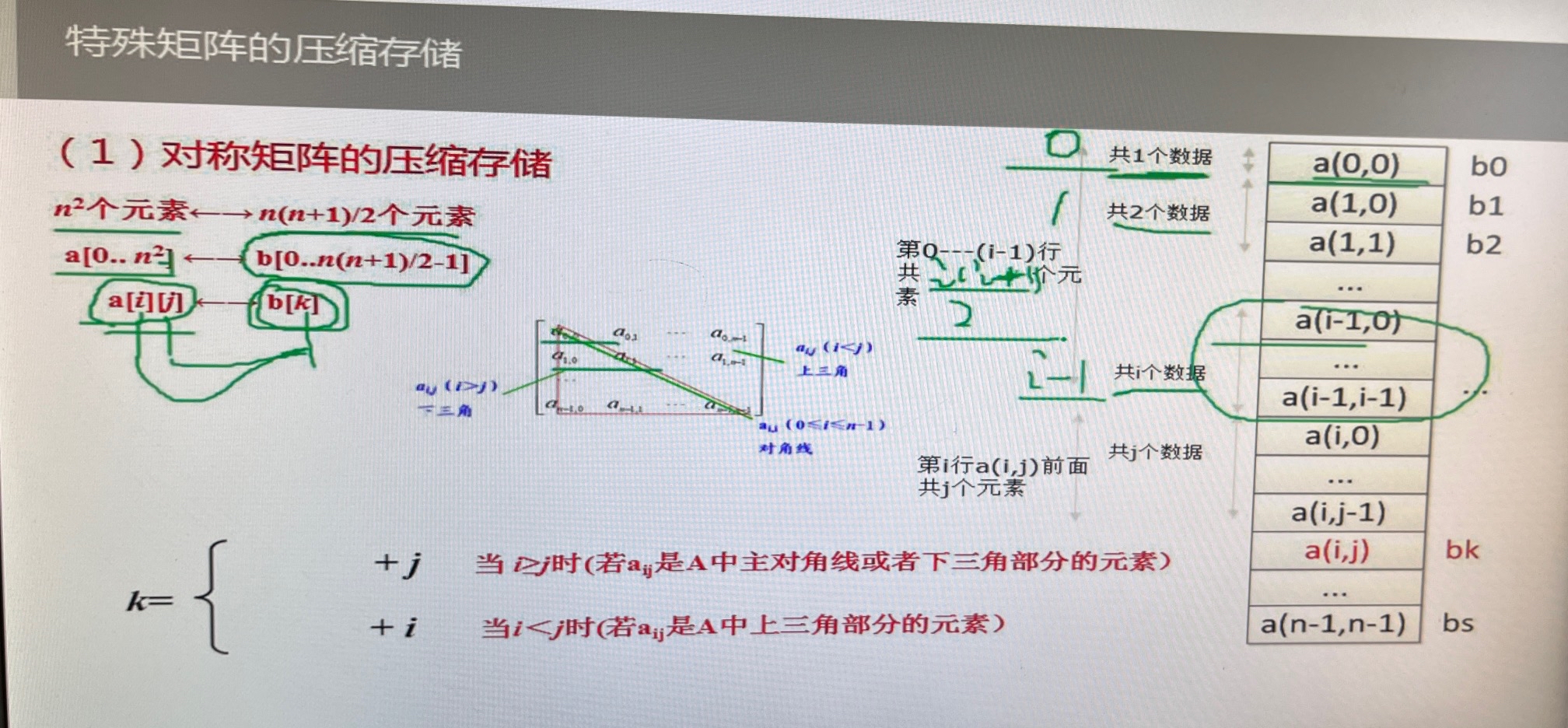
对称矩阵
满足ai,j=aj,i
对称矩阵压缩储存


三角矩阵
下三角矩阵


Ck(0<=k<=n(n+1)/2)表示一维数组的元素,也是n阶下三角矩阵压缩所需的存储单元个数
上三角矩阵

稀疏矩阵
1.三元组
是指非零元素的行序号、列序号以及元素值
2.对该矩阵进行压缩存储后,将会失去随机存储功能

总结
1.一维数组求地址公式:Loc(ai)=Loc(a0)+i*q; (i是ai前有几个元素,q是每个数据元素所需要的单元个数)
2.二维数组求地址公式:按行存储:Loc(bi,j)=Loc(b0,0)+(i*n+j)*q,bi,j在二维数组bm,n中
3.对称矩阵:共需要n*(n+1)/2个元素,一维数组C[n*(n+1)/2]来保存下三角和对角线元素
求地址公式:i>=j元素处于下三角或对角线中:k=i*(i+1)/2+j
i<j元素处于上三角中: k=j*(j+1)/2+i
4.上三角矩阵:用一个一维数组C[n*(n+1)/2]上三角元素+常数(下三角元素)
求地址公式:i>=j元素处于下三角或对角线中:k=i*(2n-i+1)/2+j-1
i<j元素处于上三角中: k=n*(n+1)/2
5.下三角矩阵:用一个一维数组C[n*(n+1)/2]下三角元素+常数(上三角元素)
求地址公式:i>=j元素处于下三角或对角线中:k=i*(i+1)/2+j
i<j元素处于上三角中: k=n*(n+1)/2
6.对角矩阵:n阶对角矩阵共有m条对角线存在非零元素
共需存储单元合个数:((2n-(m-1)/2)*(m+1)/2) - n
求地址公式:k=2i+j
广义表

