







人类在规划构建他们无法轻易测量大小和量化努力的抽象装置时表现出困难。不足为奇的是,软件项目因未处理的复杂性增加而显示出显著的失败历史。如果构建复杂软件需要异常的协调和组织,那么维护它可能是一个更艰巨的挑战。
尽管如此,软件越老,维护起来就越困难。它通常反映了不同代程序员的努力和对比鲜明的观点。当新程序员负责维护旧软件时,通常的做法是简单地紧密包裹难以理解的旧代码片段,隔离软件,并将其变成不可触碰的库。
如此复杂的代码库要求新类别的工具来帮助程序员驯服晦涩的错误。Clang 静态分析器的目的是提供一种自动化方式来分析大型代码库,并帮助人类在编译之前检测其C、C++或Objective-C项目中的各种常见错误。在本章中,我们将涵盖以下主题:
- 经典编译器工具发出的警告与Clang 静态分析器发出的警告之间的区别
- 如何在简单项目中使用Clang 静态分析器
- 如何使用
scan-build工具覆盖大型、现实世界的项目 - 如何用您自己的错误检查器扩展Clang 静态分析器
理解静态分析器的作用
在整体LLVM设计中,如果项目在原始源代码级别(C/C++)上操作,则属于Clang前端,因为在LLVM IR恢复源级信息是具有挑战性的。最有趣的基于Clang的工具之一是Clang 静态分析器,它利用一套检查器来构建详细的错误报告,类似于传统编译器警告在更小规模上所做的工作。每个检查器都测试特定规则违规。
与传统警告一样,静态分析器帮助程序员在开发周期早期找到错误,无需将错误检测推迟到运行时。分析是在解析之后、进一步编译之前完成的。另一方面,该工具可能需要很长时间来处理大型代码库,这是它没有集成在典型编译流程中的一个很好的理由。例如,仅静态分析器可能需要花费数小时来处理整个LLVM源代码并运行其所有检查器。
Clang 静态分析器至少有两个已知的竞争对手:Fortify和Coverity。惠普(HP)提供前者,而Synopsis提供后者。每个工具都有自己的优势和局限性,但只有Clang是开源的,允许我们对其进行黑客攻击并了解其工作原理,这是本章的目标。
经典警告与Clang 静态分析器的比较
Clang 静态分析器中使用的算法具有指数时间复杂度,这意味着,随着被分析的程序单元的增长,处理它所需的时间可能会变得非常大。与许多在实践中有效的指数时间算法一样,它是有界的,这意味着它能够通过使用特定问题的技巧来减少执行时间和内存,尽管这还不足以使其成为多项式时间。
该工具的指数时间性质解释了其最大的局限之一:它只能一次分析单个编译单元,不执行模块间分析或整个程序处理。尽管如此,它是一个非常有能力的工具,因为它依赖于符号执行引擎。
为了说明符号执行引擎如何帮助程序员找到复杂的错误,让我们首先介绍一个大多数编译器可以轻易检测并发出警告的非常简单的错误。请看以下代码:
#include <stdio.h>
void main() {
int i;
printf ("%d", i);
}
在这段代码中,我们使用了一个未初始化的变量,这将导致程序输出取决于我们无法控制或预测的参数,例如程序执行前的内存内容,从而导致意外的程序行为。因此,一个简单的自动检查可以节省调试时的巨大头痛。
如果您熟悉编译器分析技术,您可能已经注意到,我们可以通过使用前向数据流分析,利用并集汇聚操作符来传播每个变量的状态,无论它是初始化的还是未初始化的来实现这种检查。前向数据流分析将变量的状态信息传播到每个基本块,从函数的第一个基本块开始,并将此信息推送到后继基本块。汇聚操作符确定如何合并来自多个前置基本块的信息。并集汇聚操作符将把每个前置基本块的集合并集的结果归因于基本块。
在这种分析中,如果未初始化的定义达到使用,我们应该触发编译器警告。为此,我们的数据流框架将为程序中的每个变量分配以下状态:
- 当我们对它一无所知时,使用⊥符号(未知状态)
- 当我们知道该变量已初始化时,使用初始化标签
- 当我们确定它未初始化时,使用未初始化标签
- 当变量可能已初始化或未初始化时,使用⊤符号(这意味着我们不确定)
以下图表展示了我们对刚刚介绍的简单C程序的数据流分析:

我们看到这些信息很容易在代码行之间传播。当它到达使用i的printf语句时,框架会检查我们对这个变量了解多少,答案是未初始化,提供足够的证据来发出警告。
由于这种数据流分析依赖于多项式时间算法,因此它非常快。
为了看到这种简单分析如何失去精度,让我们考虑一下乔,一个擅长制造难以检测错误的程序员。乔可以很容易地欺骗我们的检测器,并且会巧妙地在单独的程序路径中隐藏实际变量状态。让我们看一个来自乔的例子。
#include <stdio.h>
void my_function(int unknownvalue) {
int schroedinger_integer;
if (unknownvalue)
schroedinger_integer = 5;
printf("hi");
if (!unknownvalue)
printf("%d", schroedinger_integer);
}
现在让我们看看我们的数据流框架如何计算此程序的变量状态:

我们看到,在节点4中,变量首次初始化(以粗体显示)。然而,有两条不同的路径到达节点5:节点3的if语句的真和假分支。在一条路径中,变量schroedinger_integer未初始化,而在另一条路径中它已初始化。汇聚操作符决定如何合并前驱的结果。我们的并集操作符会尝试保留两个数据位,将schroedinger_integer声明为⊤(二者皆有可能)。
当探测器检查使用schroedinger_integer的节点7时,它无法确定代码中是否存在错误,这是因为根据这种数据流分析,schroedinger_integer可能已经也可能尚未初始化。换句话说,它真的处于初始化和未初始化的叠加状态。我们的简单探测器可以尝试警告人们一个值可能在未初始化的情况下被使用,而在这种情况下,它将正确地指出错误。然而,如果乔的代码中最后一次检查的条件改为if (unknownvalue),那么发出警告将是一个误报,因为现在它正在执行schroedinger_integer确实已初始化的路径。
