原理过程
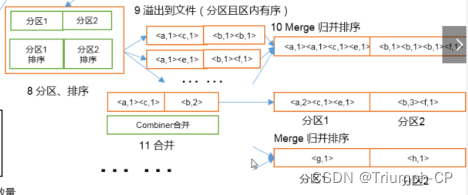
分区
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Partitioner;
public class PhonePartitioner extends Partitioner<Text, IntWritable> {
@Override
public int getPartition(Text text, IntWritable intWritable, int i) {
System.out.println(text.toString());
if ("136".equals(text.toString().substring(0, 3)) || "137".equals(text.toString().substring(0, 3)))
return 0;
else if ("138".equals(text.toString().substring(0, 3)) || "139".equals(text.toString().substring(0, 3)))
return 1;
else return 2;
}
}
合并
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class PhoneCombiner extends Reducer<Text, IntWritable, Text, IntWritable> {
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Reducer<Text, IntWritable, Text, IntWritable>.Context context) throws IOException, InterruptedException {
int count = 0;
for (IntWritable value : values) {
count += value.get();
}
context.write(key, new IntWritable(count));
}
}






















 223
223

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