错题
假设以行序为主序存储二维数组A=array[1..100,1..100],设每个数据元素占2个存储单元,基地址为10,则LOC[5,5]=( )。
- A、808
- B、818
- C、1010
- D、1020
A=array[1..100,1..100]是从1开始的,一行有100个元素,LOC[5,5]其行为4、列为4,所以就是100*4*2+10
树与二叉树
数和二叉树都是非线性特性
树
定义
1.树:是由n(n ≥ 0)个结点组成的有限集合(记为T)。
(1)若n=0,称该树为空树;
(2)若n>0,则该树有且仅有一个称为根(Root)的结点,除根结点外,其他与根结点相连的m(m≥0)个互不相交的结点构成了有限集合T1,T2,…,Tm,其中每个集合本身又是一棵树,每个集合称为根的子树;
(3)树是一种递归的数据结构。
2.性质:结点=度之和+1
3.逻辑表示方法:
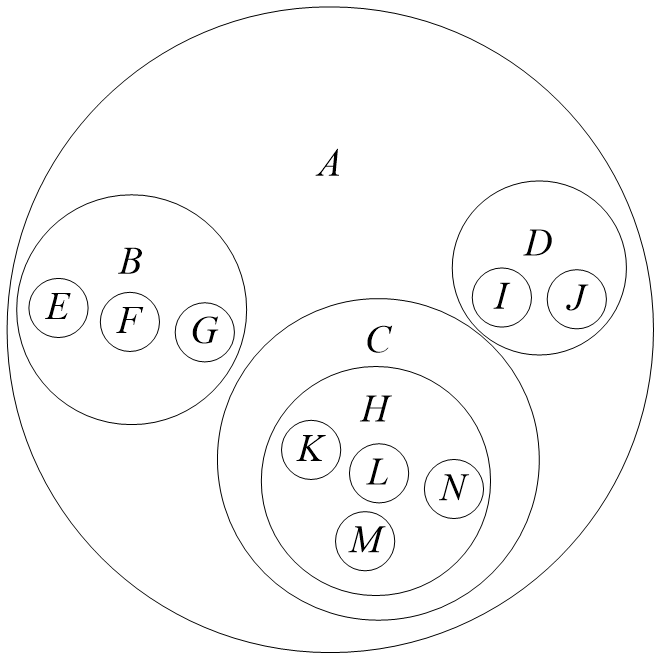
(1)嵌套集合表示法:是集合的集合,其中任意两个集合,或者不相交,或者一个包含另一个。每个圆圈表示一个集合,套起来的圆圈表示包含关系。
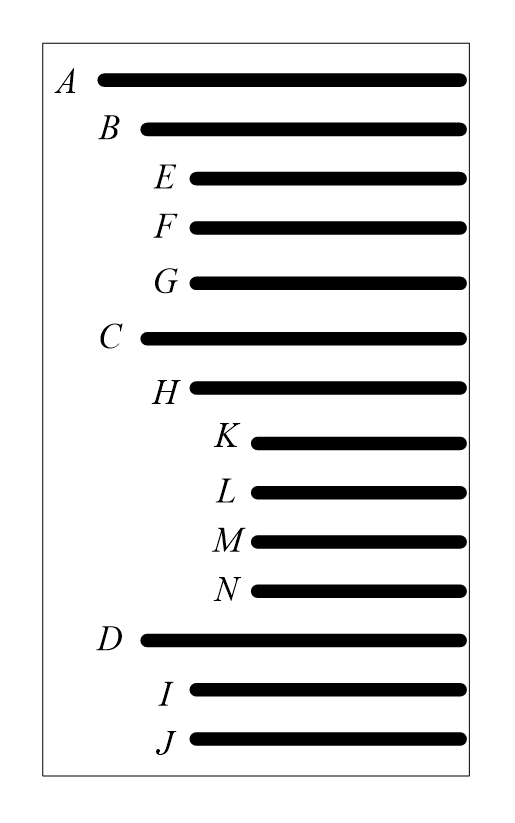
(2)凹入法:用不同长度的线段表示各结点,根结点长度最长,而线段的凹入程度体现了各结点之间的包含关系。如图7.3(b)所示。
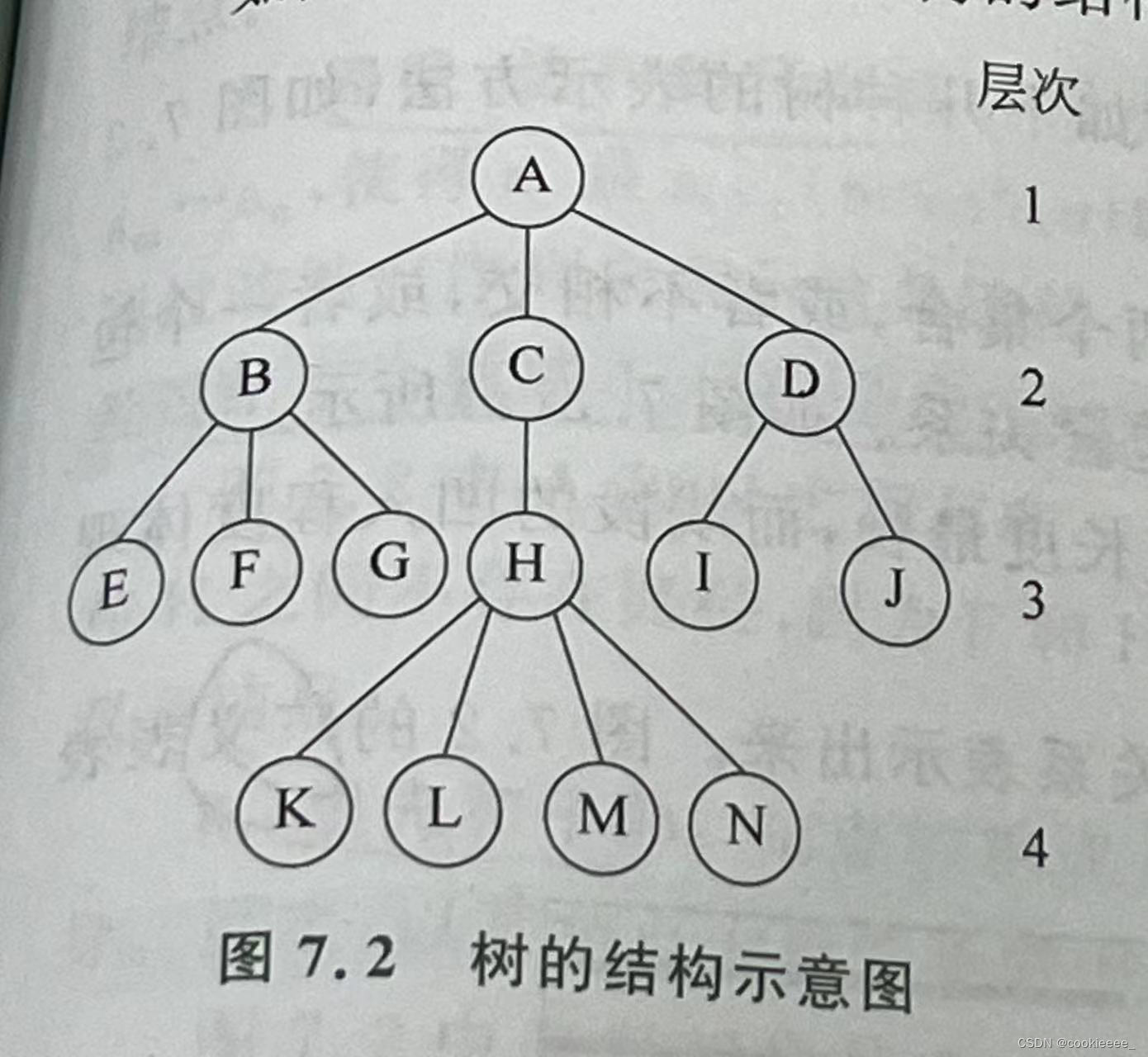
(3)广义表表示法:使用小括号将集合层次和包含关系表示出来。图7.2的广义表表示法为:A ( B ( E , F , G ) , C ( H ( K , L , M , N ) ) , D ( I , J ) )。
术语