我们探测器中的这种精度损失是因为数据流框架不是路径敏感的,无法精确地模拟每个可能的执行路径中发生的情况。
误报是非常不希望的,因为它们会用不包含实际错误的代码的警告列表困扰程序员,并掩盖那些实际错误的警告。事实上,如果探测器即使生成少量的误报警告,程序员可能会忽略所有警告。
符号执行引擎的力量
当简单的数据流分析不足以提供有关程序的准确信息时,符号执行引擎就有所帮助。它构建了一个可达程序状态的图表,并能够推理程序运行时可能采取的所有可能的代码执行路径。回想一下,当你运行程序进行调试时,你只是在执行一条路径。当你使用像valgrind这样的强大虚拟机来寻找内存泄漏进行程序调试时,它也只是在执行一条路径。
相反,符号执行引擎能够在不实际运行代码的情况下执行它们所有的路径。这是一个非常强大的特性,但要求处理程序的运行时间很长。
就像传统的数据流框架一样,引擎在遍历程序时会为其找到的每个变量分配初始状态,按照它执行每个语句的顺序。区别在于到达控制流改变构造时:引擎将路径分成两条,并为每条路径分别继续分析。这个图被称为可达程序状态图,下面的图表是一个简单的例子,展示了引擎将如何推理乔的代码:
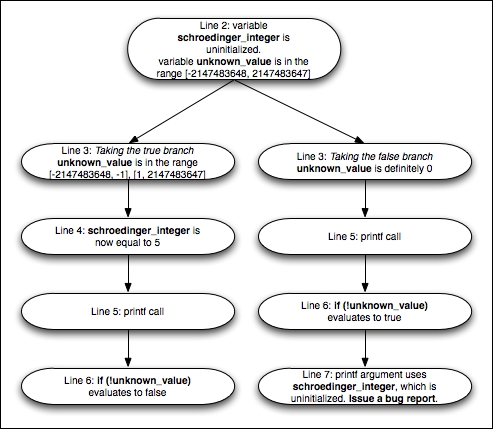
在这个例子中,第6行的第一个if语句将可达状态图分成两条不同的路径:在一条路径中,unknown_value不为零,而在另一条路径中,unknown_value绝对为零。从这一部分开始,引擎对unknown_value进行了重要约束,并将使用它来决定是否采取下一个分支。
通过使用这种策略,符号执行引擎得出结论,图中的左路径永远不会评估schroedinger_integer,尽管在这条路径中它已被定义为5。另一方面,它还得出结论,图中的右路径将评估schroedinger_integer以将其作为printf()参数传递。然而,在这条路径上,该值未初始化。通过使用这个图表,它可以精确地报告这个错误。
让我们将可达程序状态图与显示相同代码的控制流图,即控制流图(CFG)进行比较,并与数据流方程为我们提供的典型推理一起看看。请看下图:
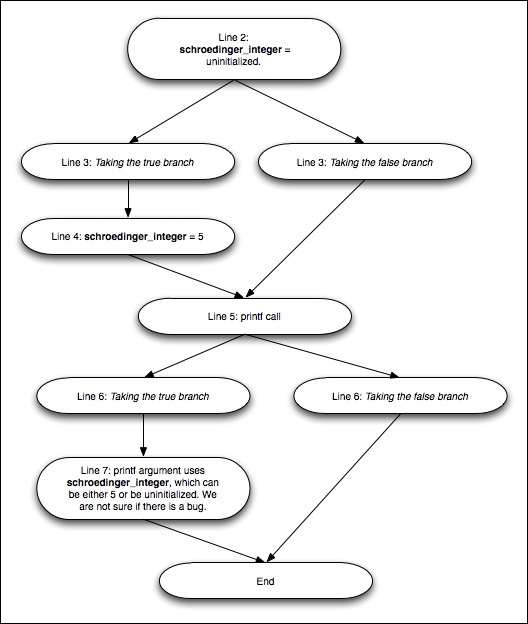
首先,你会注意到的是,控制流图(CFG)可能会分叉以表达控制流的变化,但它也会合并节点以避免可达程序状态图中所见的组合爆炸。当它合并时,数据流分析可以使用并集或交集决策来合并来自不同路径的信息(第5行的节点)。如果它使用并集,我们得出的结论是schroedinger_integer既未初始化又等于5,正如我们上一个例子中的情况。如果它使用交集,我们最终对schroedinger_integer一无所知(未知状态)。
合并数据的必要性是典型数据流分析中的一个限制,这是符号执行引擎所没有的。这使得结果更加精确,与你通过使用多个输入测试程序所得到的结果相当,但代价是增加了运行时间和内存消耗。
测试静态分析器
在这一部分中,我们将探讨如何在实践中使用Clang静态分析器。
使用驱动程序与使用编译器
在测试静态分析器之前,你应该始终记住,命令行clang -cc1直接指的是编译器,而使用命令行clang将触发编译器驱动程序。驱动程序负责协调在编译过程中涉及的所有其他LLVM程序的执行,但它也负责提供关于你的系统的适当参数。
尽管有些开发者更喜欢直接使用编译器,有时它可能无法定位系统头文件或只有Clang驱动程序知道的其他配置参数。另一方面,编译器可能会提供专门的开发选项,让我们可以调试它并了解内部发生的情况。让我们看看如何使用它们来检查单个源代码文件。
| 编译器 | clang –cc1 –analyze –analyzer-checker = `` |
|---|---|
| 驱动程序 | clang --analyze -Xanalyzer -analyzer-checker= `` |
我们使用标签<file>来表示你想要分析的源代码文件,使用标签<package>来让你选择特定的头文件集合。
当使用驱动程序时,注意--analyze标志触发静态分析器。然而,-Xanalyzer标志将下一个标志直接路由到编译器,允许你传递特定的标志。由于驱动程序是一个中介,因此在我们的例子中我们将直接使用编译器。此外,在我们简单的例子中,直接使用编译器应该足够了。如果你觉得需要驱动程序以官方方式使用检查器,请记住使用驱动程序,并在我们传递给编译器的每个标志之前使用-Xanalyzer选项。
了解可用的检查器
检查器是静态分析器可以在代码中执行的单个分析单元。每种分析都寻找特定类型的错误。静态分析器允许你选择适合你需要的任何子集的检查器,或者你可以启用它们所有。
如果你尚未安装Clang,请参阅第1章,构建和安装LLVM,以获取安装说明。要获取已安装检查器的列表,请运行以下命令:
$ clang -cc1 -analyzer-checker-help
它将打印出一长串已安装检查器的列表,显示你直接使用Clang所获得的所有分析可能性。现在让我们检查-analyzer-checker-help命令的输出:
OVERVIEW: Clang Static Analyzer Checkers List
USAGE: -analyzer-checker <CHECKER or PACKAGE,...>
CHECKERS:
alpha.core.BoolAssignment Warn about assigning non-{0,1} values to Boolean variables
检查器的名称遵循规范形式<package>.<subpackage>.<checker>,为用户提供了一种仅运行特定相关检查器集的简便方法。
在下表中,我们展示了一些最重要的包,以及每个包中的一些检查器示例。
| 包名 | 内容 | 示例 |
|---|---|---|
alpha | 目前正在开发中的检查器 | alpha.core.BoolAssignment、alpha.security.MallocOverflow和alpha.unix.cstring.NotNullTerminated |
