







前言
在大数据时代,信息的获取能力在很大程度上决定了一个人或组织的竞争力。而网页数据爬取正是快速收集海量信息的重要手段。作为 Python 生态中最著名的爬虫框架之一,Scrapy 以其高效、模块化、易拓展的特点,成为众多开发者和数据工程师的首选工具。
本文将从 Scrapy 框架的整体结构出发,逐步解析它的核心组件与工作机制,并结合一个简单的实例,演示从网页抓取到数据处理的完整流程,帮助你系统地掌握 Scrapy 的使用方法。
1 Scrapy 框架概述
Scrapy 是一个基于 Python 编写的开源网页抓取框架,最初由 scrapinghub 公司开发。它最显著的特点是基于异步网络框架 Twisted 构建,天然支持高并发请求,使得在爬取大规模网站数据时依然具备优秀的性能。
与传统的脚本式爬虫不同,Scrapy 提供了一套完整的“抓取—处理—保存”流程,所有模块高度解耦,便于开发者灵活替换和配置。
1.1 Scrapy 的核心优势
Scrapy 能在实际项目中胜出的原因包括:
- 高效异步处理能力,支持上千并发请求;
- 清晰的工程结构,适合构建大型爬虫项目;
- 可插拔的中间件和管道机制,方便进行反爬处理和数据清洗;
- 强大的请求调度器与去重机制,自动避免重复请求;
- 支持多种数据导出格式,如 CSV、JSON、XML,甚至直接写入数据库。
1.2 Scrapy 的典型应用场景
Scrapy 广泛应用于以下领域:
- 电商网站商品信息抓取;
- 新闻聚合与内容监控;
- 房产、招聘等信息平台的数据采集;
- 舆情监控、竞品分析、价格跟踪等商业用途。
接下来我们将逐步分析 Scrapy 的内部架构和数据处理流程。
2 Scrapy 工作原理解析
Scrapy 的爬虫流程可以抽象为“请求 - 响应 - 解析 - 存储”的闭环。这一过程由多个模块协同完成,每个模块各司其职、相互衔接。
2.1 框架结构图
简化后的 Scrapy 执行流程如下:
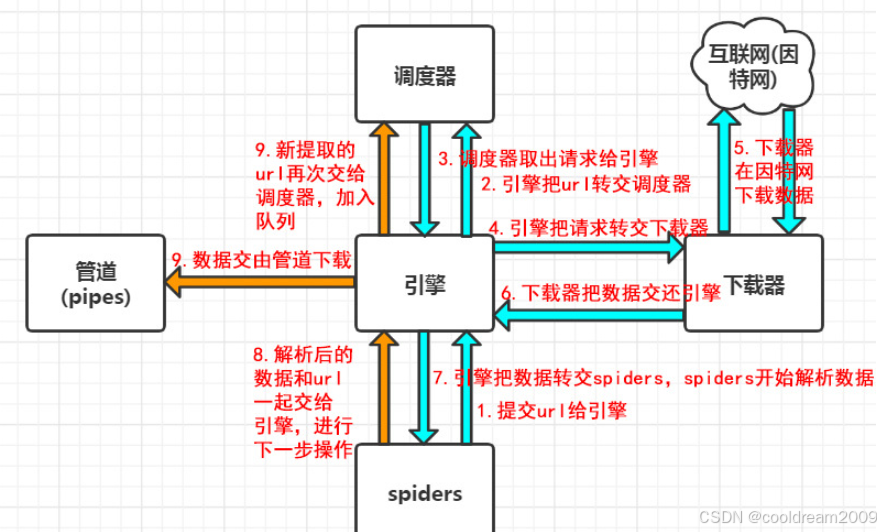
Spider → Scheduler → Downloader → Middleware → Response
↓ ↑
Item ← Pipeline ← [清洗/校验/存储]
下面我们从开发者视角,逐一介绍各模块的功能和作用。
2.2 Spider:定义数据采集策略
Spider 是 Scrapy 中的核心组件之一,用户主要通过它来定义抓取逻辑。每个 Spider 通常对应一个站点或抓取任务,指定起始 URL,并通过 parse 方法解析响应数据。
class MySpider(scrapy.Spider):
name = "example"
start_urls = ['http://example.com']
def parse(self, response):
yield {
'title': response.xpath('//title/text()').get(),
'url': response.url
}
Spider 接收到响应后,负责提取页面中的关键信息,并将其封装成 Item 对象,交由后续 Pipeline 处理。同时,也可以返回新的请求,形成递归抓取。
2.3 Scheduler:调度请求与去重
调度器(Scheduler)用于管理所有待请求的 URL,并决定下一个要发送的请求。Scrapy 内置了请求去重机制,避免多次抓取同一页面。
当 Spider 返回一个新的 Request 对象时,Scheduler 会先判断该请求是否已被抓取过,若没有则加入队列等待 Downloader 执行。
2.4 Downloader:网页下载器
Downloader 负责将请求发送至互联网,获取对应的响应结果。它是一个异步处理器,基于 Twisted 网络引擎运行,效率极高。
Scrapy 的 Downloader 可通过中间件自定义行为,例如设置 User-Agent、使用代理池、处理 Cookie 或实现验证码识别等。
2.5 Item:结构化数据容器
Item 类似于一个轻量级的数据模型,用于描述需要提取和保存的字段。它通常定义在 items.py 文件中:
import scrapy
class ArticleItem(scrapy.Item):
title = scrapy.Field()
url = scrapy.Field()
content = scrapy.Field()
Spider 会将页面中提取的数据填入 Item 中,交由 Pipeline 进一步处理。
2.6 Pipeline:数据清洗与存储
数据管道(Pipeline)主要处理来自 Spider 的数据,负责数据的验证、清洗、转换或保存到数据库等持久化操作。