二叉树
定义
1.定义:
在有序树中有一种特殊的树,称为二叉树。二叉树是实际应用最广泛的树形结构。 二叉树是有限的结点的集合。
(1)这个集合或者是空,称为空二叉树;
(2)或者有且仅有一个根结点;
(3)树中每个结点最多只有两个子树(即树的度小于等于2),并且子树有左右之分,次序不能互换;
(4)二叉树是一种递归的数据结构。
2.二叉树的形态
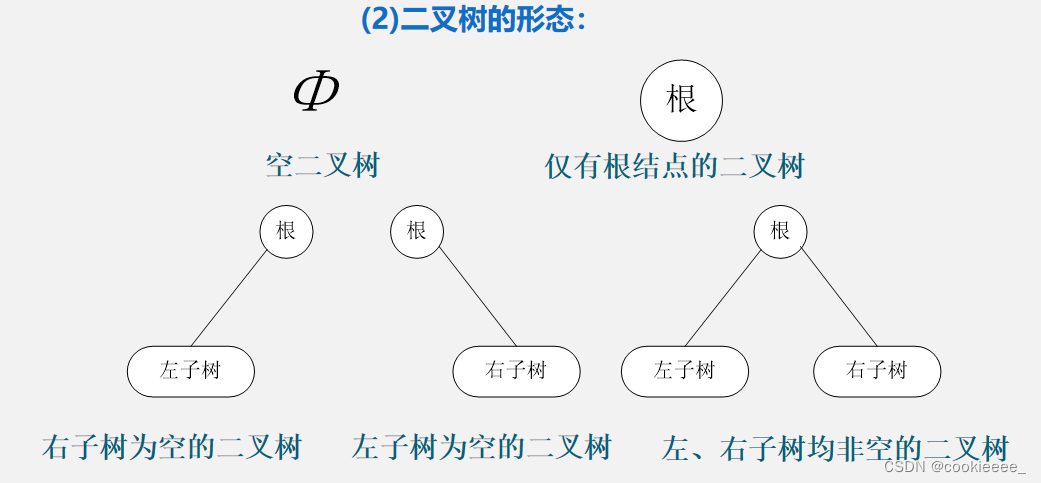
3.树与二叉树的区别
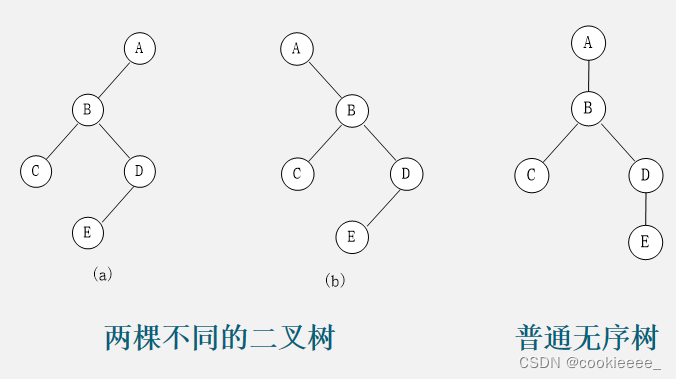
二叉树要
![]()
明确指出该子树是左子树还是右子树
4.满二叉树和完全二叉树
在一棵二叉树中,如果所有分支结点都有左孩子结点和右孩子结点,并且叶子结点都集中在二叉树的最下一层,这样的二叉树称为满二叉树。
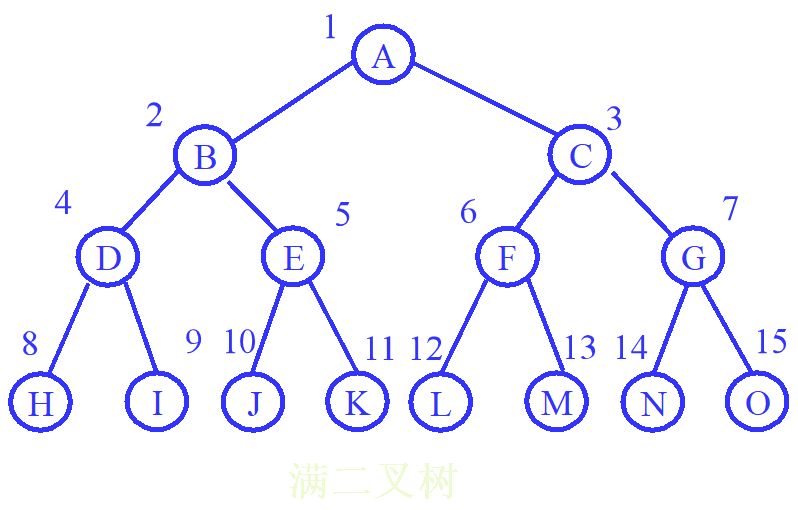
非空满二叉树的特点
所有分支结点都有左孩子和右孩子 、没有单分支结点、叶子结点的层数都等于树的深度
完全二叉树
除最后一层外,其余各层都是满的;而最后一层或者是满的,或者从最右边开始缺少若干个连续结点
完全二叉树的叶子结点只能出现在最大的两层上。若完全二叉树的分支结点没有左孩子结点,则它一定没有右孩子结点
满二叉树一定是完全二叉树,反之不一定
性质
1.满二叉树的第i层有几个结点 :
2.高度为h的满二叉树共有几个结点:
3.满二叉树共有n个结点,高度为多少:
4.高度为h的满二叉树共有多少分支节点:
叶子节点:
分支节点+1=叶子节点
5.叶子节点都在最下一层
6.只有度为0和度为2的结点
7.设深度为k的二叉树上只有度为0和度为2的节点,则这类二叉树上所含结点总数最少(2k-1)个
遍历二叉树
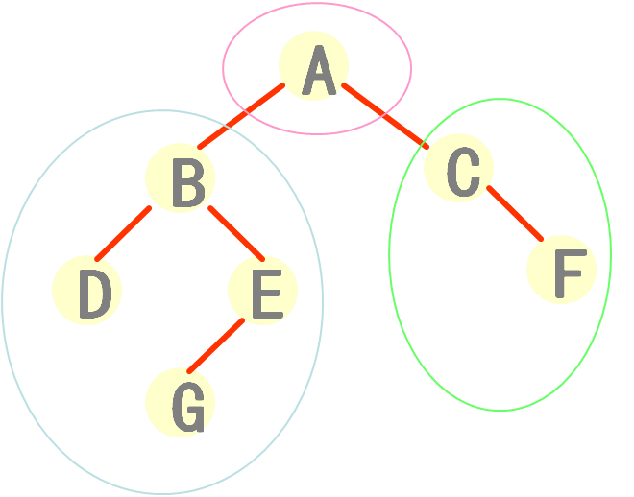
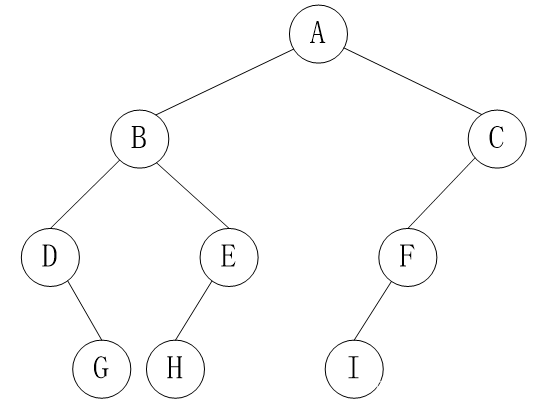
先序遍历
若二叉树非空: (1)访问根结点; (2)先序遍历左子树; (3)先序遍历右子树;
例:先序遍历右图所示的二叉树
(1)访问根结点A
(2)先序遍历左子树:即按DLR的顺序遍历左子树
(3)先序遍历右子树:即按DLR的顺序遍历右子树
先序遍历序列:A,B,D,E,G,C,F
中序遍历
若二叉树非空: (1)中序遍历左子树; (2)访问根结点; (3)中序遍历右子树;
例:中序遍历右图所示的二叉树
(1)中序遍历左子树:即按LDR的顺序遍历左子树
(2)访问根结点A
(3)中序遍历右子树:即按LDR的顺序遍历右子树
中序遍历序列: D,B,G,E,A,C,F
后序遍历
若二叉树非空: (1)后序遍历左子树; (2)后序遍历右子树; (3)访问根结点;
例:后序遍历右图所示的二叉树
(1)后序遍历左子树:即按LRD的顺序遍历左子树
(2)后序遍历右子树:即按LRD的顺序遍历右子树
(3)访问根结点A
后序遍历序列: D,G,E,B,F,C,A
层次遍历
按照自上而下(从根结点开始),从左到右(同一层)的顺序访问二叉树的所有结点,这样的遍历称为按层次遍历。
如图所示的二叉树的层次遍历序列为:ABCDEFGHI
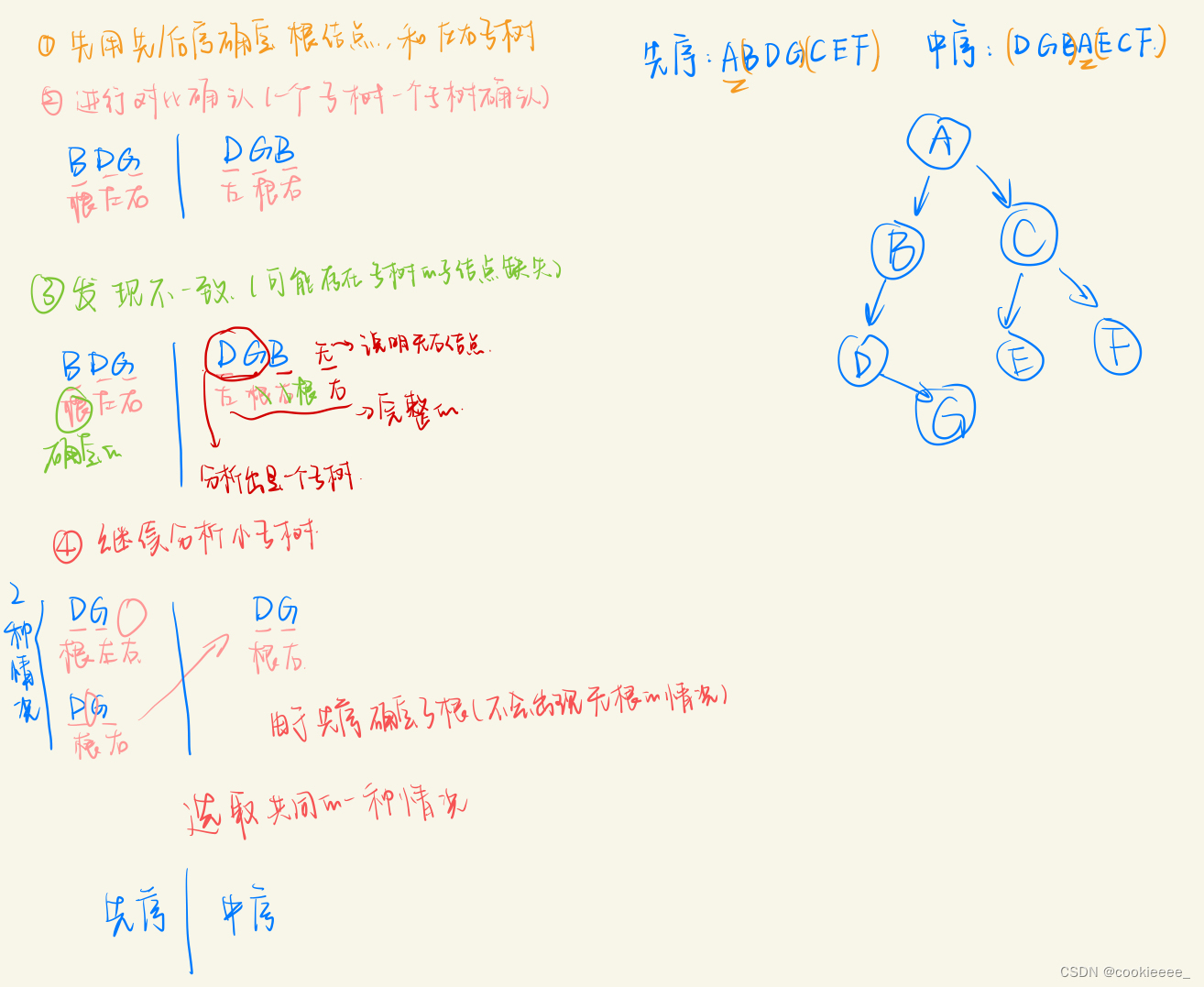
同时给定一颗二叉树的先/后序序列和中序序列就能唯一确定这颗二叉树
例如,已知先序序列为ABDGCEF,中序序列为DGBAECF,构造二叉树的过程:
补充
在二叉树结点的前序序列、中序序列和后序序列中,所有叶子结点的相对先后顺序(完全相同)
树和森林
讨论树、森林和二叉树的关系,目的是为(将树、森林按二叉树的存储方式进行存储)
树和二叉树的转换
通常树是无序树,树中兄弟结点是没有次序的;而二叉树中的结点有左右之分。为了进行二者之间的转换,约定树中兄弟结点;
转换时,将树中双亲结点的长子作为其左子树的根结点,将其他的孩子结点作为左子树的右子树,整个过程分为三步:
1.连线——使用线段连接兄弟结点;
2.删线——保留长子与双亲结点的连线,删除其他孩子结点与双亲结点的连线;
3.旋转——以根结点的长子为轴心,将整棵树顺时针旋转45度,使之结构层次分明。
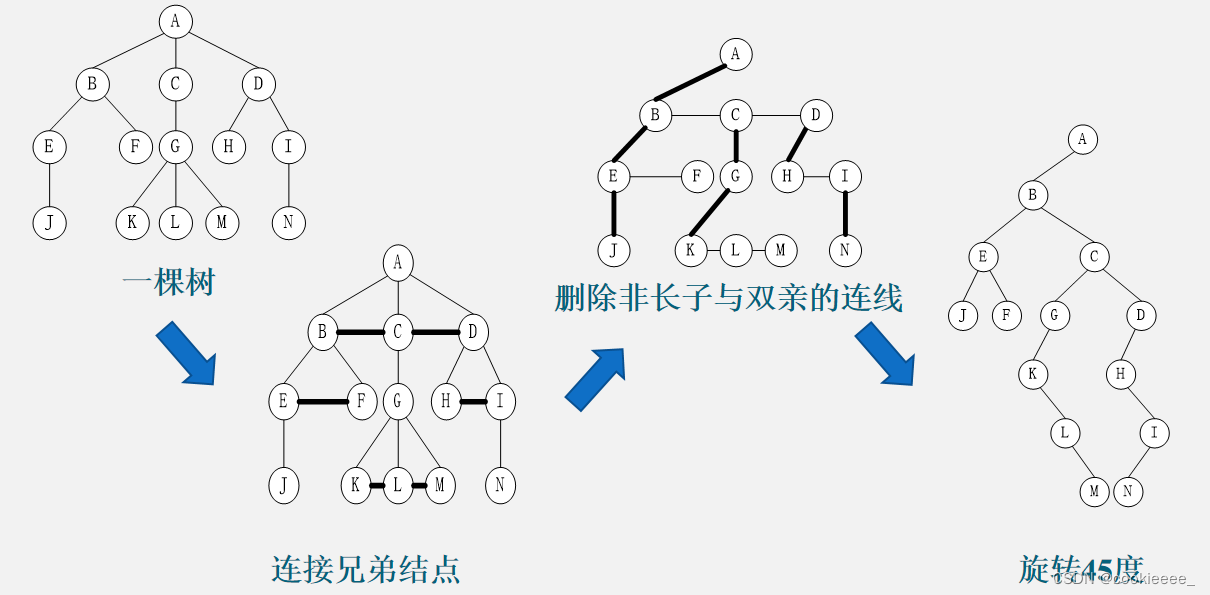
由上面的转换可以得出以下结论:
1.由于根结点没有兄弟,所以转换后二叉树的根结点必定没有右子树。
2.在转换的二叉树中,左分支上的各结点在原树中是父子关系;而右分支上的各结点在原树中是兄弟关系。
3.树转换为二叉树后,通常会使树的深度增加。
森林和二叉树的转换
森林是由若干棵树组成的。将每棵树的根结点看成是兄弟结点,而每一棵树可以转换为其对应的二叉树。
森林转换为二叉树的过程如下:
1. 将森林中每一棵树转换为二叉树
2. 取第一棵二叉树的根结点作为森林转换的二叉树的根结点,第一棵二叉树保持不变,从第二棵二叉树开始,依次把后一棵二叉树的根结点作为前一棵二叉树根结点的右子树,直到最后一棵二叉树为止。
删右孩子、连接左孩子、转角度
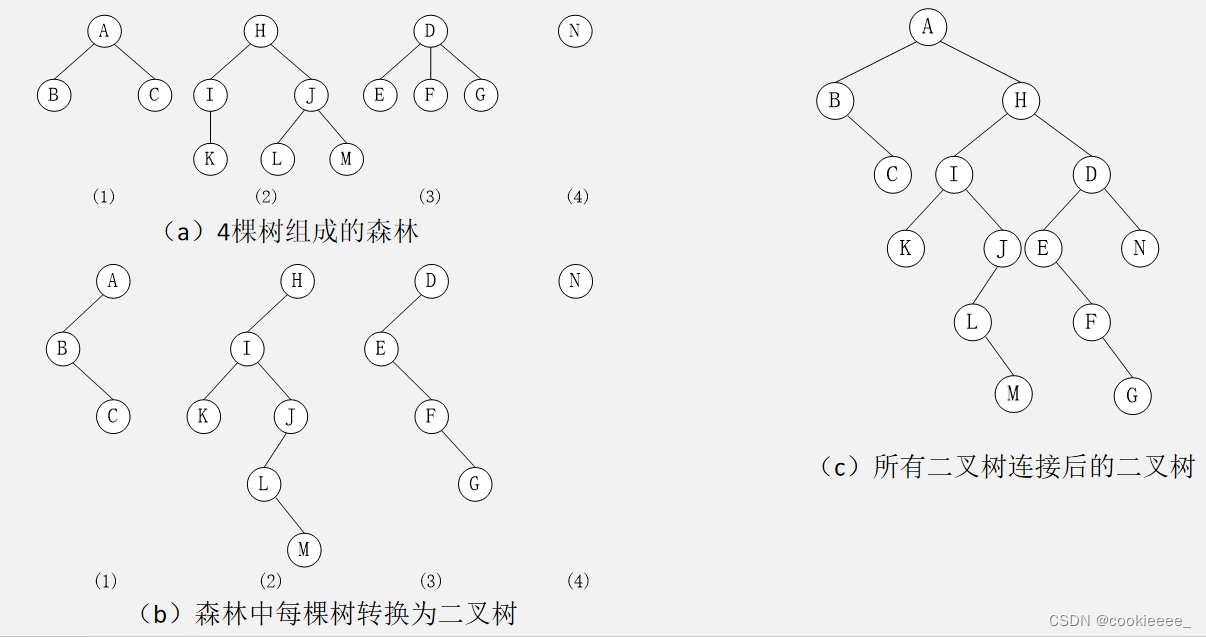
二叉树还原为树、森林
因为一棵非空树转换为二叉树时,其根结点一定没有右子树;而森林转换为二叉树后,根结点存在右子树。所以可以根据这个特点,将二叉树还原为树或森林。
二叉树转换为森林过程如下:
(1)对于一棵二叉树中任一结点x,若结点x是其双亲结点y的左孩子,则把结点x的右孩子、右孩子的右孩子,……,都与结点y用连线连接起来;
(2)删除所有双亲到右孩子之间的连线;
(3)将图形规整化,使各结点按层次排列。
连兄弟结点、删长子、转角度
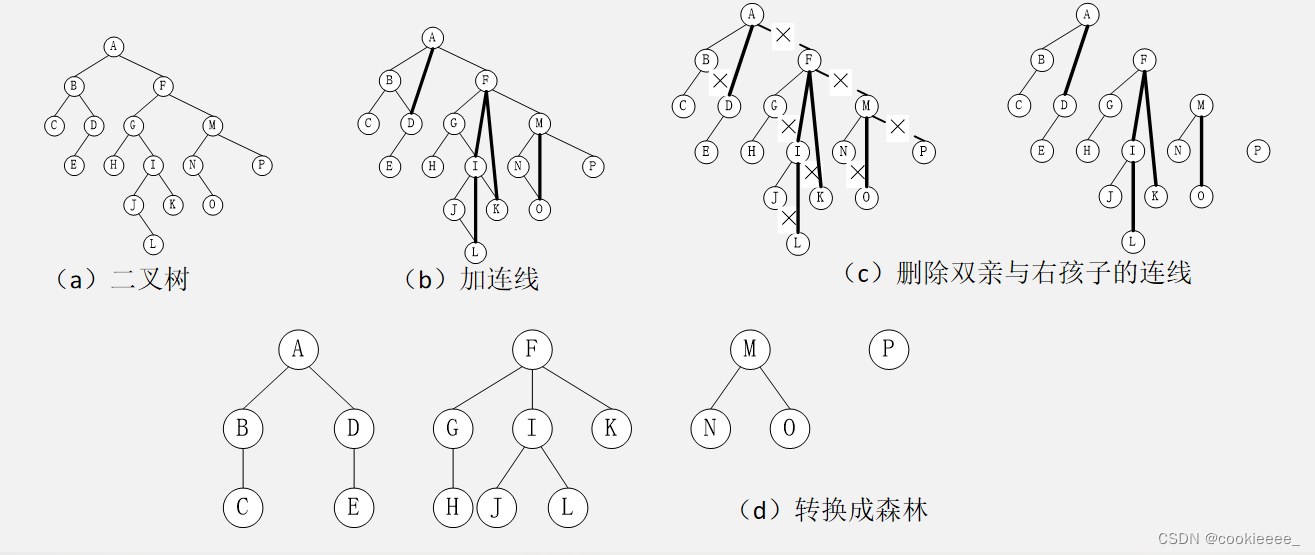
树的遍历
树的遍历
树的深度遍历
由于普通树是无序树,没有规定兄弟节点之间的次序,所以假设根的孩子节点按照从左到右的次序为第一颗子树的根、第二颗子树的根等。
特点
二叉树的先根遍历和其对应的树的先根遍历序列相同
二叉树的后根遍历和其对应的树的中根遍历序列相同
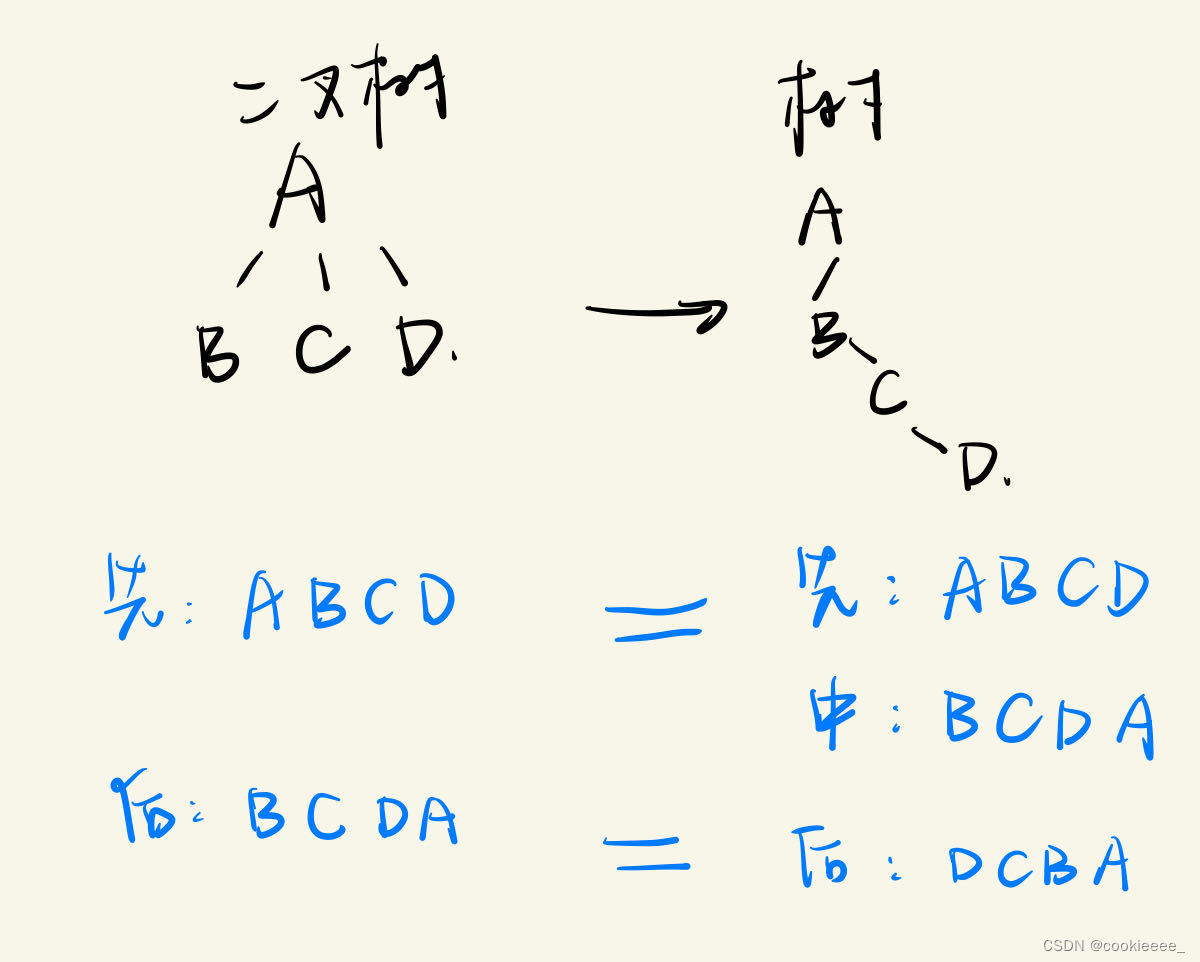
(1)树的先根遍历
若树为非空,则树的先根遍历顺序如下:
①访问树的根结点; ②先根遍历根的第一棵子树; ③先根遍历根的剩余子树。
(2)树的后根遍历
若树为非空,则树的后根遍历顺序如下:
①后根遍历根的第一棵子树;
②后根遍历根的剩余子树;
③访问树的根结点。
由于树的度不一定为2,树的子树往往多于2,所以中序遍历不便讨论
树的广度遍历
若树为非空,则树的广度遍历顺序如下:
①首先访问树的根结点;
②按照从左到右的次序访问第二层的所有结点;
③按层次逐层向下访问,直到所有结点都被访问为止。
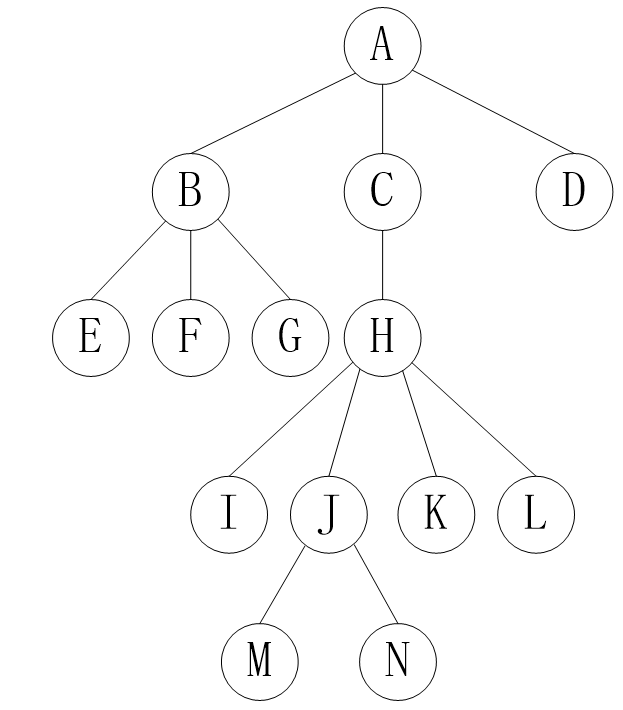
树的先根遍历:ABEFGCHIJMNKLD
树的后根遍历:EFGBIMNJKLHCDA
树的广度遍历:ABCDEFGHIJKLMN