core | 适用于通用环境的基本检查器 | core.NullDereference、core.DivideZero和core.StackAddressEscape |
cplusplus | 针对C++内存分配的单一检查器(其他目前在alpha中) | cplusplus.NewDelete |
debug | 输出静态分析器调试信息的检查器 | debug.DumpCFG、debug.DumpDominators和debug.ViewExplodedGraph |
llvm | 检查代码是否符合LLVM编码标准的单一检查器 | llvm.Conventions |
osx | 针对为Mac OS X开发的程序的特定检查器 | osx.API、osx.cocoa.ClassRelease、osx.cocoa.NonNilReturnValue和osx.coreFoundation.CFError |
security | 检查引入安全漏洞的代码的检查器 | security.FloatLoopCounter、security.insecureAPI.UncheckedReturn、security.insecureAPI.gets和security.insecureAPI.strcpy |
unix | 针对为UNIX系统开发的程序的特定检查器 | unix.API、unix.Malloc、unix.MallocSizeof和unix.MismatchedDeallocator |
让我们运行乔的代码,旨在愚弄大多数编译器使用的简单分析。首先,我们尝试经典的警告方法。为此,我们只需运行Clang驱动程序,并要求它不继续编译,只进行语法检查:
$ clang -fsyntax-only joe.c
syntax-only标志旨在打印警告和检查语法错误,未能检测出任何问题。现在是时候测试符号执行如何处理这个问题了:
$ clang -cc1 -analyze -analyzer-checker=core joe.c
如果前面的命令行要求你指定头文件位置,请使用以下驱动程序命令:
$ clang --analyze –Xanalyzer –analyzer-checker=core joe.c
./joe.c:10:5: warning: Function call argument is an uninitialized value
printf("%d", schroedinger_integer);
^~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
1 warning generated.
一举命中!请记住,analyzer-checker标志期望完全限定名的检查器,或者整个检查器包的名称。我们选择使用整个核心检查器包,但我们也可以仅使用特定的检查器core.CallAndMessage,它检查函数调用的参数。
注意,所有静态分析器命令总是以clang -cc1 -analyzer开头;因此,如果你想知道分析器提供的所有命令,你可以发出以下命令:
$ clang -cc1 -help | grep analyzer
在Xcode IDE中使用静态分析器
如果你使用苹果的Xcode IDE,你可以在其中使用静态分析器。首先,你需要打开一个项目,然后在**产品(Product)菜单中选择分析(Analyze)**菜单项。你会发现Clang静态分析器提供了此错误发生的确切路径,使得IDE能够突出显示给程序员,如下截图所示:
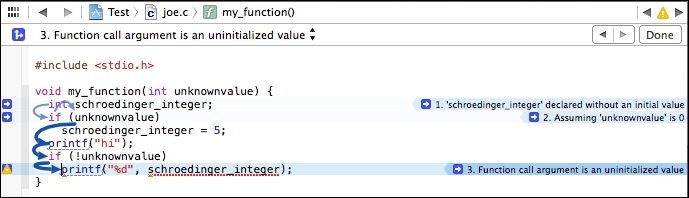
分析器能够使用plist格式导出信息,然后由Xcode解释并以用户友好的方式显示。
生成HTML格式的图形报告
静态分析器还能够导出一个HTML文件,该文件将以与Xcode相同的方式图形化地指出代码中的程序路径,这些路径可能会触发危险行为。我们还使用**-o**参数和一个文件夹名称,指示报告将存储在哪里。例如,查看以下命令行:
$ clang -cc1 -analyze -analyzer-checker=core joe.c -o report
或者,你可以使用驱动程序如下:
$ clang --analyze –Xanalyzer –analyzer-checker=core joe.c –o report
使用这个命令行,分析器将处理joe.c并生成一个与Xcode中看到的类似的报告,并将HTML文件放在report文件夹中。命令完成后,检查该文件夹并打开HTML文件以查看错误报告。你应该会看到一个与以下屏幕截图中显示的类似的报告:

处理大型项目
如果你想让静态分析器检查一个大型项目,你可能不愿意编写一个Makefile或一个bash脚本来为项目的每个源文件调用分析器。静态分析器附带了一个方便的工具,称为scan-build。
Scan-build通过替换你的CC或CXX环境变量(定义了你的C/C++编译器命令)来工作,因此干预了项目的常规构建过程。它在编译之前分析每个编译的文件,然后完成编译,以允许构建过程或脚本继续按预期工作。最后,它生成你可以在浏览器中查看的HTML报告。基本的命令行结构非常简单:
$ scan-build <你的构建命令>
你可以在scan-build之后运行任何构建命令,比如make。例如,为了构建乔的程序,我们不需要Makefile,但我们可以直接提供编译命令:
$ scan-build gcc -c joe.c -o joe.o
完成后,你可以运行scan-view来查看错误报告:
$ scan-view <scan-build给出的输出目录>
scan-build的最后一行给出了运行scan-view所需的参数。它指的是一个临时文件夹,保存了所有生成的报告。你应该会看到一个格式良好的网站,其中包含你每个源文件的错误报告,如下屏幕截图所示:
真实世界的例子 - 在Apache中寻找错误
在这个例子中,我们将探索在一个大型项目中检查错误有多容易。为此,请访问 http://httpd.apache.org/download.cgi 并获取最新Apache HTTP服务器的源代码压缩包。在本文撰写时,它是版本2.4.9。在我们的例子中,我们将通过控制台下载它,并在当前文件夹中解压文件:
$ wget
$ tar -xjvf httpd-2.4.9.tar.bz2
为了检查这个源代码库,我们将依赖scan-build。为此,我们需要重现生成构建脚本的步骤。注意,你确实需要所有必要的依赖项来编译Apache项目。在确认你确实拥有所有依赖项后,使用以下命令序列:
$ mkdir obj
$ cd obj
$ scan-build ../httpd-2.4.9/configure -prefix=$(pwd)/../install
我们使用了prefix参数来指定此项目的新安装路径,以避免在机器上需要管理员权限。然而,如果你不打算实际安装Apache,只要你不运行make install,就不需要提供任何额外参数。在我们的例子中,我们定义了我们的安装路径为一个名为install的文件夹,该文件夹将在我们下载压缩源代码的同一目录中创建。注意,我们还在这个命令前加了scan-build,这将覆盖CC和CXX环境变量。
在configure脚本创建所有Makefile后,是时候启动实际的构建过程了。但是,我们用scan-build拦截了make命令:
$ scan-build make
由于Apache代码非常庞大,我们花了几分钟完成分析,并发现了82个错误。以下是一个scan-view报告的例子:
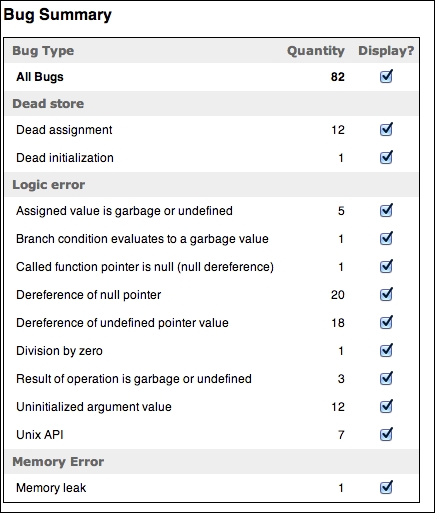
在臭名昭著的心脏出血(Heartbleed)漏洞影响了所有OpenSSL实现,并且这个问题获得了广泛关注之后,有趣的是,静态分析器仍然在Apache SSL实现文件modules/ssl/ssl_util.c和modules/ssl/ssl_engine_config.c中找到了六个可能的漏洞。请注意,这些情况可能指的是实际上从未执行的路径,并且可能不是真正的漏洞,因为静态分析器在有限的范围内工作,以在可接受的时间框架内完成分析。因此,我们并不声称这些是真正的漏洞。我们在这里展示了一个例子,即被赋予的值是垃圾或未定义的:
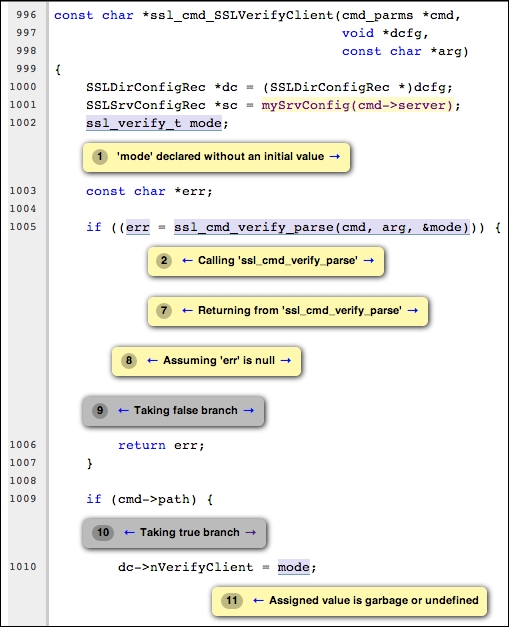
在这个例子中,我们看到静态分析器向我们展示了一个执行路径,该路径以将未定义的值赋给dc->nVerifyClient结束。这条路径的一部分经过了对ssl_cmd_verify_parse()函数的调用,展示了分析器检查同一编译模块内复杂的过程间路径的能力。在这个辅助函数中,静态分析器显示了一条mode没有被赋予任何值,因此保持未初始化的路径。
注意
之所以这可能不是一个真正的错误,是因为ssl_cmd_verify_parse()中的代码可能正确地处理了在这个程序中实际发生的所有输入cmd_parms(注意这种依赖上下文的情况),在所有情况下都正确初始化了mode。scan-build发现的是,这个模块在孤立的情况下可能会导致这个错误路径,但我们没有证据表明这个模块的用户使用了有问题的输入。静态分析器没有足够的能力分析这个模块在整个项目的上下文中,因为这样的分析需要不切实际的时间才能完成(记住算法的指数复杂度)。
虽然这条路径有11个步骤,但我们在Apache中找到的最长路径有42个步骤。这条路径发生在modules/generators/mod_cgid.c模块中,并违反了标准的C API调用:它用空指针参数调用strlen()函数。
如果你想详细了解所有这些报告,不要犹豫,自己运行这些命令。
使用你自己的检查器扩展静态分析器
由于其设计,我们可以轻松地使用自定义检查器扩展静态分析器。请记住,静态分析器的好坏取决于其检查器,如果你想分析任何代码是否以意想不到的方式使用了你的API,你需要学习如何将这种特定领域的知识嵌入到Clang静态分析器中。
熟悉项目架构
Clang静态分析器的源代码位于llvm/tools/clang。包含文件位于include/clang/StaticAnalyzer,源代码可以在lib/StaticAnalyzer找到。如果你查看文件夹内容,会发现项目分为三个不同的子文件夹:Checkers、Core和Frontend。
核心的任务是在源代码级别模拟程序执行,并使用访问者模式,在每个程序点(在重要声明之前或之后)调用注册的检查器,以强制执行给定的不变量。例如,如果你的检查器确保同一分配的内存区域不会被释放两次,它会观察对malloc()和free()的调用,在检测到双重释放时生成错误报告。
符号引擎不能使用与程序运行时看到的确切程序值来模拟程序。如果你要求用户输入一个整数值,你肯定知道,在给定的运行中,这个值是5,例如。符号引擎的强大之处在于推理程序的每个可能结果中发生的事情,为了实现这个崇高目标,它使用符号(SVals)而不是具体值工作。一个符号可能对应于整数范围内的任何数字、任何浮点数,甚至是完全未知的值。它对值的了解越多,它就越强大。
理解项目实现的三个重要数据结构是ProgramState、ProgramPoint和ExplodedGraph。第一个表示当前执行上下文与当前状态的关系。例如,在分析乔的代码时,它会注明一个给定变量的值为5。第二个代表程序流程中的一个特定点,例如在一个整数变量赋值为5之后的点。最后一个代表整个可达程序状态的图。此外,该图的节点由ProgramState和ProgramPoint的元组表示,这意味着每个程序点都有一个特定的状态与之相关。例如,将整数变量赋值为5之后的点有一个将该变量与数字5联系起来的状态。
正如本章开头所指出的,ExplodedGraph,换句话说,可达状态图,相对于经典的CFG来说是一个重大扩展。注意,一个小的CFG包含两个连续但非嵌套的if,在可达状态图的表示中,会爆炸为四个不同的路径——组合扩展。为了节省空间,这个图被折叠,这意味着如果你创建了一个表示与另一个节点中相同的程序点和状态的节点,它不会分配一个新节点,而是重用这个现有节点,可能构建循环。为了实现这种行为,ExplodedNode继承了LLVM库的超类llvm::FoldingSetNode。由于折叠在编译器的中间和后端广泛使用以表示程序,因此LLVM库已经包含了这些情况的通用类。