class MyPipeline:
def process_item(self, item, spider):
item['title'] = item['title'].strip()
return item
Pipeline 可通过配置启用多个,每个数据项会按顺序通过各个 Pipeline 组件。
2.7 Middleware:请求与响应的拦截器
Downloader Middleware 和 Spider Middleware 是两个钩子点,用于拦截请求或响应进行修改。开发者可利用它实现诸如:
- 动态设置请求头;
- 自动切换 IP 代理;
- 实现断点续爬或重试机制;
- 模拟浏览器行为绕过反爬机制。
3 Scrapy 爬虫开发流程详解
Scrapy 项目开发结构清晰、流程规范。一个标准的 Scrapy 项目包含以下步骤:
3.1 创建项目
使用 Scrapy 提供的命令行工具初始化项目结构:
scrapy startproject myproject
生成的目录包含 spiders/、items.py、pipelines.py、settings.py 等模块,便于模块化开发。
3.2 编写 Item 类
在 items.py 中定义所需的数据字段,便于统一管理与导出格式。
3.3 编写爬虫逻辑
在 spiders/ 目录下创建爬虫文件,并继承 scrapy.Spider 或 CrawlSpider 类,定义初始 URL 和解析逻辑。
3.4 配置 settings 参数
在 settings.py 文件中配置项目参数,包括:
USER_AGENT:设置请求头标识;DOWNLOAD_DELAY:请求延时,防止被封;ITEM_PIPELINES:启用数据处理管道;DOWNLOADER_MIDDLEWARES:启用中间件。
例如:
USER_AGENT = 'Mozilla/5.0'
DOWNLOAD_DELAY = 1.0
ITEM_PIPELINES = {
'myproject.pipelines.MyPipeline': 300,
}
3.5 启动爬虫
使用以下命令运行爬虫:
scrapy crawl example
如果需要将数据导出为 CSV 文件:
scrapy crawl example -o output.csv
3.6 数据持久化
Scrapy 支持多种数据输出方式,如 CSV、JSON、MongoDB、MySQL 等。Pipeline 中可以根据需求将 Item 写入数据库或上传至云端。
4 实战案例:抓取豆瓣电影 Top250
下面以豆瓣 Top250 为例,展示 Scrapy 的完整应用流程。
4.1 页面分析
目标站点:https://movie.douban.com/top250
每页包含 25 部电影,通过翻页参数 ?start=0, 25, 50... 控制页码。
电影信息包含:标题、评分、详情页链接。
4.2 编写 Spider
class DoubanSpider(scrapy.Spider):
name = 'douban'
start_urls = ['https://movie.douban.com/top250']
def parse(self, response):
for movie in response.css('div.item'):
yield {
'title': movie.css('span.title::text').get(),
'score': movie.css('span.rating_num::text').get(),
'link': movie.css('a::attr(href)').get(),
}
next_page = response.css('span.next a::attr(href)').get()
if next_page:
yield response.follow(next_page, callback=self.parse)
运行爬虫即可获取所有 Top250 电影信息。
5 结语
Scrapy 是一个功能完备、设计优雅的爬虫框架,适用于各种规模的数据抓取项目。通过本文的介绍,相信你已经对 Scrapy 的核心原理、模块结构以及使用流程有了较为深入的理解。
在实际开发中,Scrapy 不仅能高效完成爬虫任务,还能通过中间件机制和管道处理打造出灵活、健壮的数据采集系统。掌握它,将极大提升你在数据采集和信息处理方面的能力。


















 1751
1751

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