哈夫曼树
基本概念
(1)路径:在一棵树中,从一个结点到另一个结点之间所经过的分支。
(2)路径长度:两个结点之间路径所包含的分支的个数。
(3)结点的权:树中的结点所表示的值。
(4)结点的带权路径长度:从根结点到该结点之间路径长度乘以结点的权值。
(5)树的带权路径长度:所有叶子结点的带权路径长度之和。通常用WPL表示,对应公式为:
![]()
WK表示第k个叶子结点的权值; Lk表示第k个叶子结点到根结点的路径长度。
(6)哈夫曼树:在n个带权叶子结点构造的所有二叉树中,带权路径长度最小的二叉树称为哈夫曼树或最优二叉树。
构建二叉树
已知n个结点的权值的集合为{W1,W2,……Wn}
(1)根据n个权值的集合 {W1,W2,……Wn},将n个结点看成n棵只有根结点的二叉树T={T1,T2,……Tn}组成的森林,每棵二叉树Ti (1≤i≤n)都只对应一个结点权值为Wi ,其左、右子树均为空。
(2)在森林中选出根结点权值最小的二叉树作为左、右子树构成一棵新的二叉树,新二叉树的根结点的权值等于左、右子树根结点权值之和。
(3)从森林T中删除上面选择的两棵二叉树,将新生成的二叉树加到森林T中。
(4)重复步骤(2)(3),直到森林T中只有一棵二叉树为止,这棵二叉树就是所要创建的哈夫曼树。
一般习惯结点权值小的作为左孩子,权值大的作为右孩子。
哈夫曼编码