静态分析器的整体设计可以分为以下几个部分:引擎,它遵循模拟路径并管理其他组件;状态管理器,负责ProgramState对象;约束管理器,致力于推导出由遵循给定程序路径引起的ProgramState上的约束;以及存储管理器,负责程序存储模型。
分析器的另一个重要方面是如何在沿着每条路径模拟程序执行时模拟内存行为。在像C和C++这样的语言中,这是相当具有挑战性的,因为它们为程序员提供了许多访问同一内存片段的方法,引入了别名。
分析器实现了一种由Xu等人在一篇论文中描述的区域内存模型(请参阅本章末尾的参考文献),甚至能够区分数组的每个元素的状态。Xu等人提出了一种内存区域的层次结构,例如,数组元素是数组的子区域,数组是栈的子区域。C中的每个lvalue,或者换句话说,每个变量或解引用的引用,都有一个对应的区域,用于模拟它们正在处理的内存片段。另一方面,每个内存区域的内容是用绑定来建模的。每个绑定将一个符号值与一个内存区域关联起来。我们知道这是太多信息要吸收,所以让我们以最好的方式消化它——通过编写代码。
编写你自己的检查器
假设你正在开发一个特定的嵌入式软件,该软件控制着一个核反应堆,并且依赖于一个拥有两个基本调用的API:turnReactorOn()(启动反应堆)和SCRAM()(关闭反应堆)。一个核反应堆包含燃料,反应就在其中发生,以及控制棒,这些控制棒包含吸收中子的物质,用以减缓反应速度,确保反应堆属于电力厂范畴,而不是核弹。
你的客户提醒你,两次调用SCRAM()可能会卡住控制棒,而两次调用turnReactorOn()会导致反应失控。这是一个有着严格使用规则的API,你的任务是在软件投入生产前审查大量代码,确保它不违反以下规则:
- 没有任何代码路径可以在没有间隔的情况下多于一次调用
SCRAM() - 没有任何代码路径可以在没有间隔的情况下多于一次调用
turnReactorOn()
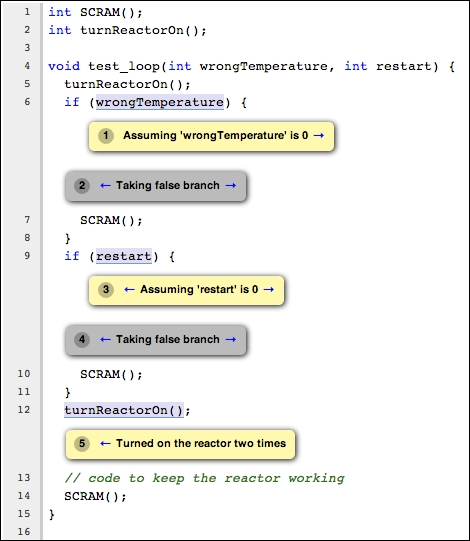
作为一个例子,考虑以下代码:
int SCRAM();
int turnReactorOn();
void test_loop(int wrongTemperature, int restart) {
turnReactorOn();
if (wrongTemperature) {
SCRAM();
}
if (restart) {
SCRAM();
}
turnReactorOn();
// code to keep the reactor working
SCRAM();
}
如果wrongTemperature和restart两者都不为零,那么这段代码就违反了API规则,因为这会导致连续两次调用SCRAM()而中间没有任何turnReactorOn()的调用。同样,如果这两个参数都是零,那么代码将会连续两次调用turnReactorOn()而中间没有任何SCRAM()的调用。
用自定义检查器解决问题
你可以尝试直观地检查代码,这非常繁琐且容易出错,或者使用像Clang静态分析器这样的工具。问题在于,它不理解核电站API。我们将通过实现一个特殊的检查器来克服这一点。
我们的第一步是建立关于我们想要在不同程序状态间传播的信息的状态模型概念。在这个问题中,我们关心的是反应堆是开启还是关闭状态。我们可能不知道反应堆是开启还是关闭的;因此,我们的状态模型包含三种可能的状态:未知、开启和关闭。
现在我们对于检查器如何处理状态有了一个不错的概念。
编写状态类
让我们将这些概念付诸实践。我们将基于SimpleStreamChecker.cpp编写代码,这是Clang树中的一个示例检查器。
在lib/StaticAnalyzer/Checkers中,我们应该创建一个新文件ReactorChecker.cpp,并开始编写我们自己的类来表示我们感兴趣的跟踪状态:
#include "ClangSACheckers.h"
#include "clang/StaticAnalyzer/Core/BugReporter/BugType.h"
#include "clang/StaticAnalyzer/Core/Checker.h"
#include "clang/StaticAnalyzer/Core/PathSensitive/CallEvent.h"
#include "clang/StaticAnalyzer/Core/PathSensitive/CheckerContext.h"
using namespace clang;
using namespace ento;
class ReactorState {
private:
enum Kind {On, Off} K;
public:
ReactorState(unsigned InK): K((Kind) InK) {}
bool isOn() const { return K == On; }
bool isOff() const { return K == Off; }
static unsigned getOn() { return (unsigned) On; }
static unsigned getOff() { return (unsigned) Off; }
bool operator==(const ReactorState &X) const {
return K == X.K;
}
void Profile(llvm::FoldingSetNodeID &ID) const {
ID.AddInteger(K);
}
};
我们的类的数据部分仅限于一个Kind实例。注意,ProgramState类将管理我们正在编写的状态信息。
理解ProgramState的不可变性
关于ProgramState的一个有趣观察是,它被设计为不可变的。一旦建立,它就不应该改变:它代表了在给定执行路径上给定程序点计算出的状态。与处理CFG(控制流图)的数据流分析不同,在这种情况下,我们处理的是可达程序状态图,对于每一对不同的程序点和状态,它都有一个不同的节点。这样,如果程序循环,引擎将创建一个完全新的路径,记录这次新迭代的相关信息。相反,在数据流分析中,循环会导致循环体的状态使用新信息进行更新,直到达到一个固定点。
