







Meta-Transfer Learning for Few-Shot Learning 论文 代码
推荐指数:⭐⭐⭐⭐

- 属于用meta-learning 做 fsl
- 相比MAML,使用更深的网络,但只更新部分参数
- 使用难样本挖掘提升网络精度
1. 动机
已有fsl方法的问题:
- 需要采样很多的任务进行训练。比如MAML采样24k个任务,本文只采样8k个任务。
- 只使用浅层网络,不能利用深度神经网络(DNN)的强大能力。
Q: 利用用DNN解决fsl,DNN很容易过拟合。因为fsl中每类只有几张图片。通过什么方式可以解决过拟合的问题?
A: 论文提出了元迁移学习方法,减少DNN需要学习的参数,将DNN迁移到fsl任务上。
a. 具体迁移参数是什么?针对神经元的SS操作(缩放和平移)。
b. 具体参数能降到多少?针对3 × \times × 3的神经元,可以降到原有DNN参数的 2 9 \frac {2}{9} 92以下。

本文的贡献有两点:
- 元迁移学习策略:将DNN迁移到fsl任务上;(例如,将64分类的DNN网络迁移到5分类的任务上)
- 难任务批训练策略:学习复杂样本,使模型更鲁棒。
2. 方法
(a) DNN训练阶段:在meta-train上预训练一个large scale分类网络DNN:
[
Θ
,
θ
]
[ \Theta, \theta ]
[Θ,θ];
(b) meta-transfer learning阶段: 学习SS参数和fsl分类器参数θ;
(c) meta-test阶段:分类器微调和最终评测。

Q1:FT是什么?
A1:用目标任务数据集样本来微调源域上的预训练网络。
Q2:参数降到 2 9 \frac{2}{9} 92以下是怎么算的?
A1: 1 + C 1 + 9 C \frac {1+C}{1+9C} 1+9C1+C的范围是[ 1 9 \frac{1}{9} 91, 2 10 \frac{2}{10} 102] < 2 9 \frac{2}{9} 92; 或者 scaling参数降到 1 9 \frac{1}{9} 91,shifting参数降到 1 9 C \frac{1}{9C} 9C1。
- 算法流程


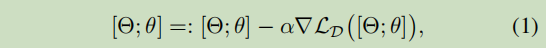
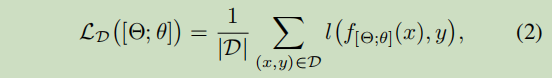
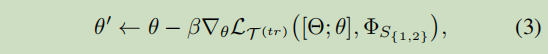
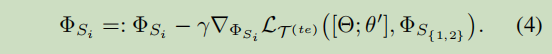
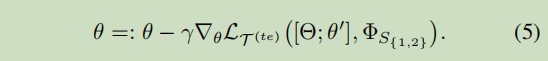
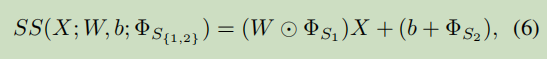
:=和 ← \leftarrow ←分别表示什么?
3. 实验
-
HT meta-batch的作用

在miniImageNet上精度更高,收敛速度没有提升;在CIFAR100上精度更高,收敛速度更快。
问题:在miniImageNet上精度在涨,CIFAR100上精度在降。迭代次数选的是1k。 -
Ablation

-
小样本精度对比实验
对比试验1——miniImageNet数据集

对比试验2——CIFAR100数据集

4. 讨论
Q1: SS的作用是什么?
A1:将DNN迁移到fsl任务上,降低学习参数量,降低过拟合的概率
Q2:fine-tune的参数量是怎么算的?
A2:迁移学习中一般会对整个网络
[
Θ
;
θ
]
[\Theta; \theta]
[Θ;θ]进行FT。参数量就是整个网络的参数量。也可以固定特征提取只对分类器[
θ
\theta
θ]进行FT;或者对特征提取器的高层和分类器
[
Θ
4
;
θ
]
[\Theta4; \theta]
[Θ4;θ]一起FT。
Q3:更新
θ
\theta
θ为什么用
γ
\gamma
γ这个学习率?
A3:因为
θ
\theta
θ是要meta-learner的参数,即网络的分类器部分的好的初始化参数。本文中的base学习和元学习的学习率分别是
β
\beta
β和
γ
\gamma
γ。对应MAML中的分别
α
\alpha
α和
β
\beta
β。对应李宏毅老师的公式推导部分是
η
\eta
η和
ϵ
\epsilon
ϵ。
Q4:
Φ
S
1
\Phi_{S_1}
ΦS1初始化为1,
Φ
S
2
\Phi_{S_2}
ΦS2初始化为0,怎么理解?
A4:默认所有的知识都有用,通过训练找到对所有任务都有泛化能力的
Φ
S
1
\Phi_{S_1}
ΦS1和
Φ
S
2
\Phi_{S_2}
ΦS2。
Q5:为什么每个episode都更新base-learner 参数
θ
\theta
θ?
A5:类似于MAML里的操作,学习一个
θ
\theta
θ的初始化参数。
Q6:为什么能降低过拟合?
A6:通过降低需要学习的参数量。文章也说了,是降低过拟合的概率。[Introduction 倒数第二段第二句]
Q7:base-learner是什么网络?meta-learner是什么网络?
A7:base-learner是
θ
\theta
θ,是一个全连接层;meta-learner是SS参数,是DNN网络的对应部分。
Q8:sample harder tasks online怎么理解?
A8:见Algorithm 2。元训练过程的每一个meta-batch中,1)先采样k个任务batch,从这k个任务里选出k个精度最差的类,作为难类别集合,2)再从这个集合中采样
k
′
k'
k′个任务作为难任务batch。难样本集合是根据每次采样的k个任务得到的,所以说难任务是在线得到的。
Q9:SS作用在
[
Θ
;
θ
]
[\Theta; \theta]
[Θ;θ]还是
[
Θ
]
[\Theta]
[Θ]上?
S
S
[
Θ
;
θ
]
SS [\Theta; \theta]
SS[Θ;θ]表示什么意思?
A9:只作用在
[
Θ
]
[\Theta]
[Θ]上。因为SS的作用是将DNN的特征提取器参数迁移到fsl上,
[
Θ
]
[\Theta]
[Θ]是固定的,而
[
θ
]
[\theta]
[θ]针对不同的fsl任务都是需要学习的。概括来说,就是通过SS来学习fsl任务的特征提取器,用MAML的方式(也就是梯度下降的方式)来学习分类器的参数。
S
S
[
Θ
;
θ
]
SS [\Theta; \theta]
SS[Θ;θ],我理解是SS只迁移
[
Θ
]
[\Theta]
[Θ]的参数。
Q10:每个meta-batch有多少个任务?
A10:k+k’个。
Q11:5.2第六行,“Note that the alternative meta-learning operation to SS is the FT used in MAML”。
A11:MAML里是对浅层网络的特征提取器和分类器都学习一个初始化参数。而直接将MAML的技术用到DNN上,肯定会过拟合。















 4196
4196











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