例题
【例】假设某系统用于通信的电文仅由字符集{a,b,c,d,e,f,g,h}8个字母组成,这8个字母在电文中出现的频率分别为{0.19, 0.21, 0.02, 0.03, 0.06, 0.07, 0.1, 0.32}。 (1)画出由这些结点所构成的哈夫曼树(结点权值小的作为左孩子,权值大的作为右孩子); (2)计算此树的带权路径长度WPL; (3)写出8个字符的哈夫曼编码(结点左分支编码为0,右分支编码为1)。
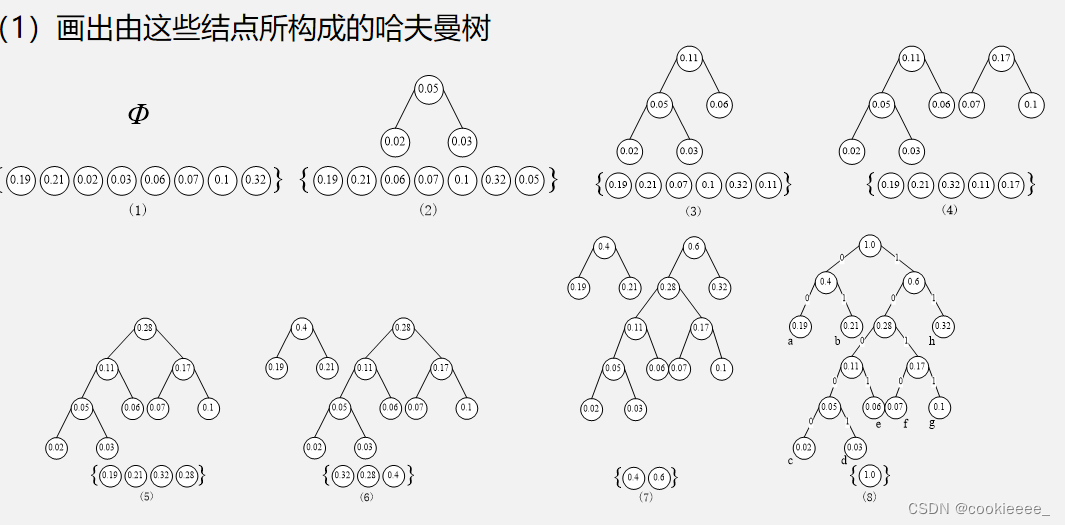
(2)计算此树的带权路径长度WPL WPL=0.19×2+0.21×2+0.02×5+0.03×5+0.06×4+0.07×4+0.1×4+0.32×2=2.61
(3)写出8个字符的哈夫曼编码(结点左分支编码为0,右分支编码为1) 将每个结点的左分支编码为0,右分支编码为1。则每个字符的编码分别为a:00,b:01,c:10000,d:10001,e:1001,f:1010,g:1011,h:11。
错题
1.求叶子结点的个数
先求出总结点个数,按照给出的其他度数节点的个数,用前者减去后者