然而,如前所强调的,一旦符号引擎到达一个表示给定循环体的相同程序点且状态相同的节点,它就会得出结论,在这条路径上没有新信息要处理,并重用该节点而不是创建一个新的。另一方面,如果你的循环体不断地用新信息更新状态,你很快就会遇到符号引擎的一个限制:在模拟预定义的迭代次数后,它会放弃这条路径,这是在启动工具时可以配置的数字。
剖析代码
由于状态一旦创建就是不可变的,我们的ReactorState类不需要设值器,也不需要可以改变其状态的类成员函数,但我们确实需要构造函数。这就是ReactorState(unsigned InK)构造函数的目的,它接收一个整数作为输入,编码当前的反应堆状态。
最后,Profile函数是ExplodedNode作为FoldingSetNode子类的结果。所有子类都必须提供此类方法,以帮助LLVM折叠跟踪节点的状态,并确定两个节点是否相等(在这种情况下,它们会被折叠)。因此,我们的Profile函数解释了K,一个数字,赋予了我们的状态。
你可以使用FoldingSetNodeID成员函数中任何以Add开头的函数来通知唯一的位,以标识此对象实例(见llvm/ADT/FoldingSet.h)。在我们的案例中,我们使用了AddInteger()。
定义Checker子类
现在是时候声明我们的Checker子类了:
class ReactorChecker : public Checker<check::PostCall> {
mutable IdentifierInfo *IIturnReactorOn, *IISCRAM;
OwningPtr<BugType> DoubleSCRAMBugType;
OwningPtr<BugType> DoubleONBugType;
void initIdentifierInfo(ASTContext &Ctx) const;
void reportDoubleSCRAM(const CallEvent &Call,
CheckerContext &C) const;
void reportDoubleON(const CallEvent &Call,
CheckerContext &C) const;
public:
ReactorChecker();
/// Process turnReactorOn and SCRAM
void checkPostCall(const CallEvent &Call, CheckerContext &C) const;
};
注意
Clang版本通知 - 从Clang 3.5开始,OwningPtr<>模板已被废弃,转而使用标准C++的std::unique_ptr<>模板。这两个模板都提供了智能指针的实现。
我们类的前几行指定我们正在使用一个Checker的子类,并带有一个模板参数。对于这个类,你可以使用多个模板参数,它们表示你的检查器感兴趣的程序点。技术上讲,模板参数被用来派生一个自定义的Checker类,它是作为参数指定的所有类的子类。这意味着,在我们的案例中,我们的检查器将从基类继承PostCall。这种继承用于实现访问者模式,只会为我们感兴趣的对象调用我们,因此,我们的类必须实现成员函数checkPostCall。
你可能有兴趣注册你的检查器,以访问多种类型的程序点(查看CheckerDocumentation.cpp)。在我们的案例中,我们对访问调用后的程序点感兴趣,因为我们想在调用核电站API函数后记录状态变化。
这些成员函数使用const关键字,尊重依赖检查器无状态的设计。然而,我们确实想要缓存检索代表符号turnReactorOn()和SCRAM()的IdentifierInfo对象的结果。因此,我们使用mutable关键字,该关键字创建用于绕过const限制。
注意
谨慎使用mutable关键字。我们没有损害检查器设计,因为我们只是为了在第二次调用我们的检查器后更快地计算而缓存结果,但从概念上讲,我们的检查器仍然是无状态的。mutable关键字应该只用于互斥锁或此类缓存场景。
我们还希望通知Clang基础设施,我们正在处理一种新类型的错误。为此,我们必须持有新的BugType实例,每报告一种新错误就持有一个:当程序员连续两次调用SCRAM()时发生的错误,以及当程序员连续两次调用turnReactorOn()时发生的错误。我们还使用LLVM的OwningPtr类包装我们的对象,这只是自动指针的一种实现,用于在我们的ReactorChecker对象被销毁时自动释放我们的对象。
你应该将我们刚刚编写的两个类ReactorState和ReactorChecker包装在一个匿名命名空间中。这样可以避免我们的链接器导出这两个数据结构,我们知道它们只会在本地使用。
编写注册宏
在我们深入类实现之前,我们必须调用一个宏,以扩展分析引擎使用的ProgramState实例,包含我们自定义的状态:
REGISTER_MAP_WITH_PROGRAMSTATE(RS, int, ReactorState)
注意,这个宏末尾不使用分号。这将新的映射与每个ProgramState实例关联起来。第一个参数可以是你稍后将用来引用这个数据的任何名称,第二个参数是映射键的类型,第三个参数是我们将存储的对象类型(在我们的案例中,是我们的ReactorState类)。
检查器通常使用映射来存储它们的状态,因为通常需要将新状态与特定资源关联,例如,我们从本章开始的检测器中的每个变量的状态,初始化或未初始化。在这种情况下,映射的键将是一个变量名称,存储的值将是一个模型化初始化或未初始化状态的自定义类。要了解更多将信息注册到程序状态的方式,请查看CheckerContext.h中的宏定义。
注意,我们实际上不需要映射,因为我们每个程序点只会存储一个状态。因此,我们将始终使用键1来访问我们的映射。
实现Checker子类
我们的检查器类构造函数如下实现:
ReactorChecker::ReactorChecker() : IIturnReactorOn(0), IISCRAM(0) {