1.1关于树的度
树的度为n,代表最大度数为n,那么树的度数为1,2,3,,,,n

2.二叉树
2.1
①只有一个结点的二叉树的度为0;
②二叉树的左右子树不一定可任意交换;(有序树不可以,一般的树可以
③深度为K的完全二叉树的结点个数小于或等于深度相同的满二叉树。
2.2

2.3

2.4

2.5编号

3.树
3.1
树最适合用来表示 元素之间有分支的层次关系
3.2 三次树
三次树:树的度数为3

4.森林
4.1
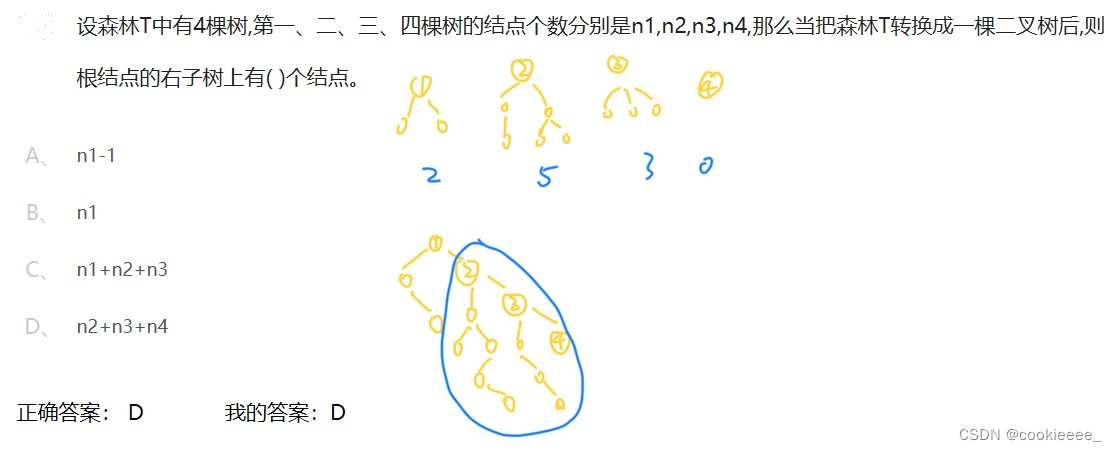
同理,根节点的左子树有(n1-1)个结点
5.哈夫曼树
5.1

5.2
A、一般在哈夫曼树中,权值越大的叶子离根结点越近
B、哈夫曼树中没有度数为1的分支结点
C、初始森林中共有n棵二叉树,最终求得的哈夫曼树共有2n-1个结点
D、初始森林中共有n棵二叉树,进行n-1次合并后才能剩下一棵最终的哈夫曼树
图
定义
图的定义:图(Graph)G由两个集合V(vertex)和E(Edge)组成,记为二元组表示G=(V,E),其中V是顶点的有限集合,记为V(G),E是连接V中两个不同顶点(顶点对)的边的有限集合,记为E(G)。
术语
1.顶点、边、弧(有向图中,点之间的连线)、终点/弧头(有箭头)、始点/弧尾
2.顶点的度、入度(以顶点为终点的弧的数目)和(以顶点为始点的弧的数目)出度、 TD(v)=ID(v)+OD(v) 2*边=度之和
3.无向完全图 边=n(n-1)/2
4.有向完全图 边=n(n-1)
5.稠密图和稀疏图
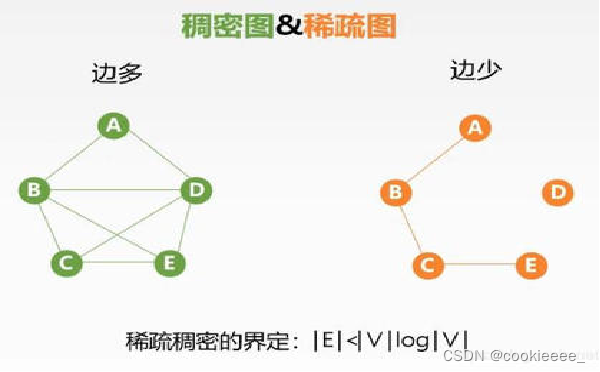
6.带权图(权值有某种含义)和网(边上带权的图),如果边是有方向的带权图,则是一个有向网图
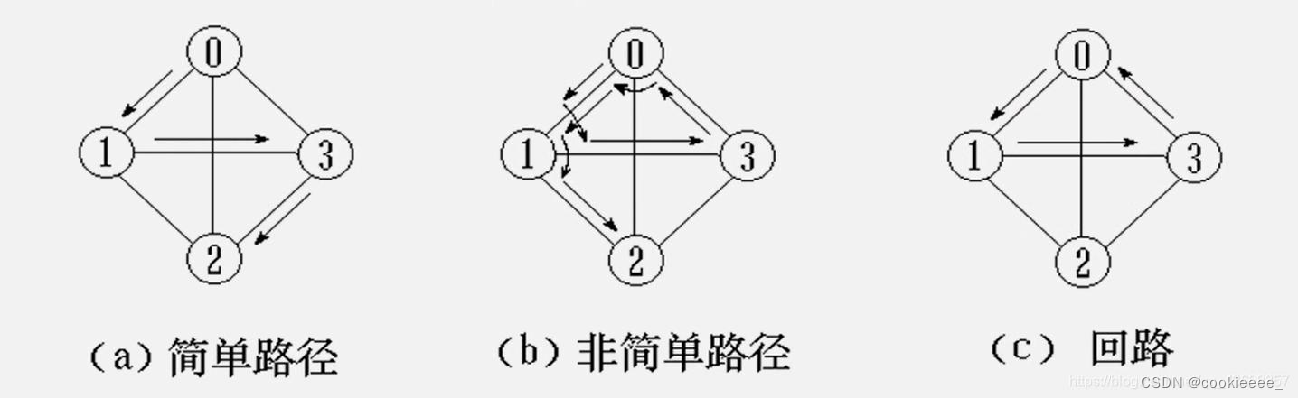
7.路径、路径长度(顶点数-1)
8.回路(vi到vi的路径称为简单路径)、简单路径(路径中顶点不重复出现的路径)、简单回路(除第一个顶点和最后一个顶点之外,其他顶点不重复出现)
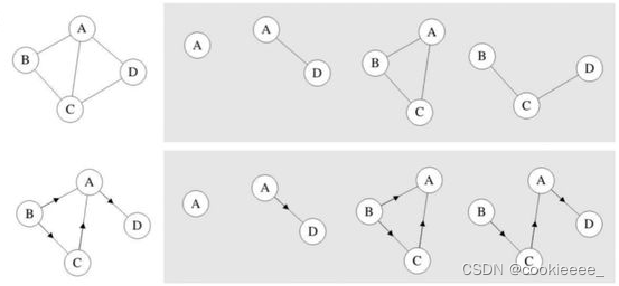
9.子图
对于图G=(V,E),G'=(V',E'),存在V'是V的子集,E'是E的子集,则图G'是图G的子集
10.连通(从一个顶点到另一个顶点有路径)、连通图(任意两点都是连通的)和连通分量(无向图的极大连通图)
11.强连通图(任意一对顶点能互相到达且是有向图)和强连通分量(有向图的极大强连通子图)
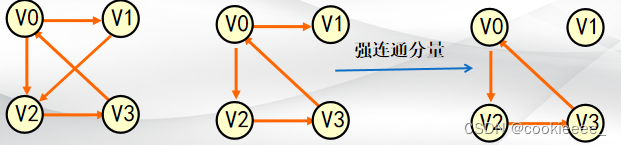
拓展:
1.由n个顶点构成一个连通图,最少需要n-1条边,最多需要n(n-1)/2条边
2.由n个顶点构成一个强连通图,最少需要n条边(回路),最多需要n(n-1)条边(完全图)
3.判断是否是强连通图判断其是否有回路即可
4.显然,任何连通图的连通分量只有一个即本身,而非连通图有多个连通分量
5.判断强连通分量:1)找是否有回路 2)加顶点,如果加了还是强连通图的话,就是连通分量,如果不是强连通图就不是强连通分量
图的存储关系
邻接矩阵
是顺序存储方式,就是用一维数组存储图中顶点的信息,用矩阵表示图中个顶点之间的关系