// 初始化错误类型。
DoubleSCRAMBugType.reset(
new BugType("Double SCRAM","Nuclear Reactor API Error"));
DoubleONBugType.reset(new BugType("Double ON",
"Nuclear Reactor API Error"));
}
注意
Clang版本通知 - 从Clang 3.5开始,我们的BugType构造函数调用需要改为BugType(this, "Double SCRAM", "Nuclear Reactor API Error")和BugType(this, "Double ON", "Nuclear Reactor API Error"),添加this关键字作为第一个参数。
我们的构造函数通过使用OwningPtr的reset()成员函数实例化新的BugType对象,并给出我们新错误类型的描述。我们还初始化了IdentifierInfo指针。接下来,定义我们的帮助函数来缓存这些指针的结果:
void ReactorChecker::initIdentifierInfo(ASTContext &Ctx) const {
if (IIturnReactorOn)
return;
IIturnReactorOn = &Ctx.Idents.get("turnReactorOn");
IISCRAM = &Ctx.Idents.get("SCRAM");
}
ASTContext对象保存了包含用户程序中使用的类型和声明的特定AST节点,我们可以使用它来找到我们感兴趣监控的函数的确切标识符。现在,我们实现访问者模式函数checkPostCall。记住,它是一个const函数,不应该修改检查器状态:
void ReactorChecker::checkPostCall(const CallEvent &Call,
CheckerContext &C) const {
initIdentifierInfo(C.getASTContext());
if (!Call.isGlobalCFunction())
return;
if (Call.getCalleeIdentifier() == IIturnReactorOn) {
ProgramStateRef State = C.getState();
const ReactorState *S = State->get<RS>(1);
if (S && S->isOn()) {
reportDoubleON(Call, C);
return;
}
State = State->set<RS>(1, ReactorState::getOn());
C.addTransition(State);
return;
}
if (Call.getCalleeIdentifier() == IISCRAM) {
ProgramStateRef State = C.getState();
const ReactorState *S = State->get<RS>(1);
if (S && S->isOff()) {
reportDoubleSCRAM(Call, C);
return;
}
State = State->set<RS>(1, ReactorState::getOff());
C.addTransition(State);
return;
}
}
第一个参数,类型为CallEvent,保存了程序在此程序点之前刚刚调用的确切函数的信息(参见CallEvent.h),因为我们注册了一个调用后的访问者。第二个参数,类型为CheckerContext,是关于此程序点当前状态的唯一信息来源,因为我们的检查器被强制无状态。我们用它来检索ASTContext并初始化我们的IdentifierInfo对象,这些对象是检查我们正在监视的函数所必需的。我们询问CallEvent对象,检查它是否是对turnReactorOn()函数的调用。如果是,我们需要处理状态转换到开启状态。
在此之前,我们首先检查状态,以确定它是否已经开启,如果是这样,那么我们就有一个错误。注意,在State->get<RS>(1)语句中,RS仅仅是我们在程序状态中注册新特征时使用的名称,而1是一个固定的整数,用于始终访问映射的位置。虽然在这种情况下我们实际上不需要映射,但通过使用映射,如果你愿意,你将能够轻松地扩展我们的检查器来监控更复杂的状态。
我们以const指针的形式恢复我们存储的状态,因为我们正在处理到达此程序点的信息,这些信息是不可变的。首先需要检查它是否是空引用,这代表我们不知道反应堆是开启还是关闭的情况。如果它是非空的,我们检查它是否处于开启状态,如果是这样,我们放弃进一步分析并报告错误。在另一种情况下,我们使用ProgramStateRef的set成员函数创建一个新状态,并将这个新状态提供给addTransition()成员函数,该函数将记录信息以在ExplodedGraph中创建一个新的边。只有在状态实际改变时才会创建边。我们采用类似的逻辑来处理SCRAM情况。
我们将错误报告成员函数呈现如下:
void ReactorChecker::reportDoubleON(const CallEvent &Call,
CheckerContext &C) const {
ExplodedNode *ErrNode = C.generateSink();
if (!ErrNode)
return;
BugReport *R = new BugReport(*DoubleONBugType,
"反应堆被开启两次", ErrNode);
R->addRange(Call.getSourceRange());
C.emitReport(R);
}
void ReactorChecker::reportDoubleSCRAM(const CallEvent &Call,
CheckerContext &C) const {
ExplodedNode *ErrNode = C.generateSink();