若是带权图:
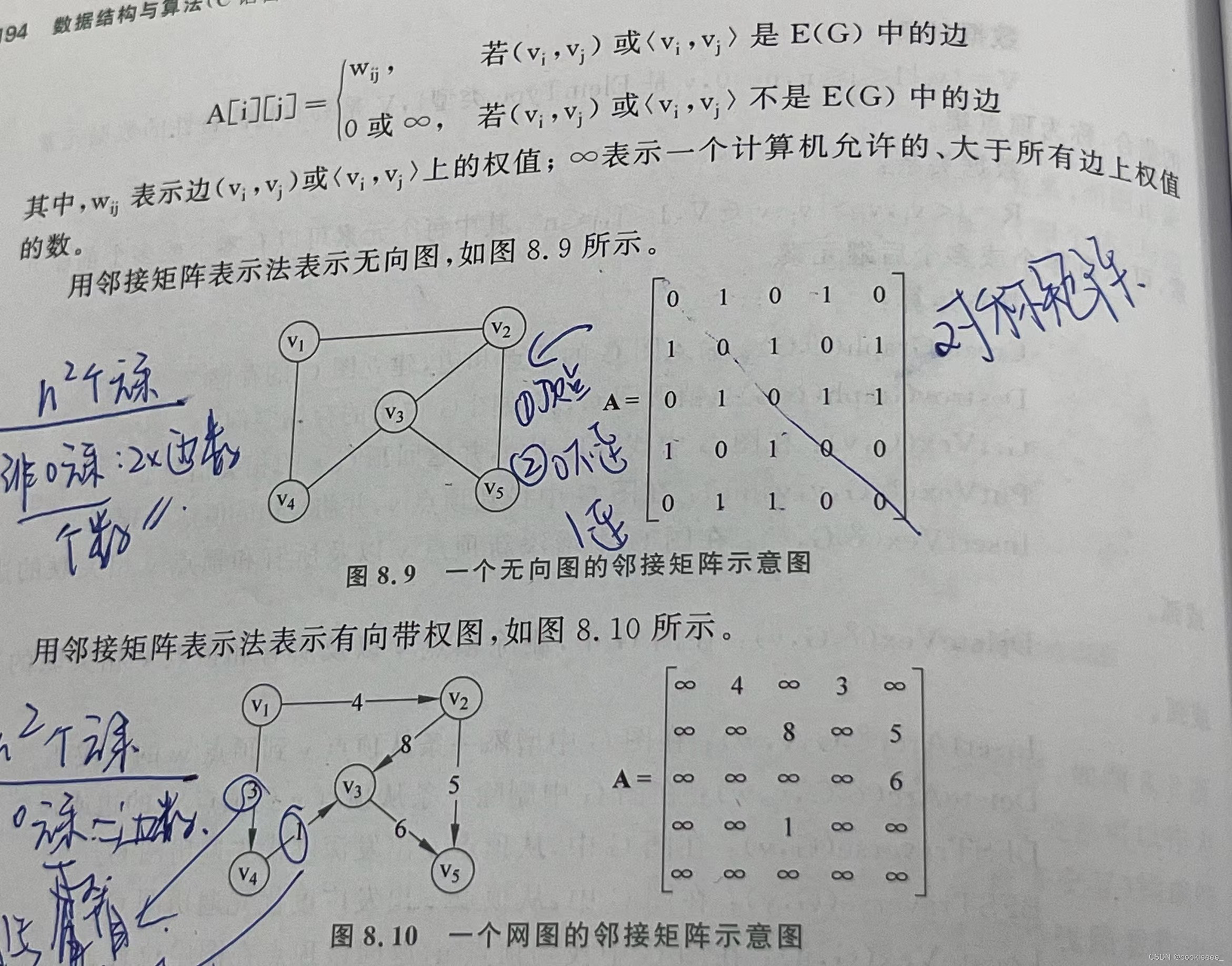
邻接存储方法的特点
1)无向图的邻接矩阵一定是一个对称矩阵,因此,在具体存放邻接矩阵时只需存放上(或下)三角矩阵的元素即可
2)对于无向图,邻接矩阵的第i行(或者第i列)非零元素的个数正好是第i个顶点的度TD(vi)
3)对于有向图,邻接矩阵的第i行(或者第i列)非零元素的个数正好是第i个顶点的出度或入度
邻接矩阵存储方法的优缺点
优点:
·直观、简单、好理解,方便检查任意一对顶点间是否存在边
·方便找任一顶点的所有“邻接点”(有边直接相连的顶点)
·方便计算任一顶点的“度”(从该点发出的变数为“出度”,指向该点的边数为“入度”)
缺点:
·不便于增加和删除顶点(增加一个顶点需要增加一行一列,删除一个顶点需要删除一行一列)
·不便于统计边的数目,需要扫描邻接矩阵所有元素才能统计完毕,时间复杂度为O(n^2)。
·浪空间复杂度高,邻接矩阵表示法的空间复杂度为O(n^2),这对于稀疏图而言尤其浪费空间
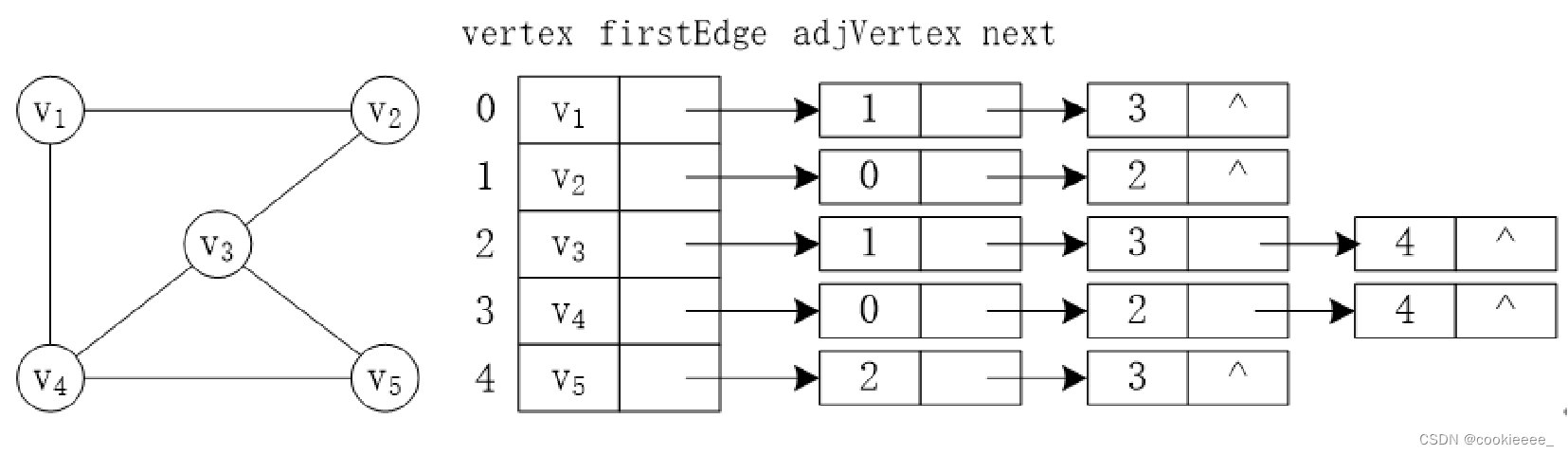
邻接表
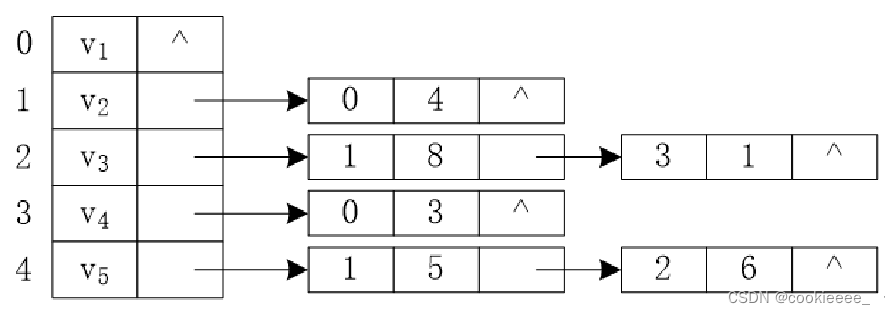
是图的一种顺序存储与链式存储结合的存储方法。对于图G中的每个顶点Vi,将所有邻接于vi的顶点vj链成一个单链表,这个单链表就称为顶点vi的邻接表,再将所有点的邻接表表头放在数组中,就成了图的邻接表。
无向图
在邻接表表示中有两种结点结构:
表头结点:
| 数据域(vertex) 存储顶点的信息 | 指针域(firstEdge) 用于指向链表中与vi邻接的第一个节点 |
边表结点:
| 邻接点数据域(adjVertex) 存储的是该邻接点的数组编号 | 指针域(firstEdge) 用于指向vi的下一个邻接点 |
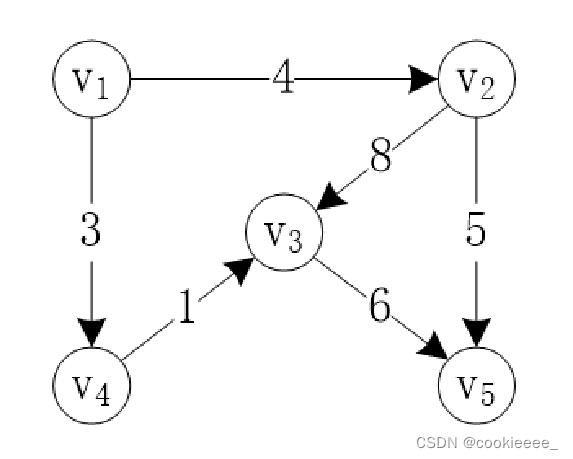
带权图的边表结点中间会加一个权值
有向图的逆邻接矩阵
| 数据域(vertex) 存储顶点的信息 | 指针域(firstEdge) 用于指向链表中指向vi的结点 |
时间复杂度
算法的时间复杂度是O(n+e)
特点
一个图的邻接矩阵表示是唯一的,但其邻接表表示不唯一,这是因为邻接表表示中,各边表结点的链接次序取决于建立邻接表的算法,以及边的输入次序。
优点:
1)便于增加和删除顶点。
2)便于统计边的数目,时间复杂度是O(n+e)
3)空间效率高
缺点:
1)不便于判断顶点之间是否有边
2)不便于计算有向图各顶点的度
图的遍历
深度优先搜索
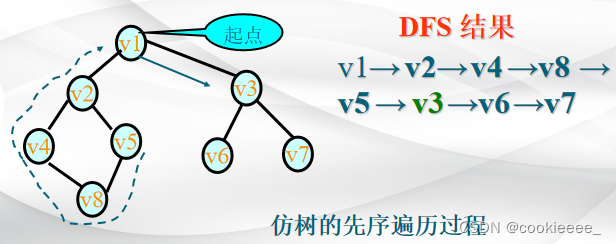
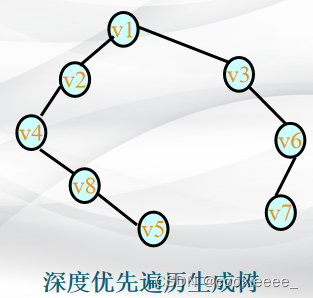
深度优先搜索遍历的过程是:
(1)从图中某个初始顶点v出发,首先访问初始顶点v。
(2)选择一个与顶点v相邻且没被访问过的顶点w为初始顶点,再从w出发进行深度优先搜索,直到图中与当前顶点v邻接的所有顶点都被访问过为止。
(3)返回前一个访问过的且仍有未被访问的邻接点的顶点,找出该顶点的下一个未被访问的邻接点,访问该顶点。
(4)重复步骤(2)和(3),直至图中所有顶点都被访问过,搜索结束。
广度优先搜索法
广度优先搜索遍历的过程:
(1)访问初始点v,接着访问v的所有未被访问过的邻接点v1,v2,…,vt。
(2)按照v1,v2,…,vt的次序,访问每一个顶点的所有未被访问过的邻接点。
(3)依次类推,直到图中所有和初始点v有路径相通的顶点都被访问过为止。
















 392
392











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