if (!ErrNode)
return;
BugReport *R = new BugReport(*DoubleSCRAMBugType,
"SCRAM程序被调用两次", ErrNode);
R->addRange(Call.getSourceRange());
C.emitReport(R);
}
我们的第一个动作是生成一个汇点节点,这在可达程序状态图中意味着我们在这条路径上遇到了一个关键错误,并且我们不想继续分析这条路径。接下来的几行创建了一个BugReport对象,指明我们找到了一种特定类型的新错误DoubleOnBugType,我们可以自由添加描述并提供我们刚刚构建的错误节点。我们还使用addRange()成员函数,它将突出显示源代码中发生错误的位置,并向用户显示。
添加注册代码
为了让静态分析器工具识别我们的新检查器,我们需要在源代码中定义一个注册函数,然后在TableGen文件中添加我们的检查器的描述。注册函数如下所示:
void ento::registerReactorChecker(CheckerManager &mgr) {
mgr.registerChecker<ReactorChecker>();
}
TableGen文件有一个检查器表。它位于相对于Clang源文件夹的lib/StaticAnalyzer/Checkers/Checkers.td。在编辑此文件之前,我们需要为我们的检查器选择一个包。我们将把它放入alpha.powerplant。由于这个包还不存在,我们将创建它。打开Checkers.td并在所有现有包定义之后添加一个新定义:
def PowerPlantAlpha : Package<"powerplant">, InPackage<Alpha>;
接下来,添加我们新编写的检查器:
let ParentPackage = PowerPlantAlpha in {
def ReactorChecker : Checker<"ReactorChecker">,
HelpText<"检查对核电站API的误用">,
DescFile<"ReactorChecker.cpp">;
} // 结束 "alpha.powerplant"
如果你使用CMake来构建Clang,你应该将你的新源文件添加到lib/StaticAnalyzer/Checkers/CMakeLists.txt。如果你使用GNU自动工具配置脚本来构建Clang,你不需要修改任何其他文件,因为LLVM Makefile将扫描Checkers文件夹中的新源代码文件,并将它们链接到静态分析器检查器库中。
构建和测试
转到你构建LLVM和Clang的文件夹,并运行make。构建系统现在会检测到你的新代码,构建它,并将其链接到Clang静态分析器。完成构建后,命令clang -cc1 -analyzer-checker-help应该将我们的新检查器列为有效选项。
我们检查器的测试用例是managereactor.c,如下所示(与前面介绍的相同):
int SCRAM();
int turnReactorOn();
void test_loop(int wrongTemperature, int restart) {
turnReactorOn();
if (wrongTemperature) {
SCRAM();
}
if (restart) {
SCRAM();
}
turnReactorOn();
// 代码保持反应堆运行
SCRAM();
}
要使用我们的新检查器分析它,我们使用以下命令:
$ clang --analyze -Xanalyzer -analyzer-checker=alpha.powerplant managereactor.c
检查器将显示它能找到的错误路径并退出。如果你要求HTML报告,你将看到一个类似于以下屏幕截图中显示的错误报告:
你现在已经成功完成了一个任务:开发了一个程序,用于自动检查特定API规则的违规情况,并具有路径敏感性。如果你愿意,可以查看其他检查器的实现,以了解在更复杂场景中工作的更多信息,或者查看下一节中的资源以获取更多信息。
更多资源
你可以查看以下资源,了解更多项目和其他信息:
- http://clang-analyzer.llvm.org:Clang静态分析器项目页面。
- http://clang-analyzer.llvm.org/checker_dev_manual.html:一个对那些想要开发新检查器的人非常有用的手册。
- http://lcs.ios.ac.cn/~xzx/memmodel.pdf:由Zhongxing Xu、Ted Kremenek和Jian Zhang撰写的论文《C语言静态分析的内存模型》(A Memory Model for Static Analysis of C)。它详细介绍了分析器核心中实现的内存模型的理论方面。
- http://clang.llvm.org/doxygen/annotated.html:Clang doxygen文档。
- https://www.youtube.com/watch?v=kdxlsP5QVPw:Anna Zaks和Jordan Rose,静态分析器开发者,在2012年LLVM开发者大会上进行的关于如何快速构建检查器的讲座。
总结
在本章中,我们探讨了Clang静态分析器与仅在编译器前端运行的简单错误检测工具的不同之处。我们提供了一些示例,说明了静态分析器更加准确,并解释了准确性和计算时间之间的权衡,以及指数时间静态分析器算法不可能集成到常规编译器流水线中,因为它需要完成分析的时间。我们还介绍了如何使用命令行界面在简单项目上运行静态分析器,以及一个名为scan-build的辅助工具来分析大型项目。本章最后,我们介绍了如何用你自己的路径敏感错误检查器扩展静态分析器。
在下一章中,我们将介绍建立在LibTooling基础设施之上的Clang工具,这些工具简化了构建代码重构实用程序的过程。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









